Строим надёжный процессинг данных — лямбда архитектура внутри Google BigQuery
В этой статье хочу поделиться способом, который позволил нам прекратить хаос с процессингом данных. Раньше я считал этот хаос и последующий ре-процессинг неизбежным, а теперь мы забыли что это такое. Привожу пример реализации на BiqQuery, но трюк довольно универсальный. 
У нас вполне стандартный процесс работы с данными. Исходные данные в максимально сыром виде регулярно подгружаются в единое хранилище, в нашем случае в BigQuery. Из одних источников (наш собственный продакшн) данные приходят каждый час, из других (обычно сторонние источники) данные идут ежедневно.
В последствии данные обрабатываются до состояния пригодного к употреблению разнообразными пользователями. Это могут быть внутренние дашборды; отчёты партнёрам; результаты, которые идут в продакшн и влияют на поведение продукта. Эти операции могут быть довольно сложными и включать несколько источников данных. Но по большей части мы с этим справляется внутри BigQuery с помощью SQL+UDF. Результаты сохраняются в отдельные таблицы там же.
Очевидным способом организации этого процессинга является создание расписания операций. Если данные подгружаются ежедневно в час ночи, то мы настроим процессинг на 01:05. Если этот источник данных подгружается в районе 5й минуты каждого часа, то настроим процессинг на 10ю минуту каждого часа. Промежутки в 5 минут для пользователей не критичны и предполагается, что всё должно работать.
Но мир жесток! Данные не всегда приходят вовремя. Или вообще не приходят, если не починить. Если твоя часовая загрузка закончилась на 11й минуте, а трансформация запускалась на 10й – то пожалуйста, жди ещё час чтобы увидеть эти данные в дэшборде. А если операция использует несколько источников, то ситуация будет ещё веселее.
Более того, подгружаемые сырые данные не всегда верны (данные вообще всегда не верны!). Периодически данные приходится чистить или перезагружать. И тогда нужно перезапустить все операции и с корректными параметрами, чтобы всё починилось.
Это всё, конечно, проблемы с сырыми данными и нужно именно их и решать. Но это та война, в которой нельзя окончательно победить. Что-то всё равно будет поломано. Если источник данных внутренний – то ваши разработчики будут заняты новыми крутыми фичами, а не надёжностью трекинга. Если это сторонние данные, тогда вообще труба. Хотелось бы, чтобы по крайней мере процессинг не мешался по дороге и как только сырые данные починены — все клиенты сразу видели корректные результаты.
Это реально большая проблема. И как же ещё решить?
Решение №1 – убрать проблемные детали
Если процессинг приводит к проблемам, то не надо его делать! Не надо делать вообще никакой процессинг и хранить промежуточные результаты. Как только пользователю нужны результаты, всё должно вычисляться на лету из сырых данных. Учитывая скорость BigQuery это вполне реалистично. Особенно если все что вы делаете с данными это GROUP BY date и count(1), и нужны только данные за последние 14 дней.
Большинство аналитики работает именно с такими запросами. Поэтому мы данное решение активно используем. Но этот подход не работает со сложными трансформациями.
Одна проблема – это сложность кода. Если сложить все операции в один SQL запрос, то его будет не прочитать. К счастью это решается за счёт таблиц типа view (представления). Это логические таблицы в BigQuery, данные в них не хранятся, а генерируются из SQL-запроса на лету. Это сильно упрощает код.
Но другая проблема – это производительность. Здесь всё плохо. Не важно какие быстрые и дешёвые современные базы данных. Если запустить сложную трансформацию на одном годе исторических данных, это займёт время и будет стоить денег. Других вариантов нет. Эта проблема делает данную стратегию неприменимой в довольно большом проценте случаев.
Решение № 2 – построить сложную систему
Если нет возможности обойтись без системы управления процессингом, то нужно построить эту систему хорошо. Не просто расписание выполнения скриптов в cron, а система мониторинга загрузки данных, которая определяет когда и какие трансформации запускать. Наверное паттерн pub/sub тут очень подходит.
