3. Интервальный вариационный ряд.
Гистограмма относительных частот
На предыдущем уроке по математической статистике (Занятие 1) мы разобрали дискретный вариационный ряд (Занятие 2), и сейчас на очереди интервальный. Его понятие, графическое представление (гистограмма и эмпирическая функция распределения), а также рациональные методы вычислений, как ручные, так и программные. В том числе будут рассмотрены задачи с достаточно большим количеством (100-200) вариант – что делать в таких случаях, как обработать большой массив данных.
Предпосылкой построения интервального вариационного ряда (ИВР) является тот факт, что исследуемая величина принимает слишком много различных значений. Зачастую ИВР появляется в результате измерения непрерывной характеристики изучаемых объектов. Типично – это время, масса, размеры и другие физические характеристики. Подходящие примеры встретились в первой же статье по матстату, вспоминаем Константина, который замерял время на лабораторной работе и Фёдора, который взвешивал помидоры.
Для изучения интервального вариационного ряда затруднительно либо невозможно применить тот же подход, что и для дискретного ряда. Это связано с тем, что ВСЕ варианты многих ИВР различны. И даже если встречаются совпадающие значения, например, 50 грамм и 50 грамм, то связано это с округлением, ибо полученные значения всё равно отличаются хоть какими-то микрограммами.
Поэтому для исследования ИВР используется другой подход, а именно, определяется интервал, в пределах которого варьируются значения, затем данный интервал делится на частичные интервалы, и по каждому интервалу подсчитываются частоты – количество вариант, которые в него попали.
Разберём всю кухню на конкретной задаче, и чтобы как-то разнообразить физику, я приведу пример с экономическим содержанием, кои десятками предлагают студентам экономических отделений. Деньги, строго говоря, дискретны, но если надо, непрерывны :), и по причине слишком большого разброса цен, для них целесообразно строить интервальный ряд:
По результатам исследования цены некоторого товара в различных торговых точках города, получены следующие данные (в некоторых денежных единицах): 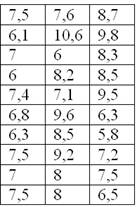
Требуется составить вариационный ряд распределения, построить гистограмму частот, гистограмму и полигон относительных частот + бонус – эмпирическую функцию распределения.
Такое обывательское исследование проводит каждый из нас, начиная с анализа цены на пакет молока вот это дожил в нескольких магазинах, и заканчивая ценами на недвижимость по гораздо бОльшей выборке. Что называется, не какие-то там унылые сантиметры.
Поэтому представьте свой любимый товар / услугу и наслаждайтесь решением🙂
Очевидно, что перед нами выборочная совокупность объемом 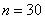 наблюдений (таблица 10*3), и вопрос номер один: какой ряд составлять – дискретный или интервальный? Смотрим на таблицу: среди предложенных цен есть одинаковые, но их разброс довольно велик, и поэтому здесь целесообразно провести интервальное разбиение. К тому же цены могут быть округлёнными.
наблюдений (таблица 10*3), и вопрос номер один: какой ряд составлять – дискретный или интервальный? Смотрим на таблицу: среди предложенных цен есть одинаковые, но их разброс довольно велик, и поэтому здесь целесообразно провести интервальное разбиение. К тому же цены могут быть округлёнными.
Начнём с экстремальной ситуации, когда у вас под рукой нет Экселя или другого подходящего программного обеспечения. Только ручка, карандаш, тетрадь и калькулятор.
Тактика действий похожа на исследование дискретного вариационного ряда. Сначала окидываем взглядом предложенные числа и определяем примерный интервал, в который вписываются эти значения. «Навскидку» все значения заключены в пределах от 5 до 11. Далее делим этот интервал на удобные подынтервалы, в данном случае напрашиваются промежутки единичной длины. Записываем их на черновик: 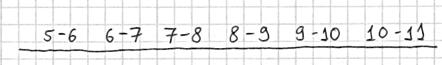
Теперь начинаем вычёркивать числа из исходного списка и записывать их в соответствующие колонки нашей импровизированной таблицы: 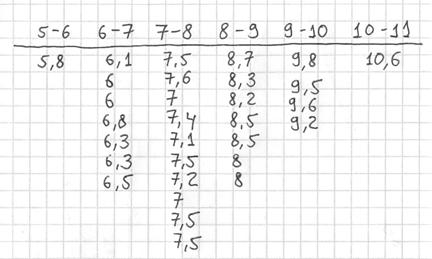
После этого находим самое маленькое число в левой колонке и самое большое значение – в правой. Тут даже ничего искать не пришлось, честное слово, не нарочно получилось:)
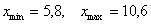 ден. ед. – хорошим тоном считается указывать размерность.
