Полигон и гистограмма
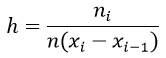
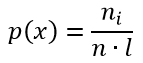
ni — частоты;
wi — относительные частоты;
n — объём выборки;
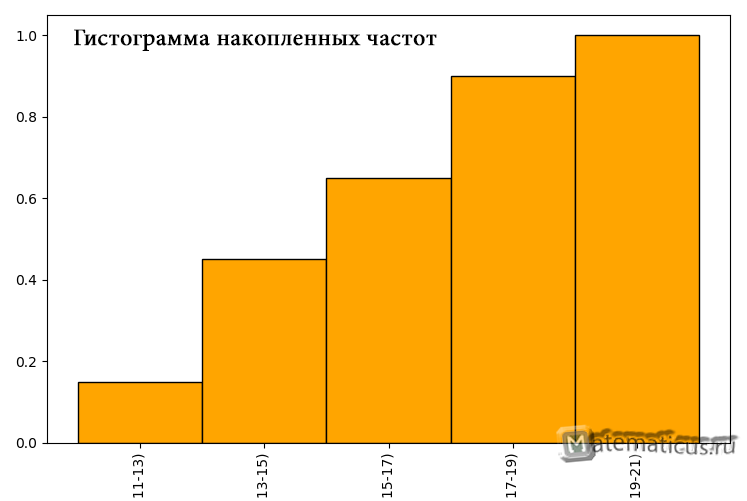
| Номер интервала | Абсолютная частота, ni | Частотный интервал |
| 1. | 3 | [11;13) |
| 2. | 6 | [13;15) |
| 3. | 4 | [15;17) |
| 4. | 5 | [17;19) |
| 5. | 2 | [19;21) |
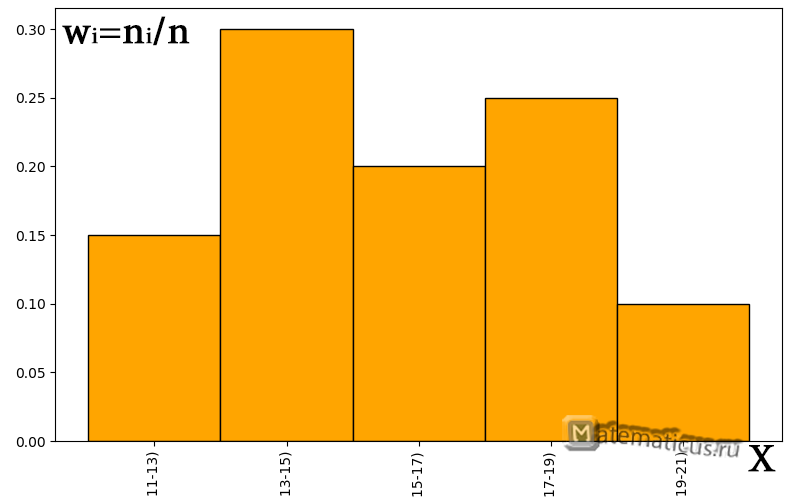
Таблица относительных частот и эмпирическая плотность распределения частоты
| Частотный интервал | Относительная частота, wi=ni/n | Эмпирическая плотность распределения частоты ni/ Δ |
| [11;13) | 0.15 | 1.5 |
| [13;15) | 0.3 | 3 |
| [15;17) | 0.2 | 2 |
| [17;19) | 0.25 | 0.25 |
| [19;21) | 0.1 | 0.1 |
График гистограммы абсолютных частот
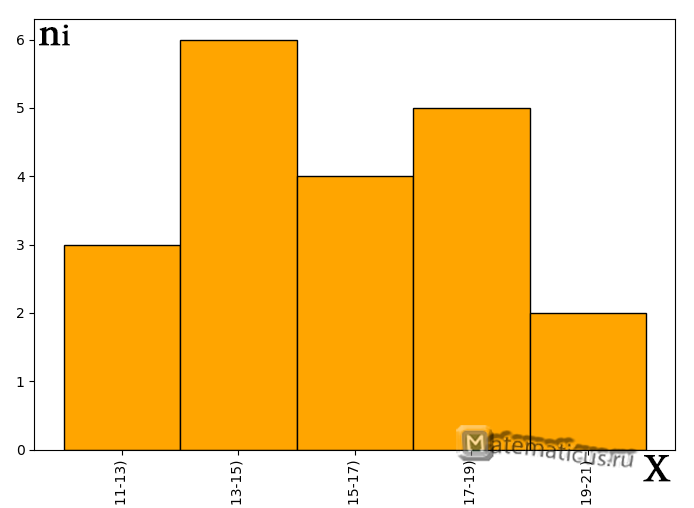
График гистограммы относительных частот
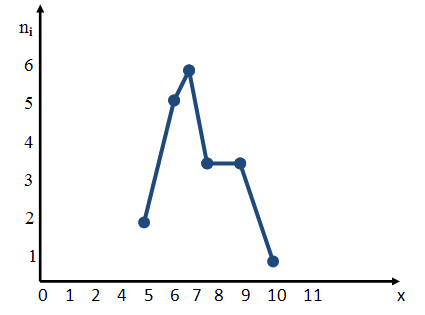
Для построения полигона частот на оси абсцисс откладывают варианты хi, а на оси ординат — соответствующие им частоты ni и соединяют точки.