Но есть проблема. Если построить сложную систему более менее просто, то вот поддерживать её и ловить баги – это очень сложно. Чем больше кода, тем больше проблем.
По счастью есть и третье решение.
Решение № 3 – лямбда архитектура! …ну, типа того
Лямбда архитектура – это знаменитый подход к процессингу данных, который использует преимущества обработки данных по расписанию и в реальном времени:
*Как нормально перевести на русский не знаю, batch job – это что пакетное задание? Кто знает, подскажите!
Обычно это все строится с использованием нескольких решений. Но мы используем по сути тот же трюк просто внутри BigQuery.
И вот как это работает:
Процессинг по расписанию (Batch layer). Мы ежедневно выполняем SQL-запросы, которые трансформируют данные имеющиеся на текущий момент, и сохраняем результаты в таблицы. У всех запросов следующая структура:
Результаты этого запроса будут сохранены в table_static (перезапишут её). Да, BigQuery позволяет сохранять результаты запроса в таблице, которая использовалась в этом запросе. В итоге мы берём старые, уже посчитанные данные (чтобы их не пересчитывать) и соединяем с новыми данными. X дней – это выбранный период, за который мы хотим пересчитать данные, чтобы учесть все возможные корректировки сырых данных. Предполагается что за X дней (сколько – это индивидуально для источника) все корректировки уже будут внесены, всё что сломалось починится и данные уже больше не будут меняться.
Доступ в реальном времени (Speed layer + Serving layer). Эти обе задачи объединены в один SQL-запрос:
Да, это тот же самый запрос! Его мы сохраняем как представление (view) с именем table_live и все пользователи (дэшборды, другие запросы, и т.п.) тянут результаты из этого представления. Так как представления в BigQuery хранятся на логическом уровне (только запрос, не данные), каждый раз при обращении он будет пересчитывать последние X дней на лету и все изменения в изначальных данных будут отражены в результатах.
Так как запрос в обоих случаях одинаковый, то в реальности, чтобы избежать дупликации кода, ежедневный запрос (из batch layer) выглядит так:
(и сохраняем результаты в table_static)
PS Если любите использовать таблицы разбитые по датам в BigQuery (мы очень любим), то есть решение и для этого. Но это тема для другого поста. Подсказка – функции для работы с этими таблицами не ругаются, если часть таблиц – это только представления.
PPS Если бы представления в BigQuery поддерживали кешинг (как это работает с обычными запросами), это было бы реально круто. Это по сути сделало бы их материализованными (materialized views). И эффективность нашего подхода стала бы ещё выше. Если вы согласны – здесь можно поставить звёздочку, чтобы эту фичу быстрее реализовали.
Дата публикации Mar 15, 2018
Большие данные, Интернет вещей (IoT), модели машинного обучения и различные другие современные системы становятся сегодня неизбежной реальностью. Люди из всех слоев общества начали взаимодействовать с хранилищами данных и серверами в рамках своей повседневной жизни. Поэтому мы можем сказать, что работа с большими данными наилучшим образом становится основной областью интереса для бизнеса, ученых и частных лиц. Например, приложение, запущенное для достижения определенных бизнес-целей, будет более успешным, если оно сможет эффективно обрабатывать запросы клиентов и хорошо выполнять свои задачи. Такие приложения должны взаимодействовать с хранилищем данных, и в этой статье мы попытаемся изучить две важные архитектуры обработки данных, которые служат основой различных корпоративных приложений, известных как Lambda и Kappa.

Быстрый рост приложений для социальных сетей, облачных систем, Интернета вещей и бесконечного множества инноваций сделал важным для разработчика или ученого принимать взвешенные решения при запуске, обновлении или устранении неполадок корпоративного приложения. Несмотря на широкое признание и понимание того, что использование модульного подхода для создания приложения имеет множество преимуществ и долгосрочных преимуществ, стремление к выбору правильной архитектуры обработки данных по-прежнему ставит вопросительные знаки перед многими предложениями, касающимися существующих и будущих предприятий. програмное обеспечение. Хотя в настоящее время в мире используются различные архитектуры обработки данных, давайте подробно рассмотрим архитектуры Lambda и Kappa и выясним, что делает каждую из них особенной и при каких обстоятельствах следует отдавать предпочтение одной из них.