ден. ед. – хорошим тоном считается указывать размерность.
Вычислим размах вариации:
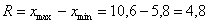 ден. ед. – длина общего интервала, в пределах которого варьируется цена.
ден. ед. – длина общего интервала, в пределах которого варьируется цена.
Теперь его нужно разбить на частичные интервалы. Сколько интервалов рассмотреть? По умолчанию на этот счёт существует формула Стерджеса:
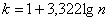 , где
, где 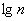 – десятичный логарифм* от объёма выборки и
– десятичный логарифм* от объёма выборки и 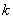 – оптимальное количество интервалов, при этом результат округляют до ближайшего левого целого значения.
– оптимальное количество интервалов, при этом результат округляют до ближайшего левого целого значения.
* есть на любом более или менее приличном калькуляторе
В нашем случае получаем:
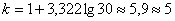 интервалов.
интервалов.
Следует отметить, что правило Стерджеса носит рекомендательный, но не обязательный характер. Нередко в условии задачи прямо сказано, на какое количество интервалов нужно проводить разбиение (на 4, 5, 6, 10 и т.д.), и тогда следует придерживаться именно этого указания.
Длины частичных интервалов могут быть различны, но в большинстве случаев использует равноинтервальную группировку:
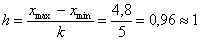 – длина частичного интервала. В принципе, здесь можно было не округлять и использовать длину 0,96, но удобнее, ясен день, 1.
– длина частичного интервала. В принципе, здесь можно было не округлять и использовать длину 0,96, но удобнее, ясен день, 1.
И коль скоро мы прибавили 0,04, то по 5 частичным интервалам у нас получается «перебор»: 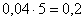 . Посему от самой малой варианты
. Посему от самой малой варианты 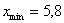 отмеряем влево 0,1 влево (половину «перебора») и к значению 5,7 начинаем прибавлять по
отмеряем влево 0,1 влево (половину «перебора») и к значению 5,7 начинаем прибавлять по 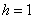 , получая тем самым частичные интервалы. При этом сразу рассчитываем их середины
, получая тем самым частичные интервалы. При этом сразу рассчитываем их середины 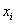 (например,
(например, 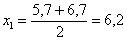 ) – они требуются почти во всех тематических задачах:
) – они требуются почти во всех тематических задачах: 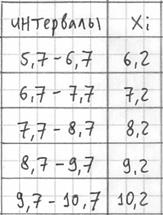
– убеждаемся в том, что самая большая варианта 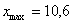 вписалась в последний частичный интервал и отстоит от его правого конца на 0,1.
вписалась в последний частичный интервал и отстоит от его правого конца на 0,1.
Далее подсчитываем частоты по каждому интервалу. Для этого в черновой «таблице» обводим значения, попавшие в тот или иной интервал, подсчитываем их количество и вычёркиваем: 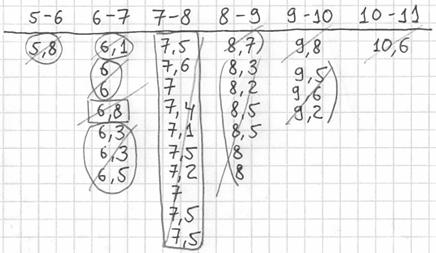
Так, значения из 1-го интервала я обвёл овалами (7 штук) и вычеркнул, значения из 2-го интервала – прямоугольниками (11 штук) и вычеркнул и так далее.
Правило: если варианта попадает на «стык» интервалов, то её следует относить в правый интервал. У нас такая варианта встретилась одна: 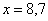 – и её нужно причислить к интервалу
– и её нужно причислить к интервалу 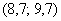 .
.
В результате получаем интервальный вариационный ряд: 
при этом обязательно убеждаемся в том, что ничего не потеряно: 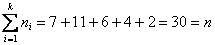 , ОК.
, ОК.
