HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Как анализировать POST запросы в веб-браузере
Современные веб-сайты становятся всё сложнее, используют всё больше библиотек и веб технологий. Для целей отладки разработчиками сложных веб-сайтов и веб-приложений потребовались новые инструменты. Ими стали «Инструменты разработчика» интегрированные в сами веб-браузеры:
Они по умолчанию поставляются с браузерами (Chrome и Firefox) и предоставляют много возможностей по оценке и отладке сайтов для самых разных условий. К примеру, можно открыть сайт или запустить веб-приложение как будто бы оно работает на мобильном устройстве, или симулировать лаги мобильных сетей, или запустить сценарий ухода приложения в офлайн, можно сделать скриншот всего сайта, даже для больших страниц, требующих прокрутки и т.д. На самом деле, Инструменты разработчика требуют глубокого изучения, чтобы по-настоящему понять всю их мощь.
В предыдущих статьях я уже рассматривал несколько практических примеров использования инструментов DevTools в браузере:
Эта небольшая заметка посвящена анализу POST запросов. Мы научимся просматривать отправленные методом POST данные прямо в самом веб-браузере. Научимся получать их в исходном («сыром») виде, а также в виде значений переменных.
Я буду показывать на примере сайта http://spys.one/en/free-proxy-list/ из статьи про прокси. (На самом деле, это простейший пример — в качестве более сложных примеров, попробуйте самостоятельно разобраться, например, в POST GMail при открытии и других действий с письмами).
По фрагменту исходного кода страницы видно, что данные из формы передаются методом POST, причём используется конструкция onChange=»this.form.submit();»:
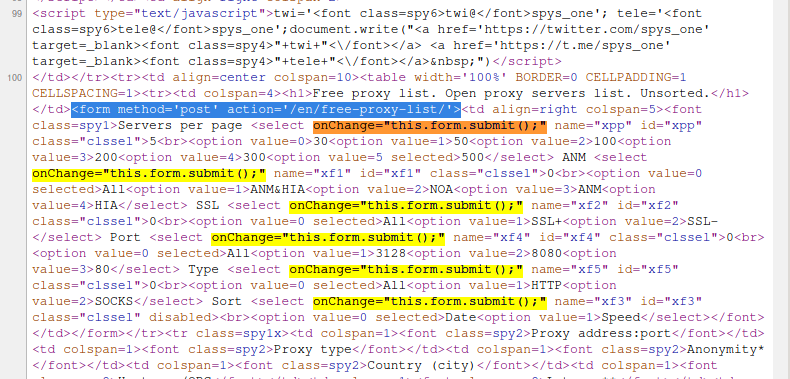
Как увидеть данные, переданные методом POST, в Google Chrome
Итак, открываем (или обновляем, если она уже открыта) страницу, от которой мы хотим узнать передаваемые POST данные. Теперь открываем инструменты разработчика (в предыдущих статьях я писал, как это делать разными способами, например, я просто нажимаю F12):

Теперь отправляем данные с помощью формы.
Переходим во вкладку «Network» (сеть), кликаем на иконку «Filter» (фильтр) и в качестве значения фильтра введите method:POST:
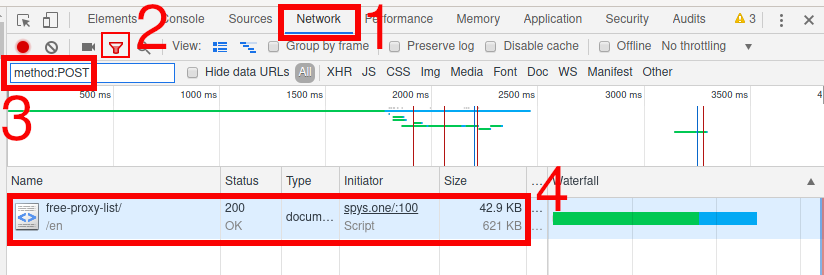
Как видно на предыдущем скриншоте, был сделан один запрос методом POST, кликаем на него:

Поскольку нам нужно увидеть отправленные методом POST данные, то нас интересует столбец Header.