Лямбда-архитектура
Обработка данных связана с потоками событий, и большая часть корпоративного программного обеспечения, которые следуют архитектуре, управляемой доменом, использует метод обработки потоков для прогнозирования обновлений для базовой модели и сохранения отдельных событий, которые служат источником для прогнозов, в действующей системе данных. Для обработки многочисленных событий, происходящих в системе или в результате дельта-обработки, Lambda-архитектура обеспечивает обработку данных путем введения трех отдельных уровней. Лямбда-архитектура включает в себя пакетный уровень, скоростной уровень (также известный как потоковый уровень) и обслуживающий уровень.
1. Пакетный слой
2. Слой скорости (Stream Layer)
Слой скорости использует плод поиска событий, выполненный на пакетном слое. Потоки данных, обрабатываемые в пакетном уровне, приводят к обновлению дельта-процесса или MapReduce или модели машинного обучения, которая дополнительно используется потоковым уровнем для обработки новых данных, подаваемых в него. Скоростной уровень обеспечивает выходные данные на основе процесса обогащения и поддерживает обслуживающий уровень, чтобы уменьшить задержку при ответе на запросы. Как видно из его названия, уровень скорости имеет низкую задержку, поскольку он работает только с данными в реальном времени и имеет меньшую вычислительную нагрузку.
3 Обслуживающий слой
Выходные данные из пакетного уровня в виде пакетных представлений и из скоростного уровня в виде представлений, близких к реальному времени, направляются на обслуживающий уровень, который использует эти данные для обработки ожидающих запросов на специальной основе.
Вот базовая схема того, как должна выглядеть модель Lambda Architecture:

Давайте переведем это на функциональное уравнение, которое определяет любой запрос в большой области данных. Символы, используемые в этом уравнении, известны как лямбда, и название архитектуры лямбда также получено из того же уравнения. Эта функция широко известна тем, кто знаком с тонкостями анализа больших данных.
Уравнение означает, что все связанные с данными запросы могут обрабатываться в архитектуре Lambda путем объединения результатов из исторического хранилища в форме пакетов и потоковой передачи в реальном времени с помощью слоя скорости.
Приложения лямбда-архитектуры
Лямбда-архитектура может быть развернута для тех корпоративных моделей обработки данных, где:
Лямбда-архитектура может рассматриваться как архитектура обработки данных, близкая к реальному времени. Как упоминалось выше, он может противостоять сбоям, а также обеспечивает масштабируемость. Он использует функции пакетного уровня и потокового уровня и продолжает добавлять новые данные в основное хранилище, обеспечивая при этом сохранность существующих данных. Такие компании, как Twitter, Netflix и Yahoo, используют эту архитектуру для соответствия стандартам качества обслуживания.
Плюсы и минусы лямбда-архитектуры
Каппа Архитектура
В 2014 году Джей Крепс начал обсуждение, в котором указал на некоторые несоответствия архитектуры Lambda, которые в дальнейшем привели мир больших данных к другой альтернативной архитектуре, которая использовала меньше ресурсов кода и была способна хорошо работать в определенных корпоративных сценариях, где использование многоуровневой архитектуры Lambda казалось экстравагантность.
Архитектура Kappa не может рассматриваться как замена архитектуры Lambda, наоборот, ее следует рассматривать как альтернативу, которая будет использоваться в тех случаях, когда для обеспечения стандартного качества обслуживания не требуется активная производительность пакетного уровня. Эта архитектура находит применение в обработке различных событий в режиме реального времени. Вот базовая схема архитектуры Kappa, которая показывает двухуровневую систему работы для этой архитектуры обработки данных.

Давайте переведем последовательность операций архитектуры каппа в функциональное уравнение, которое определяет любой запрос в большой области данных.