Насколько публикация полезна?
Нажмите на звезду, чтобы оценить!
Средняя оценка 3.9 / 5. Количество оценок: 13
Полигон частот и гистограмма частот
Вы будете перенаправлены на Автор24
Полигон частот
Пусть нам дан ряд распределения, записанный с помощью таблицы:
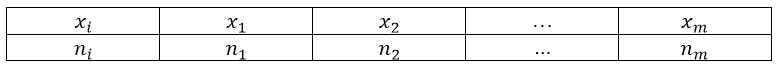
То есть, для построения полигона частот необходимо на оси абсцисс откладывают значения вариант, а по оси ординат соответствующие частоты. Полученные точки соединяют ломанной:
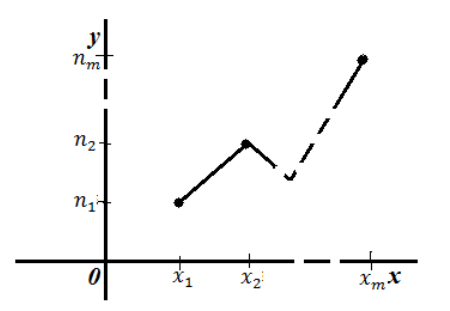
Рисунок 2. Полигон частот.
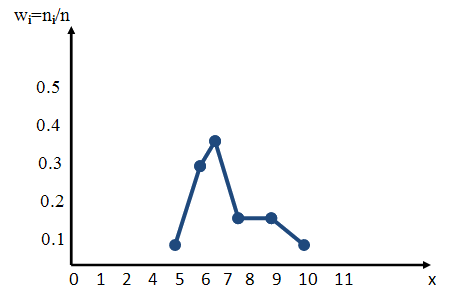
Помимо обычной частоты существует еще понятие относительной частоты.
Получаем следующую таблицу распределения относительных частот:
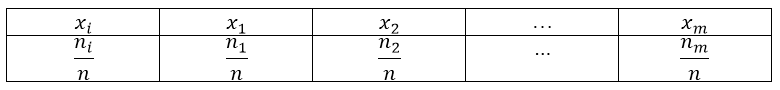
То есть, для построения полигона частот необходимо на оси абсцисс откладывают значения вариант, а по оси ординат соответствующие относительные частоты. Полученные точки соединяют ломанной:
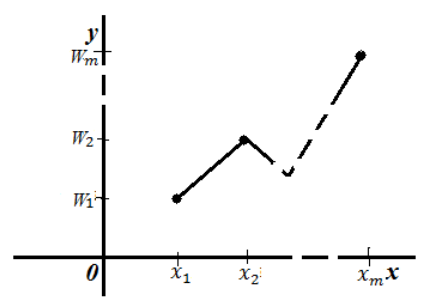
Рисунок 4. Полигон относительных частот.