Там есть разные полезные данные, например:
Пролистываем до Form Data:
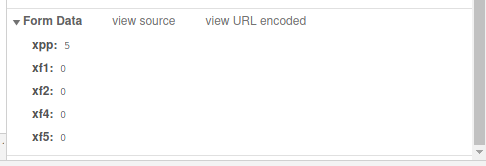
Там мы видим пять отправленных переменных и из значения.
Если нажать «view source», то отправленные данные будут показаны в виде строки:

Как увидеть данные, переданные методом POST, в Firefox
В Firefox всё происходит очень похожим образом.
Открываем или обновляем нужную нам страницу.
Открываем Developer Tools (F12).
Отправляем данные из формы.
Переходим во вкладку «Сеть» и в качестве фильтра вставляем method:POST:
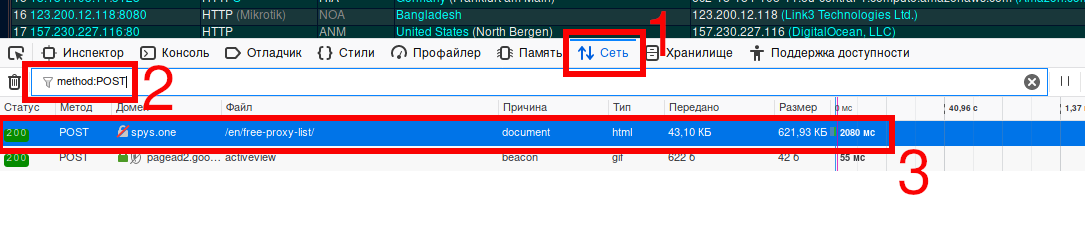
Кликните на интересующий вас запрос и в правой части появится окно с дополнительной информацией о нём:
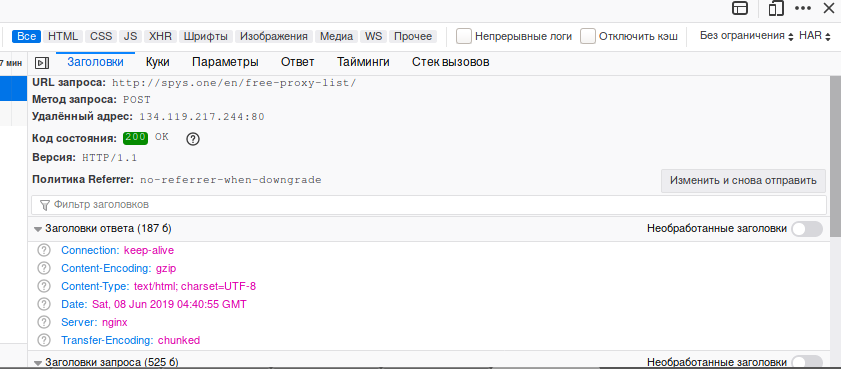
Переданные в форме значения вы увидите если откроете вкладку «Параметры»:
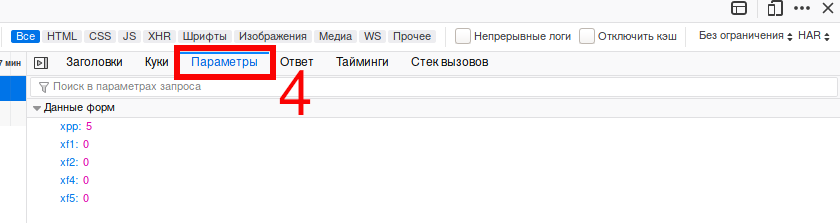
Если вы хотите получить отправленные данные в виде строки, то вернитесь во вкладку «Заголовки» и нажмите кнопку «Изменить и снова отправить», в открывшейся области пролистните до «Тело запроса»:

Как вы уже поняли, здесь не только можно скопировать строку POST, но и отредактировать её и отправить запрос заново.