Уравнение означает, что все запросы могут быть обработаны путем применения функции каппа к живым потокам данных на скоростном слое. Это также означает, что обработка потока происходит на скоростном уровне в архитектуре каппа.
Приложения архитектуры Kappa
Некоторые варианты приложений для социальных сетей, устройств, подключенных к облачной системе мониторинга, Интернета вещей (IoT), используют оптимизированную версию архитектуры Lambda, которая в основном использует службы скоростного уровня в сочетании с потоковым уровнем для обработки данных через озеро данных.
Архитектура Kappa может быть развернута для тех корпоративных моделей обработки данных, где:
Вышеупомянутые сценарии данных обрабатываются исчерпывающим Apache Kafka, который является чрезвычайно быстрым, отказоустойчивым и горизонтально масштабируемым. Это позволяет улучшить механизм управления потоками данных. Сбалансированное управление потоковыми процессорами и базами данных позволяет приложениям работать в соответствии с ожиданиями Кафка сохраняет упорядоченные данные в течение более продолжительного времени и обслуживает аналогичные запросы, связывая их с соответствующей позицией сохраненного журнала. LinkedIn и некоторые другие приложения используют эту разновидность обработки больших данных и получают выгоду от сохранения большого объема данных для обслуживания тех запросов, которые являются простой копией друг друга.
Плюсы и минусы каппской архитектуры
Pros
Cons
Отсутствие пакетного уровня может привести к ошибкам при обработке данных или при обновлении базы данных, что требует наличия диспетчера исключений для повторной обработки данных или сверки.
Вывод
Короче говоря, выбор между архитектурами Lambda и Kappa кажется компромиссом. Если вы ищете архитектуру, которая более надежна в обновлении озера данных, а также эффективна в разработке моделей машинного обучения для надежного прогнозирования наступающих событий, вам следует использовать архитектуру Lambda, поскольку она использует преимущества пакетного уровня и Скорость слоя, чтобы обеспечить меньше ошибок и скорости. С другой стороны, если вы хотите развернуть архитектуру больших данных с использованием менее дорогого оборудования и требовать от нее эффективной обработки на основе уникальных событий, происходящих во время выполнения, выберите архитектуру Kappa для своих нужд обработки данных в реальном времени.
Варианты архитектуры для обработки больших данных
Архитектура для обработки больших данных позволяет принимать, обрабатывать и анализировать данные, которые являются слишком объемными или слишком сложными для традиционных систем баз данных. Время, когда организации начинают использовать большие данные, зависит от возможностей пользователей и их средств. Для некоторых это могут быть сотни гигабайт данных, а для других — сотни терабайт. По мере совершенствования средств для работы с большими наборами данных изменяется и значение больших данных. Зачастую этот термин связан со значением, которое можно извлечь из наборов данных с помощью расширенной аналитики, а не исключительно с размером данных. Хотя в этих случаях они обычно достаточно большие.
С годами ландшафт данных изменился. Кроме того, появились новые возможности для работы с данными. Стоимость хранилища значительно снизилась, в то время как стоимость средств для сбора данных продолжает расти. Некоторые данные поступают в ускоренном темпе, их постоянно нужно собирать и просматривать. Другие данные поступают более медленно, но в очень больших блоках. Они часто содержат данные журналов за десятилетия. Вы может сталкиваться c проблемой расширенной аналитики или проблемой, для решения которой требуется использовать машинное обучение. Это задачи, которые архитектура для обработки больших данных предназначена решить.
Решения для обработки больших данных обычно предназначены для одного или нескольких из следующих типов рабочей нагрузки:
Используйте архитектуру для обработки больших данных для следующих сценариев:
Компоненты архитектуры для обработки больших данных
На схеме ниже показаны логические компоненты, которые входят в архитектуру для обработки больших данных. Отдельные решения могут не содержать все компоненты в этой схеме.

Большинство архитектур для обработки больших данных включают некоторые или все перечисленные ниже компоненты.