Изобразим ряд графически. Для этого по каждому интервалу нужно найти (не пугаемся): плотность частот 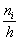 , относительные частоты
, относительные частоты 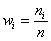 (округляем их до 2 знаков после запятой), а также плотность относительных частот
(округляем их до 2 знаков после запятой), а также плотность относительных частот 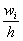 . Поскольку длина частичного интервала
. Поскольку длина частичного интервала 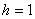 , то вычисления заметно упрощаются:
, то вычисления заметно упрощаются: 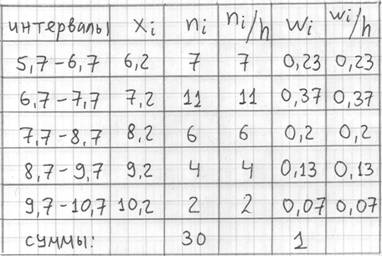
В том случае, если интервалы имеют разные длины 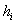 , то при нахождении плотностей каждую частоту нужно делить на длину своего интервала:
, то при нахождении плотностей каждую частоту нужно делить на длину своего интервала: 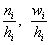 . Но у нас популярная равноинтервальная группировка, да не абы какая, а с единичным частичным интервалом. Возьмите на заметку всю выгоду такого интервала.
. Но у нас популярная равноинтервальная группировка, да не абы какая, а с единичным частичным интервалом. Возьмите на заметку всю выгоду такого интервала.
Дело за чертежами. Один за другим.
Гистограмма частот – это фигура, состоящая из прямоугольников, ширина которых равна длинам частичных интервалов, а высота – соответствующим плотностям частот: 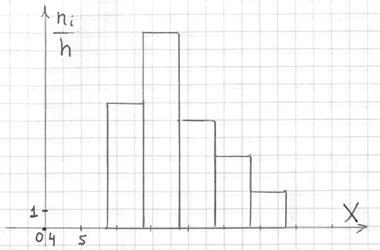
При этом вполне допустимо использовать нестандартную шкалу по оси абсцисс, в данном случае я начал нумерацию с четырёх.
Площадь гистограммы частот в точности равна объёму совокупности: 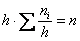 . В нашем случае
. В нашем случае 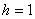 и плотности
и плотности 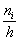 совпали с самими частотами
совпали с самими частотами 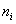 , таким образом:
, таким образом: 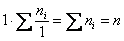
Гистограмма относительных частот – это фигура, состоящая из прямоугольников, ширина которых равна длинам частичных интервалов, а высота – соответствующим плотностям относительных частот: 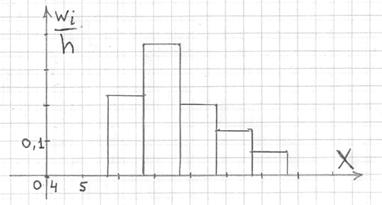
Площадь такой гистограммы равна единице: 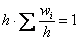 , и это статистический аналог функции плотности распределения непрерывной случайной величины. Построенный чертёж даёт наглядное и весьма точное представление о распределении цен на ботинки по всей генеральной совокупности. Но это при условии, что выборка представительна.
, и это статистический аналог функции плотности распределения непрерывной случайной величины. Построенный чертёж даёт наглядное и весьма точное представление о распределении цен на ботинки по всей генеральной совокупности. Но это при условии, что выборка представительна.
И для ИВР чаще всего строят гистограмму именно относительных частот. А вместе с ней нередко и полигон таковых частот. Без проблем, полигон относительных частот – это ломаная, соединяющая соседние точки 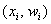 , где
, где 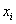 – середины интервалов:
– середины интервалов: 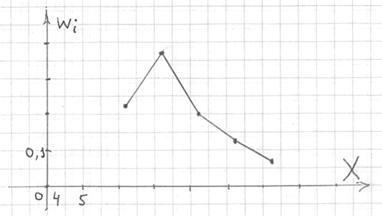
По сути, здесь мы приблизили интервальный ряд дискретным, выбрав в качестве вариант середины интервалов. Это важнейший принцип и метод, который неоднократно встретится нам в последующих задачах.
Автоматизируем решение в Экселе:
 Как составить ИВР и представить его графически? (Ютуб)
Как составить ИВР и представить его графически? (Ютуб)
(видео с неточностями, скоро исправлю и перезалью)
И бонус – эмпирическая функция распределения. Она определяется точно так же, как в дискретном случае:
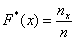 , где
, где 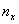 – количество вариант СТРОГО МЕНЬШИХ, чем «икс», который «пробегает» все значения от «минус» до «плюс» бесконечности.