Другие фильтры инструментов разработчика
Для Chrome кроме уже рассмотренного method:POST доступны следующие фильтры:
 Как посмотреть HTTP заголовки (headers)
Как посмотреть HTTP заголовки (headers)
 Как посмотреть HTTP заголовки (headers)
Как посмотреть HTTP заголовки (headers)
Вступление
При отладке работы веб-сервера, может возникнуть необходимость посмотреть HTTP заголовки ответа, которые отдает какая-либо страница сайта посетителю. В данной статье будут рассмотрены несколько простых способов, как это можно сделать.
С помощью онлайн сервиса
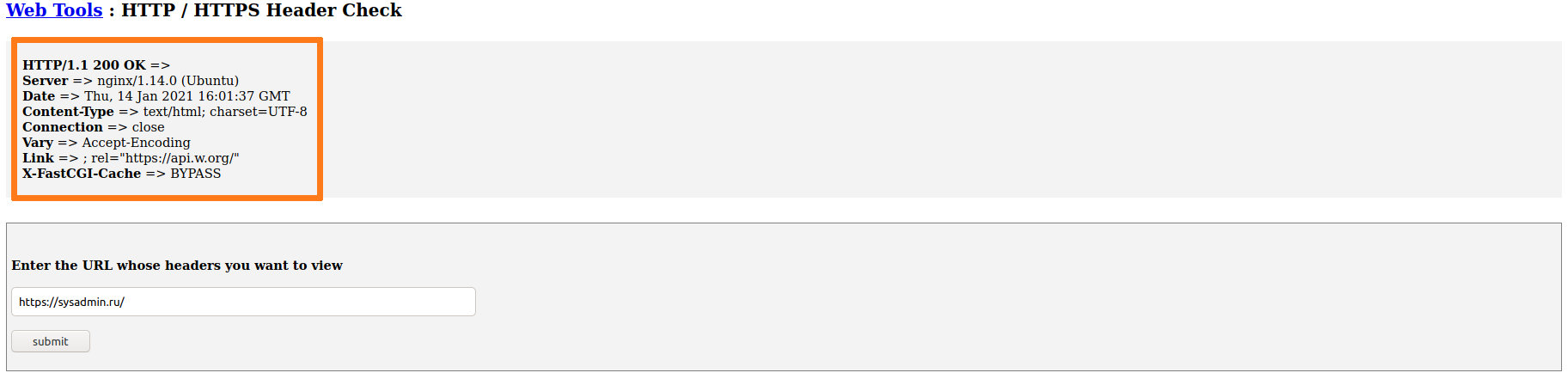
Если вам нужно быстро посмотреть заголовки какой-либо страницы, то это можно сделать с помощью онлайн сервисов. Для примера, это можно сделать здесь:
Вбиваем нужную страниц сайта и жмем кнопку ‘submit’ в итоге получаем следующую страницу с заголовками:
С помощью curl
Если в вашей системе установлен curl, то с его помощью можно без проблем посмотреть заголовки ответа (Response Headers), полученные от веб-сервера. Для этого достаточно запустить curl со следующими параметрами:
После чего мы получим вот такой вот вывод:
С помощью браузера
Практически все современные браузеры позволяют посмотреть заголовки.
Firefox
Открываем нужную страницу, нажимаем F12 и открываем консоль. Далее, в консоли выбираем логирование «Запросов» и обновляем страницу, после этого, можно будет посмотреть заголовки: 
Мониторинг запросов в Chrome
в Firefox я использую Firebug, который позволяет мне просматривать каждый http-запрос, который делают мои вызовы ajax. Я переключил свою разработку на Chrome, и мне это нравится до сих пор. Моя единственная жалоба заключается в том, что инструменты разработчика, кажется, не позволяют просматривать каждый запрос AJAX. У меня это произошло однажды, когда панель ресурсов показала несколько запросов к одному и тому же ресурсу, но это сделано только один раз и никогда больше.
есть ли способ надежно увидеть каждый http-запрос, который страница делает через javascript из Chrome?
В настоящее время, чтобы обойти это, я запускаю Fiddler рядом с Chrome для просмотра моих запросов, но если есть способ сделать это из браузера, я бы предпочел это.
9 ответов
Я знаю, что это старая нить, но я думал, что я вмешаюсь.
Chrome в настоящее время имеет встроенное решение.