Гистограмма частот
Помимо понятия полинома для непрерывных значений существует понятие гистограммы.
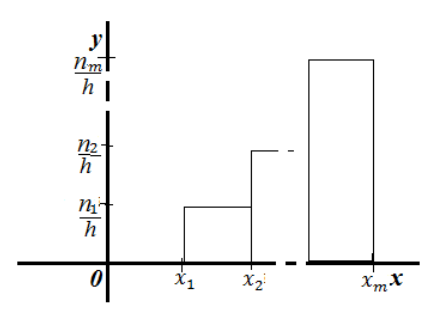
Рисунок 5. Гистограмма частот.
Готовые работы на аналогичную тему
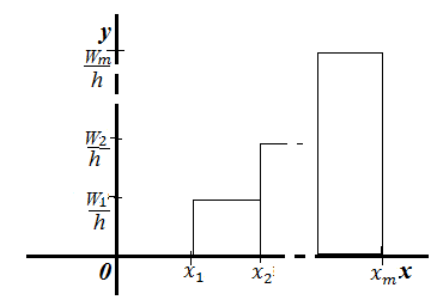
Рисунок 6. Гистограмма относительных частот.
Примеры задачи на построение полигона и гистограммы
Пусть распределение частот имеет вид:

Построить полигон относительных частот.

Получим следующий полигон относительных частот.
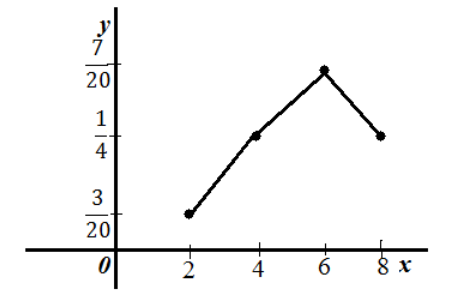
Дан ряд непрерывного распределения частот:

Группировка данных и построение ряда распределения
Виды статистических группировок
Принципы построения статистических группировок
При использовании персональных компьютеров для обработки статистических данных группировка единиц объекта производится с помощью стандартных процедур.
Одна из таких процедур основана на использовании формулы Стерджесса для определения оптимального числа групп:
Длину частичных интервалов вычисляют как h=(xmax-xmin)/k
Построить вариационный ряд. По найденному ряду построить полигон распределения, гистограмму, кумуляту. Определить моду и медиану.
Скачать решение
Пример. По результатам выборочного наблюдения (выборка А приложение):
а) составьте вариационный ряд;
б) вычислите относительные частоты и накопленные относительные частоты;
в) постройте полигон;
г) составьте эмпирическую функцию распределения;
д) постройте график эмпирической функции распределения;
е) вычислите числовые характеристики: среднее арифметическое, дисперсию, среднее квадратическое отклонение. Решение
Требуется: ранжировать ряд, построить интервальный ряд распределения, вычислить среднее значение, колеблемость среднего значения, моду и медиану для ранжированного и интервального рядов.
На основе исходных данных построить дискретный вариационный ряд; представить его в виде статистической таблицы и статистических графиков. 2). На основе исходных данных построить интервальный вариационный ряд с равными интервалами. Число интервалов выбрать самостоятельно и объяснить этот выбор. Представить полученный вариационный ряд в виде статистической таблицы и статистических графиков. Указать виды примененных таблиц и графиков.
С целью определения средней продолжительности обслуживания клиентов в пенсионном фонде, число клиентов которого очень велико, по схеме собственно-случайной бесповторной выборки проведено обследование 100 клиентов. Результаты обследования представлены в таблице. Найти:
а) границы, в которых с вероятностью 0.9946 заключено среднее время обслуживания всех клиентов пенсионного фонда;
б) вероятность того, что доля всех клиентов фонда с продолжительностью обслуживания менее 6 минут отличается от доли таких клиентов в выборке не более чем на 10% (по абсолютной величине);
в) объем повторной выборки, при котором с вероятностью 0.9907 можно утверждать, что доля всех клиентов фонда с продолжительностью обслуживания менее 6 минут отличается от доли таких клиентов в выборке не более чем на 10% (по абсолютной величине).