Источники данных. Все решения для обработки больших данных начинаются с одного или нескольких источников данных. Примеры приведены ниже:
Хранилище данных. Данные для пакетной обработки обычно хранятся в распределенном хранилище файлов, где могут содержаться значительные объемы больших файлов в различных форматах. Этот тип хранилища часто называют озером данных. Такое хранилище можно реализовать с помощью Azure Data Lake Store или контейнеров больших двоичных объектов в службе хранилища Azure.
Пакетная обработка. Так как наборы данных очень велики, часто в решении обрабатываются длительные пакетные задания. Для них выполняется фильтрация, статистическая обработка и другие процессы подготовки данных к анализу. Обычно в эти задания входит чтение исходных файлов, их обработка и запись выходных данных в новые файлы. Варианты: выполнение заданий U-SQL в Azure Data Lake Analytics, использование пользовательских заданий Hive, Pig или Map/Reduce в кластере HDInsight Hadoop и применение программ Java, Scala или Python в кластере HDInsight Spark.
Прием сообщений в реальном времени. Если решение содержит источники в режиме реального времени, в архитектуре должен быть предусмотрен способ сбора и сохранения сообщений в режиме реального времени для потоковой обработки. Это может быть простое хранилище данных с папкой, в которую входящие сообщения помещаются для обработки. Но для приема сообщений многим решениям требуется хранилище, которое можно использовать в качестве буфера. Такое хранилище должно поддерживать обработку с горизонтальным масштабированием, надежную доставку и другую семантику очереди сообщений. Эта часть архитектуры потоковой передачи часто называется потоковой буферизацией. Варианты: Центры событий Azure, Центр Интернета вещей и Kafka.
Потоковая обработка. Сохранив сообщения, поступающие в режиме реального времени, система выполняет для них фильтрацию, статистическую обработку и другие процессы подготовки данных к анализу. Затем обработанные потоковые данные записываются в выходной приемник. Azure Stream Analytics предоставляет управляемую службу потоковой обработки на основе постоянного выполнения запросов SQL для непривязанных потоков. Кроме того, для потоковой передачи можно использовать технологии Apache с открытым кодом, например Storm и Spark Streaming в кластере HDInsight.
Хранилище аналитических данных. Во многих решениях для обработки больших данных данные подготавливаются к анализу. Затем обработанные данные структурируются в соответствии с форматом запросов для средств аналитики. Хранилище аналитических данных, используемое для обработки таких запросов, может быть реляционной базой данных типа Kimball, как можно увидеть в большинстве традиционных решений бизнес-аналитики (BI). Кроме того, данные можно представить с помощью технологии NoSQL с низкой задержкой, такой как HBase или интерактивная база данных Hive, которая предоставляет абстракцию метаданных для файлов данных в распределенном хранилище. Azure Synapse Analytics — это управляемая служба для хранения больших объемов данных в облаке. HDInsight поддерживает Interactive Hive, HBase и Spark SQL, которые также можно использовать, чтобы предоставлять данные для анализа.
Анализ и создание отчетов. Большинство решений по обработке больших данных предназначены для анализа и составления отчетов, что позволяет получить важную информацию. Чтобы расширить возможности анализа данных, можно включить в архитектуру слой моделирования, например модель таблицы или многомерного куба OLAP в Azure Analysis Services. Также можно включить поддержку самостоятельной бизнес-аналитики с использованием технологий моделирования и визуализации в Microsoft Power BI или Microsoft Excel. Анализ и создание отчетов также может выполняться путем интерактивного изучения данных специалистами по их анализу и обработке. Для таких сценариев многие службы Azure поддерживают функции аналитического блокнота, например Jupyter, который позволяет пользователям применять свои навыки работы с Python или R. Для крупномасштабного изучения данных можно использовать Microsoft R Server (отдельно или со Spark).
Оркестрация. Большинство решений для обработки больших данных состоят из повторяющихся рабочих процессов, во время которых преобразуются исходные данные, данные перемещаются между несколькими источниками и приемниками, обработанные данные загружаются в хранилища аналитических данных либо же результаты передаются непосредственно в отчет или на панель мониторинга. Чтобы автоматизировать эти рабочие процессы, вы можете использовать технологию оркестрации, такую как фабрика данных Azure или Apache Oozie и Sqoop.