самый актуальный ответ на это: они перечислены под кнопкой «сеть» в инструментах разработчика, а не под «ресурсами», как раньше.
вы также можете использовать эту ссылку в Chrome для получения более подробной информации, чем инспектор.
Это показывает журнал всех запросов браузера при открытии
Не знаю, в какой версии chrome это доступно, но я нашел параметр «Console-Log XMLHttpRequests» (нажав на значок в правом нижнем углу инструментов разработчика в chrome на mac)
можно использовать Саша что является хорошим бесплатным инструментом.
откройте DevTools и нажмите F1 для доступа к настройкам. Найдите раздел консоли и установите флажок «Log XMLHttpRequests».
теперь все ваши AJAX и другие подобные запросы будут регистрироваться в консоли.
Я предпочитаю этот метод, потому что он обычно позволяет мне видеть все, что я ищу в консоли без необходимости перейти на вкладку Сеть.
спасибо всем, кто пытается помочь в этом посте
у меня ubuntu 13.10, а моя версия chrome-34.0
для моей ситуации это работает
теперь вы должны увидеть новую панель перед вами запрос
на шаге 5 Phil «ресурсы» больше не доступны в новой версии Chrome. Вам нужно щелкнуть значок страницы рядом со страницей Ajax, указанной в нижней панели, со столбцами Name, Method, Status.
затем он покажет вам несколько панелей, где вы найдете сообщения об ошибках.
вы также можете просто щелкнуть правой кнопкой мыши на странице в браузере и выбрать «проверить элемент», чтобы открыть инструменты разработчика.
H Анатомия HTTP-запроса в черновиках

Каждый хороший разработчик должен знать, что происходит под капотом после того, как пользователь введет URL сайта в адресной строке браузера и нажмет кнопку «Перейти». На самом деле это самый частый вопрос на собеседовании. В этой статье мы разберем, что происходит во время обработки HTTP-запроса.
Терминология
Для того, чтобы понять, как обрабатывается запрос вам нужно знать следующие определения:
Шаг 1: поиск DNS
На самом деле веб-адреса представляют собой простую строку, которую выглядит как-то так: 216.58.198.174. Если вы перейдете по этому адресу с помощью браузера, то откроется Google. Доменное имя (google.com) это просто псевдоним, который позволяет пользователю легче запомнить адрес.
Итак, когда пользователь вводит доменное имя (например, google.com), браузер делает запрос к DNS и получает IP-адрес, который связан с этим именем.
Думайте о DNS как о телефонной книге. Вместо того, что запоминать номер Вани, вы можете записать его в телефонную книгу. Затем вы можете просто нажать «позвонить Ване» и ваш телефон найдет его номер в базе, и позвонит по этому номеру. В этой аналогии имя «Ваня» — это доменное имя, его номер — это IP-адрес, а телефонная книга — это DNS.
Шаг 2: выполнение запроса
После того, как браузер получил IP-адрес сервера от DNS, он может приступить к созданию запроса. Запрос содержит в себе заголовок и также может содержать тело запроса (например, данные из формы, которую отправил пользователь).
Заголовок содержит в себе следующие параметры:
В итоге запрос будет выглядеть так:
Дополнительная информация может быть добавлена ниже. Они представлены в виде пар ключ/значение, где ключ — это идентификатор, название, а значение — собственно сам кусочек информации. Пример ниже включают в себя информацию о браузере пользователя (user-agent), куки (cookies), тип содержимого (content type), хост (host), которое в данном случае является названием домена и т.д. Полный HTTP-запрос выглядит как-то так:
Шаг 3: ответ сервера
После того, как сервер получил запрос, он генерирует ответ. Так же как и запрос ответ содержит различную информацию, включая:
Обычный ответ сервера выглядит как-то так:
Поле Content-Type говорит, браузеру, какой тип содержимого ему следует ожидать. В данном случае это простой HTML. Таким образом, браузер узнает, что ему нужно отрендерить и показать HTML. Тип содержимого может быть также указан как картинка, видео, JSON и т.д. Это поле говорит браузеру, как нужно обработать полученную информацию.