– количество вариант СТРОГО МЕНЬШИХ, чем «икс», который «пробегает» все значения от «минус» до «плюс» бесконечности.
Но вот построить её для интервального ряда намного проще. Находим накопленные относительные частоты: 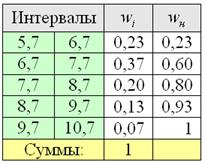
И строим кусочно-ломаную линию, с промежуточными точками 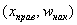 , где
, где 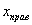 – правые концы интервалов, а
– правые концы интервалов, а 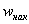 – относительная частота, которая успела накопиться на всех «пройденных» интервалах:
– относительная частота, которая успела накопиться на всех «пройденных» интервалах: 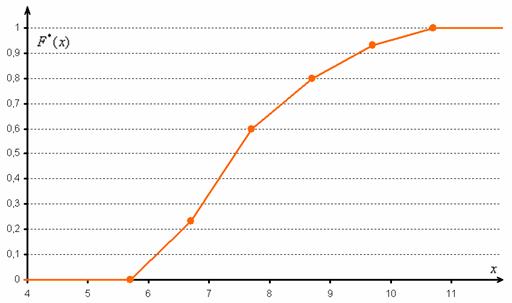
При этом 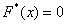 если
если 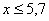 и
и 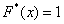 если
если 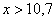 .
.
Напоминаю, что данная функция не убывает, принимает значения из промежутка 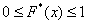 и, кроме того, для ИВР она ещё и непрерывна.
и, кроме того, для ИВР она ещё и непрерывна.
Эмпирическая функция распределения является аналогом функции распределения НСВ и приближает теоретическую функцию 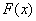 , которую теоретически, а иногда и практически можно построить по всей генеральной совокупности.
, которую теоретически, а иногда и практически можно построить по всей генеральной совокупности.
Помимо перечисленных графиков, вариационные ряды также можно представить с помощью кумуляты и огивы частот либо относительных частот, но в классическом учебном курсе эта дичь редкая, и поэтому о ней буквально пару абзацев:
Кумулята – это ломаная, соединяющая точки:
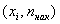 * либо
* либо 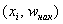 – для дискретного вариационного ряда;
– для дискретного вариационного ряда;
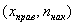 либо
либо 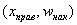 – для интервального вариационного ряда.
– для интервального вариационного ряда.
* 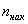 – накопленные «обычные» частоты
– накопленные «обычные» частоты
В последнем случае кумулята относительных частот 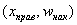 представляет собой «главный кусок» недавно построенной эмпирической функции распределения.
представляет собой «главный кусок» недавно построенной эмпирической функции распределения.
Огива – это обратная функция по отношению к кумуляте – здесь варианты откладываются по оси ординат, а накопленные частоты либо относительные частоты – по оси абсцисс.
С построением данных линий, думаю, проблем быть не должно, чего не скажешь о другой проблеме. Хорошо, если в вашей задаче всего лишь 20-30-50 вариант, но что делать, если их 100-200 и больше? В моей практике встречались десятки таких задач, и ручной подсчёт здесь уже не торт. Считаю нужным снять небольшое видео:
Как быстро составить ИВР при большом объёме выборки? (Ютуб)
Ну, теперь вы монстры 8-го уровня 🙂
Но не всё так сурово. В большинстве задач вам предложат готовый вариационный ряд, и на счёт молока, то, конечно, была шутка:
Выборочная проверка партии чая, поступившего в торговую сеть, дала следующие результаты:

Требуется построить гистограмму и полигон относительных частот, эмпирическую функцию распределения
Проверяем свои навыки работы в Экселе! (исходные числа и краткая инструкция прилагается) И на всякий случай краткое решение для сверки в конце урока. Должен признаться, я немного усложнил это задание, сделав интервалы разной длины – для лучшего понимания материала.
Что ещё важного по теме? Время от времени встречаются ИВР с открытыми крайними интервалами, например: 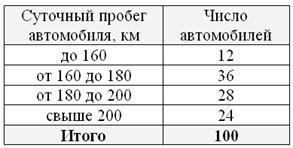
В таких случаях, что убийственно логично, интервалы «закрывают». Обычно поступают так: сначала смотрим на средние интервалы и выясняем длину частичного интервала: 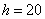 км. И для дальнейшего решения можно считать, что крайние интервалы имеют такую же длину: от 140 до 160 и от 200 до 220 км. Тоже логично. Но уже не убийственно:) Если внутренние интервалы имеют разные длины, то для крайних интервалов можно взять среднюю арифметическую известных длин.