Лямбда-архитектура
При работе с очень большими наборами данных выполнение типа запросов, необходимых клиентам, может занять много времени. Эти запросы нельзя выполнить в режиме реального времени. Они часто требуют алгоритмов, например MapReduce, которые работают параллельно по всему набору данных. Результаты затем сохраняются отдельно от необработанных данных и используются для выполнения запросов.
Недостаток этого подхода заключается в том, что он вводит задержку — если обработка займет несколько часов, запрос может вернуть результаты, которые устарели в несколько часов. В идеале вам следует получить некоторые результаты в режиме реального времени (возможно, с некоторой потерей точности) и объединить их с результатами пакетной аналитики.
Лямбда-архитектура, впервые предложенная Натаном Марцом (Nathan Marz), устраняет эту проблему путем создания двух путей для потока данных. Все данные, поступающие в систему, проходят через эти два пути:
На пакетном уровне (холодный путь) все входящие данные хранятся в необработанном виде и выполняется их пакетная обработка. Результаты этой обработки сохраняются в пакетном представлении.
На уровне ускорения (критический путь) данные анализируются в режиме реального времени. Этот уровень обеспечивает минимальную задержку, хотя и за счет точности.
Пакетный уровень предоставляет результаты для уровня обслуживания, который индексирует пакетное представление для эффективного выполнения запросов. Уровень ускорения обновляет уровень обслуживания, отправляя добавочные обновления (с учетом последних данных).

Данные, которые поступают в критический путь, ограничены требованиями к задержке, наложенными уровнем ускорения, чтобы их можно было обработать как можно быстрее. Часто в этом случае следует обеспечить компромисс: некоторая потеря точности в пользу получения готовых данных как можно быстрее. Например, рассмотрите сценарий Интернета вещей, где большое количество датчиков температуры отправляют данные телеметрии. Уровень ускорения можно использовать для обработки скользящего временного окна входных данных.
На данные, которые поступают в холодный путь, с другой стороны, не распространяются те же требования к низкой задержке. Это обеспечивает высокую точность вычисления больших наборов данных, однако занимает много времени.
В результате критический и холодный пути объединяются в клиентском приложении аналитики. Если клиент должен отображать результаты своевременно, но потенциально с менее точными данными в режиме реального времени, он будет получать результаты из критического пути. В противном случае он будет выбирать результаты из холодного пути, чтобы отображать более точные данные, однако не так своевременно. Другими словами, критический путь содержит данные за относительно небольшой промежуток времени, после которого результаты можно обновить более точными данными из критического пути.
Необработанные данные, которые хранятся на пакетном уровне, являются неизменяемыми. Входящие данные всегда добавляются к имеющимся. Предыдущие данные никогда не перезаписываются. Любые изменения значения определенных данных хранятся в виде новой записи о событии с меткой времени. Это позволяет в любой момент времени выполнить повторное вычисление в журнале собранных данных. Возможность повторного вычисления пакетных представлений из исходных необработанных данных очень важна, так как это позволяет создавать представления по мере развития системы.
Каппа-архитектура
Недостатком лямбда-архитектуры является ее сложность. Логика обработки отображается в двух разных местах — холодных и критических путях, использующих разные платформы. Это приводит к дублированию логики вычислений и усложняет управление архитектурой для обоих путей.
Каппа-архитектура была предложена Джеем Крепсом (Jay Kreps) в качестве альтернативы лямбда-архитектуре. Она имеет такие же основные цели, что и лямбда-архитектура, но при этом есть важное различие: все данные проходят через один путь с использованием системы обработки потоковых данных.

Имеется некоторое сходство с пакетным уровнем лямбда-архитектуры. Оно заключается в том, что данные являются неизменяемыми. Кроме того, собираются все данные, а не только их подмножество. Данные принимаются как поток событий в распределенном и отказоустойчивом едином журнале. Эти события упорядочиваются, и текущее состояние события изменяется только при добавлении нового события. Аналогично уровню ускорения лямбда-архитектуры вся обработка событий выполняется во входном потоке и сохраняется как представление в режиме реального времени.