HTML также подключает различные ресурсы, такие как изображения, видео, шрифты или внешние CSS и JavaScript-файлы. Браузер отправляет запросы к серверу для получения этих ресурсов, а затем размещает их на странице. Если вы откроете инструменты разработчика в Google Chrome (Ctrl+Shift+J) и откроете какой-нибудь сайт, то увидите запросы, которые выполнил браузер (вкладка Network).

Заключение
Итак, теперь у вас есть общее представление как работают HTTP-запросы. Конечно все становится намного сложнее, когда дело доходит до отправки формы и загрузки файлов, но это уже совсем другая история.
комментарии ( 9 )
Во-первых, для «оригинал тут» есть выбор публикация/перевод.
Во-вторых статей такого вида уже даже на хабре тонна и непонятно зачем этот мусор нужен ещё раз, да ещё и в хабе «программирование».

Это не считая того, что это же написано в help’е: https://habrahabr.ru/info/help/posts/:
Если нажать на слово «Публикацию» во фразе «Хочу опубликовать публикацию», то ниспадающее меню предложит вам выбрать второй доступный для создания вид записи — «Перевод». Механизм создания тот же, что и у публикации, но есть два дополнительных поля — «Автор оригинала» (тут надо указать имя автора оригинального текста) и «Ссылка на оригинал» (здесь — URL страницы оригинала).
Статья очень-очень базовая. На мой взгляд, ее польза несколько сомнительна, но тем не менее, позволю себе оставить пару замечаний.
Мне кажется, что упоминание того, что заголовок Host с доменным именем используется веб-сервером для возможности одновременной работы нескольких веб-ресурсов на одном IP-адресе заслуживает упоминания даже в такой базовой статье. Хотя бы для того, чтобы новичку было понятно, почему при блокировке одного IP блокируются другие сайты, хостящиеся на том же адресе.
«Заголовок» — это на самом деле «строка запроса» (request line), чтобы не создавать путаницы с заголовками (headers), это проблема не перевода, а оригинала. «Пары ключ-значение» — это как раз заголовки.
И еще, мне кажется, что в самых базовых статьях стоит освещать тот факт, что уже 17 лет протокол HTTP/1.1, позволяет не закрывать соединение после каждого запроса-ответа для того чтобы ускорить работу сети, избавившись от затрат на переподключение для каждого ресурса. Для того, чтобы сервер и клиент понимали, когда данные завершились, используется, на мой взгляд один из самых главных заголовков Content-length, значением которого является размер тела сообщения в байтах. Если игнорировать этот заголовок в своих приложениях, даже при указании HTTP/1.1 в строке ответа сервера, соединение будет фактически HTTP/1.0 (Конечно, если не указан Transfer-Encoding, но вот это уже advanced ИМХО) Вообще, последняя спека написана вполне себе человеческим языком и не слишком длинная.
… а что, новичкам можно давать ошибочную информацию?
А почему в ответ на вопрос «что происходит» выбран именно этот уровень абстракции? Почему не разбираются детали TCP/IP соединения? Или HTTPS, которого сейчас много? Или почему не разбирается, что происходит в браузере между моментом нажатия на Enter и отправкой собственно HTTP-запроса?
В конце концов, почему переход на страницу в браузере приравнивается к HTTP-запросу?
+1
Начиная про то, что запрос имён в DNS не такая и простая штука, как кажется, заканчивая тем, что на шаге 2 перед формированием запроса происходит хотя бы банальное подключение к серверу.
Очередная статья, очень низкого уровня, имхо не годная для хабра, а вот для начинающих эникеев/домохозяек сойдет.
> Анатомия HTTP-запроса
И уж точно статью нельзя назвать «Анатомией http», а так — «беглый осмотр веб-технологий»
Время указано в том часовом поясе, который установлен на Вашем устройстве.
Как посмотреть HTTP заголовки
Что такое HTTP заголовки
HTTP протокол используется при открытии сайтов и скачивании файлов из Интернета. HTTP протокол работает по принципу запрос-ответ — от клиента приходит запрос и сервер отправляет ответ. Каждый запрос и каждый ответ состоит из элементов:
Тело сообщения — это то, ради чего делается запрос — страница сайта или файл.