км. И для дальнейшего решения можно считать, что крайние интервалы имеют такую же длину: от 140 до 160 и от 200 до 220 км. Тоже логично. Но уже не убийственно:) Если внутренние интервалы имеют разные длины, то для крайних интервалов можно взять среднюю арифметическую известных длин.
Ну вот, пожалуй, и вся практически важная информация по ИВР.
На очереди числовые характеристики вариационных рядов и начнём мы с их центральных характеристик, а именно – Моды, медианы и средней.
Пример 7. Решение: в данной задаче интервалы имеют разные длины 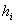 , заполним расчётную таблицу:
, заполним расчётную таблицу: 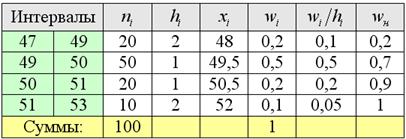
Построим гистограмму относительных частот: 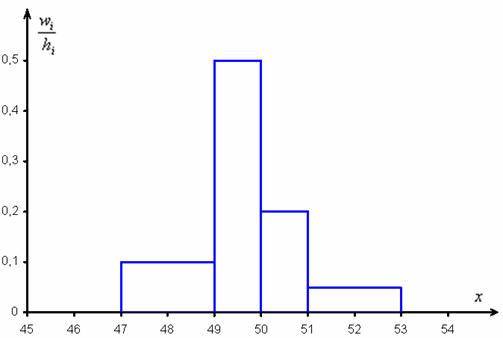
Построим полигон относительных частот: 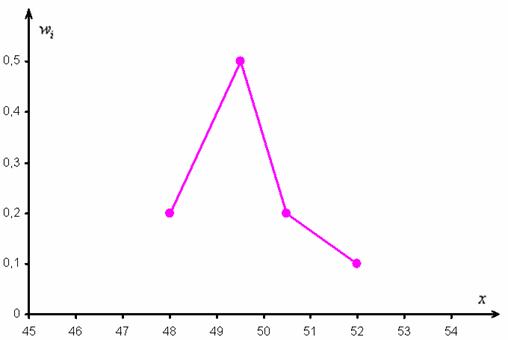
Построим эмпирическую функцию распределения: 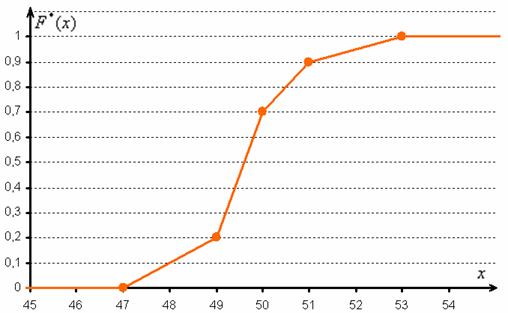
Автор: Емелин Александр
(Переход на главную страницу)
 Zaochnik.com – профессиональная помощь студентам
Zaochnik.com – профессиональная помощь студентам
cкидкa 15% на первый зaкaз, прoмoкoд: 5530-hihi5
Tutoronline.ru – онлайн репетиторы по математике и другим предметам
Правила построения дискретных и интервальных рядов распределения

Что такое группировка статистических данных, и как она связана с рядами распределения, было рассмотрено в первой части этой лекции, там же можно узнать, о том что такое дискретный и вариационный ряд распределения.
Ряды распределения одна из разновидностей статистических рядов (кроме них в статистике используются ряды динамики), используются для анализа данных о явлениях общественной жизни. Построение вариационных рядов вполне посильная задача для каждого. Однако есть правила, которые необходимо помнить.
Как построить дискретный вариационный ряд распределения
0 1 2 3 1
2 1 2 1 0
4 3 2 1 1
1 0 1 0 2
Решение:
Вторая колонка это частота – как часто встречается наша варианта в исследуемом явление – название колонки так же берем из задания — распределения семей – значит наша частота это число семей с соответствующим количеством детей.