Если необходимо повторно вычислить весь набор данных (аналогично тому, что происходит на пакетном уровне в лямбда-архитектуре), просто воспроизведите поток. Чтобы завершить вычисление вовремя, обычно используется параллелизм.
Интернет вещей.
С практической точки зрения Интернет вещей представляет все устройства, подключенные к Интернету. Сюда входят ПК, мобильный телефон, умные часы, умный термостат, умный холодильник, подключенный автомобиль, импланты для кардиомониторинга и все остальные устройства, которые подключены к Интернету и отправляют или получают данные. Количество подключенных устройств растет каждый день, как и объем собираемых с них данных. Часто эти данные собираются в среды с большим количеством ограничений, а иногда и с высокой задержкой. В других случаях данные отправляются из сред с малой задержкой тысячами или миллионами устройств, требуя возможности быстро принимать данные и обрабатывать их соответствующим образом. Таким образом, чтобы работать с этими ограничениями и уникальными требованиями, требуется продуманное планирование.
Управляемые событиями архитектуры очень удобны при работе с решениями Интернета вещей. На следующей схеме представлены возможные варианты логической архитектуры для Интернета вещей. Особое внимание в этой схеме уделяется компонентам архитектуры для потоковой передачи событий.
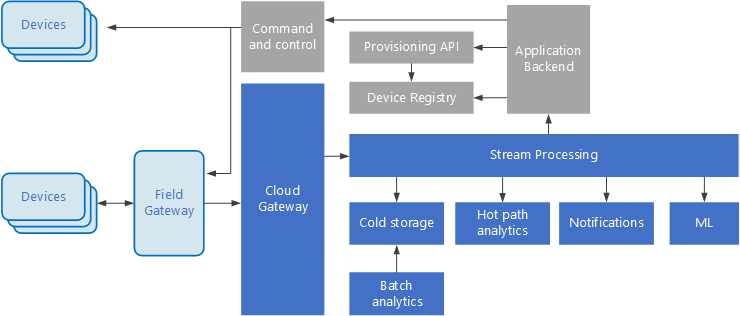
Облачный шлюз принимает события от устройств на границе облака, используя надежную службу сообщений с низкой задержкой.
Устройства могут отправлять события в облачный шлюз напрямую или через полевой шлюз. Полевой шлюз — это специальное устройство или программа, обычно размещаемые рядом с устройствами, которые получают события и пересылают их в облачный шлюз. Полевой шлюз может выполнять некоторую предварительную обработку событий, собираемых с устройств, например фильтрацию, статистическую обработку или преобразование протоколов.
Полученные события проходят через один или несколько обработчиков потока, которые передают данные в другие системы (например, хранилище данных) или выполняют аналитическую или другую обработку.
Ниже приводятся примеры типичных процессов обработки. (Очевидно, что этот список не является исчерпывающим.)
Сохранение данных о событиях в «холодное» хранилище для архивации или пакетной аналитики.
Аналитика критического пути, то есть анализ потока событий почти в режиме реального времени для обнаружения аномалий, выявления закономерностей в скользящих диапазонах времени или создания оповещений при выполнении определенных условий в потоке.
Обработка специальных типов сообщений, не относящихся к телеметрии, например уведомлений и тревожных сигналов.
Серые блоки обозначают компоненты системы Интернета вещей, не связанные напрямую с потоковой передачей событий. Они включены в схему для полноты представления.
Реестр устройств — это база данных о подготовленных устройствах, которая содержит идентификаторы устройств и некоторые метаданные, например расположение.
API подготовки — это общий внешний интерфейс для подготовки и регистрации новых устройств.
В некоторых решениях Интернета вещей допускается отправка управляющих сообщений на устройства.
Соответствующие службы Azure:
Дополнительные сведения об Интернете вещей в Azure см. в статье об эталонной архитектуре Интернета вещей Microsoft Azure.