Заголовки — это метаинформация, которую мы обычно не видим.
В заголовках запроса могут быть такие данные как:
В заголовках ответа могут быть такие данные как:
Эта статья расскажет, как посмотреть HTTP заголовки.
Как в веб-браузере увидеть HTTP заголовки
Это самый простой способ, доступный в любой операционной системе.
Нажмите в веб-браузере F12 и откройте интересующую вас страницу. Перейдите на вкладку Network (сеть) и выберите интересующее вас подключение.
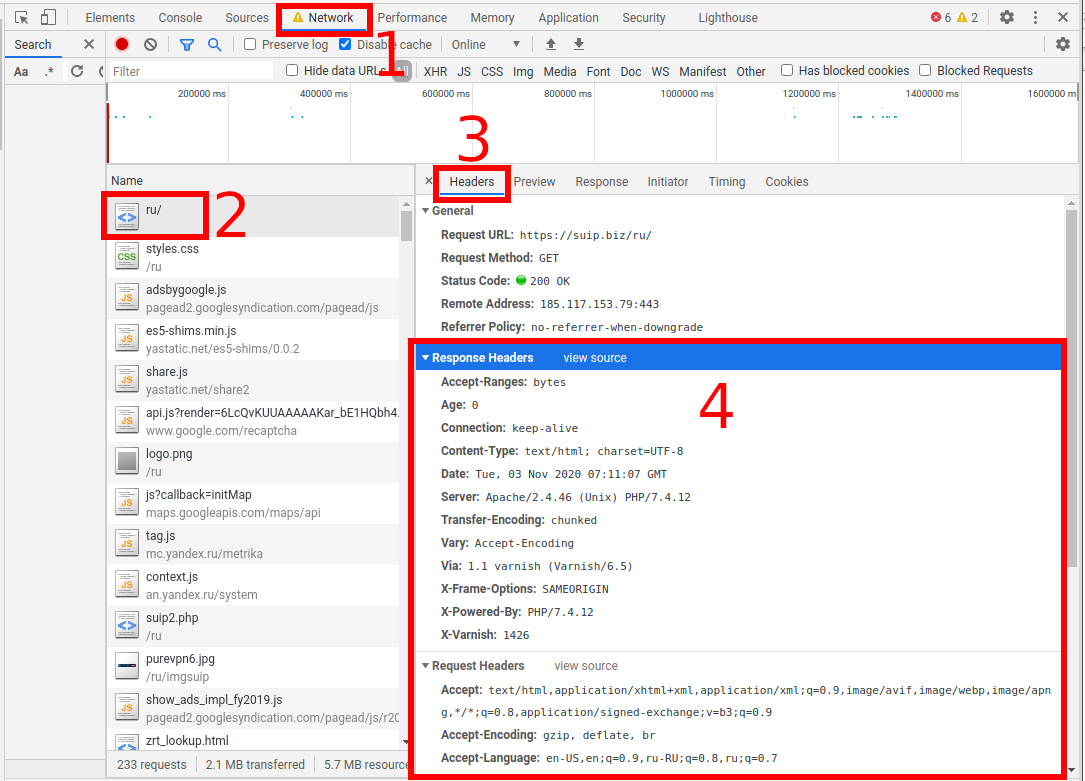
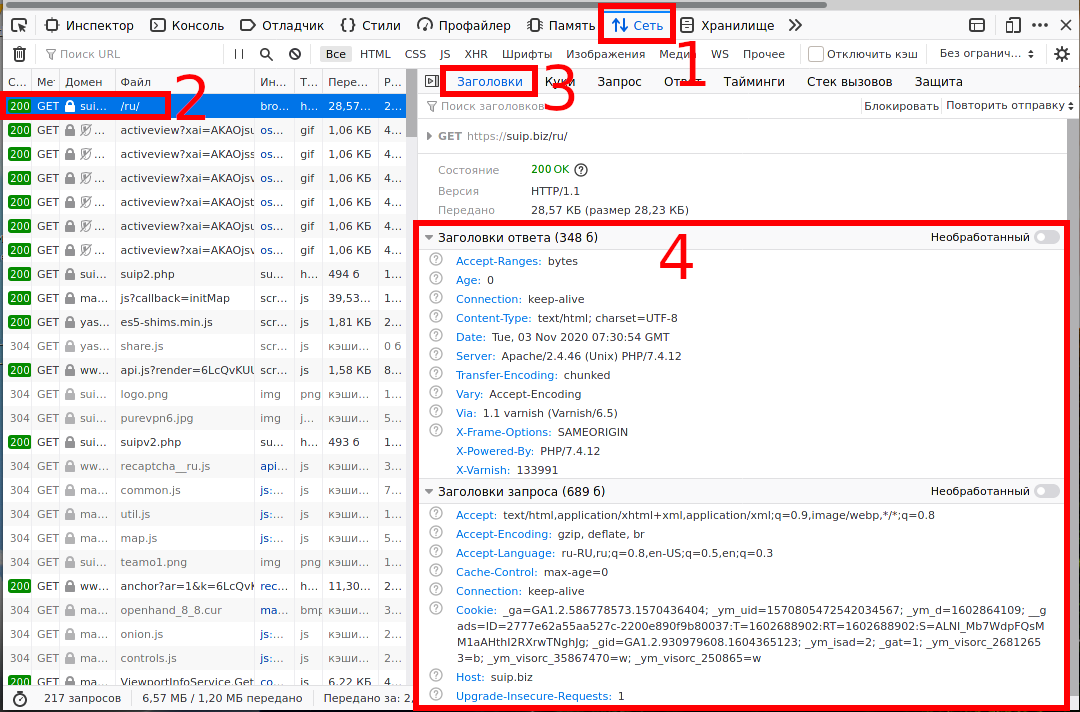
Вначале идут Заголовки ответа (Response Headers), а затем Заголовки запроса (Request Headers), хотя, конечно же, вначале отправляется запрос и его заголовки, а затем приходит ответ.
Это удобный метод, причём вам не нужно беспокоиться о HTTPS протоколе — поскольку веб-браузер является конечным адресатом, то он может показывать уже расшифрованные данные.
Как в cURL посмотреть HTTP заголовки