В итоге макет нашей таблицы будет выглядеть так:
И расставим эти данные в первой колонке нашей таблицы в логическом порядке, в данном случае возрастающем от 0 до 4. Получаем
| Число детей в семье — (х) | Количество семей (f) |
| 0 1 2 3 4 |
И в заключение подсчитаем, сколько же раз встречается каждое значение варианты.
0 1 2 3 1
2 1 2 1 0
4 3 2 1 1
1 0 1 0 2
В результате получаем законченную табличку или требуемый ряд распределения семей по количеству детей.
| Число детей в семье — (х) | Количество семей (f) |
| 0 1 2 3 4 | 4 8 5 2 1 |
| Итого | 20 |
Задание. Имеются данные о тарифных разрядах 30 рабочих предприятия. Построить дискретный вариационный ряд распределения рабочих по тарифному разряду. 2 3 2 4 4 5 5 4 6 3
1 4 4 5 5 6 4 3 2 3
4 5 4 5 5 6 6 3 3 4
Как построить интервальный вариационный ряд распределения
Построим интервальный ряд распределения, и посмотрим чем же его построение отличается от дискретного ряда.
Пример 2. Имеются данные о величине полученной прибыли 16 предприятий, млн. руб. — 23 48 57 12 118 9 16 22 27 48 56 87 45 98 88 63. Построить интервальный вариационный ряд распределения предприятий по объему прибыли, выделив 3 группы с равными интервалами.
Общий принцип построения ряда, конечно же, сохраниться, те же две колонки, те же варианта и частота, но в здесь варианта будет располагаться в интервале и подсчет частот будет вестись иначе.
Вторая колонка это частота – как часто встречается наша варианта в исследуемом явление – название колонки так же берем из задания — распределения предприятий – значит наша частота это число предприятий с соответствующей прибылью, в данном случае попадающие в интервал.
В итоге макет нашей таблицы будет выглядеть так:
где i – величина или длинна интервала,
Хmax и Xmin – максимальное и минимальное значение признака,
n – требуемое число групп по условию задачи.
Рассчитаем величину интервала для нашего примера. Для этого среди исходных данных найдем самое большое и самое маленькое
23 48 57 12 118 9 16 22 27 48 56 87 45 98 88 63 – максимальное значение 118 млн. руб., и минимальное 9 млн. руб. Проведем расчет по формуле.
В расчете получили число 36,(3) три в периоде, в таких ситуациях величину интервала нужно округлить до большего, чтобы после подсчетов не потерялось максимальное данное, именно поэтому в расчете величина интервала 36,4 млн. руб.
Обратим внимание если бы мы не округлили величину интервала до 36,4, а оставили бы ее 36,3, то последнее значение у нас бы получилось 117,9. Именно для того чтобы не было потери данных необходимо округлять величину интервала до большего значения.
При проведении обработки данных лучше всего отобранные данные обозначить условными значками или цветом, для упрощения обработки.
23 48 57 12 118 9 16 22
27 48 56 87 45 98 88 63
Первый интервал обозначим желтым цветом – и определим сколько данных попадает в интервал от 9 до 45,4, при этом данное 45,4 будет учитываться во втором интервале (при условии что оно есть в данных) – в итоге получаем 7 предприятий в первом интервале. И так дальше по всем интервалам.
По первому интервалу — 23 + 12 + 9 + 16 + 22 + 27 + 45 = 154 млн. руб.
По второму интервалу — 48 + 57 + 48 + 56 + 63 = 272 млн. руб.
По третьему интервалу — 118 + 87 + 98 + 88 = 391 млн. руб.
| Объем полученной прибыли, млн. руб. — (х) | Число предприятий (f) | Общий объем прибыли, млн. руб. |
| 9,0 — 45,4 45,4 — 81,8 81,8 — 118,2 | 7 5 4 | 154 272 391 |
| Итого | 16 | 817 |
Задание. Имеются данные о величине вклада в банке 30 вкладчиков, тыс. руб. 150, 120, 300, 650, 1500, 900, 450, 500, 380, 440,
600, 80, 150, 180, 250, 350, 90, 470, 1100, 800,
500, 520, 480, 630, 650, 670, 220, 140, 680, 320
Построить интервальный вариационный ряд распределения вкладчиков, по размеру вклада выделив 4 группы с равными интервалами. По каждой группе подсчитать общий размер вкладов.