Для cURL есть опции -I, -v и -i, которые делают так, что эта утилита показывает HTTP заголовки.
Разница в том, что опция -I означает использовать метод HEAD, то есть в реальности кроме HTTP заголовков ничего не будет прислано. А опция -v делает вывод более вербальным, в результате в него включаются и заголовки. Но если вы отправляете запрос по HTTPS протоколу, то с опцией -v также будут показаны данные, относящиеся к TLS рукопожатию — они не имеют отношения к HTTP заголовкам. Ещё нужно знать, что опция -I показывает только заголовки ответа, а опция -v показывает и Заголовки запроса и Заголовки ответа.
Опция -i также показывает только заголовки ответа, не показывает TLS рукопожатие, но зато показывает всё тело ответа.
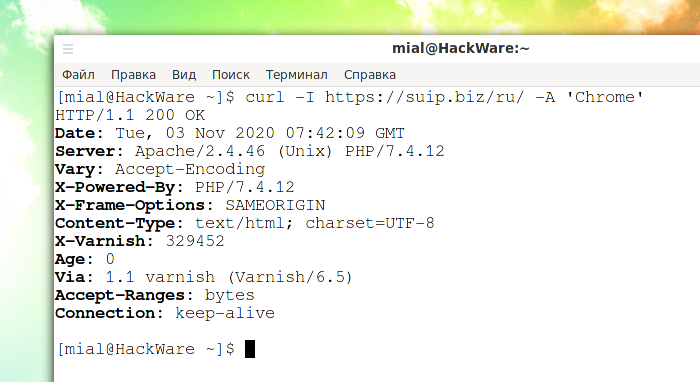
Пример использования метода HEAD:
Здесь «HTTP/1.1 200 OK» это строка статуса, а всё остальное — поля HTTP заголовка.
Пример вербального вывода:
Отправленные на веб сервер заголовки имеют в начале символ >, а полученные с веб-сервера строки начинаются на