2. По данным задачи 1, используя X 2 критерий Пирсона, на уровне значимости α = 0,05 проверить гипотезу о том, что случайная величина Х – время обслуживания клиентов – распределена по нормальному закону. Построить на одном чертеже гистограмму эмпирического распределения и соответствующую нормальную кривую.
Скачать решение
Имеются следующие выборочные данные (выборка 10%-ная, механическая) о выпуске продукции и сумме прибыли, млн. руб. По исходным данным:
Задание 13.1.
13.1.1. Постройте статистический ряд распределения предприятий по сумме прибыли, образовав пять групп с равными интервалами. Постройте графики ряда распределения.
13.1.2. Рассчитайте числовые характеристики ряда распределения предприятий по сумме прибыли: среднюю арифметическую, среднее квадратическое отклонение, дисперсию, коэффициент вариации V. Сделайте выводы.
Задание 13.2.
13.2.1. Определите границы, в которых с вероятностью 0.997 заключена сумма прибыли одного предприятия в генеральной совокупности.
13.2.2. Используя x2-критерий Пирсона, при уровне значимости α проверить гипотезу о том, что случайная величина X – сумма прибыли – распределена по нормальному закону.
Задание 13.3.
13.3.1. Определите коэффициенты выборочного уравнения регрессии.
13.3.2. Установите наличие и характер корреляционной связи между стоимостью произведённой продукции (X) и суммой прибыли на одно предприятие (Y). Постройте диаграмму рассеяния и линию регрессии.
13.3.3. Рассчитайте линейный коэффициент корреляции. Используя t-критерий Стьюдента, проверьте значимость коэффициента корреляции. Сделайте вывод о тесноте связи между факторами X и Y, используя шкалу Чеддока.
Методические рекомендации. Задание 13.3 выполняется с помощью этого сервиса.
Скачать решение
Задача. Следующие данные представляют собой затраты времени клиентов на заключение договоров. Построить интервальный вариационный ряд представленных данных, гистограмму, найти несмещенную оценку математического ожидания, смещенную и несмещенную оценку дисперсии.
Решение:
Для построения группировка с равными интервалами воспользуемся сервисом Группировка статистических данных.
2. Дискретный вариационный ряд.
Полигон частот и эмпирическая функция распределения
На вводном уроке по математической статистике мы узнали, что такое математическая статистика, и теперь обо всём подробнее. Далее для удобства я буду нумеровать статьи и постараюсь делать их не слишком длинными. Потому что всё действительно просто, и главное, здесь научиться рациональной технике вычислений, на которую и будет сделан особый упор.
Интервальные и дискретные вариационные ряды почти сразу же встретились в предыдущей статье, и мы начинаем с дискретного случая, когда количественная эмпирическая величина 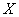 может принимать лишь отдельные изолированные значения.
может принимать лишь отдельные изолированные значения.
…что-то не понятно по терминам? Срочно изучать первый урок! (ссылка выше)
Дискретный вариационный ряд – это упорядоченное по возрастанию (как правило) множество вариант 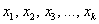 (значений величины
(значений величины 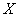 ) и соответствующих им частот либо относительных частот.
) и соответствующих им частот либо относительных частот.
Частоты выборочной совокупности обозначают через 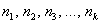 , частоты генеральной совокупности – через
, частоты генеральной совокупности – через 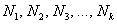 . И сразу разбираемся с новым термином. Относительные частоты рассчитываются по формулам:
. И сразу разбираемся с новым термином. Относительные частоты рассчитываются по формулам:
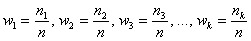 , где
, где 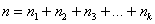 – объем выборки, при этом, сумма всех относительных частот:
– объем выборки, при этом, сумма всех относительных частот: 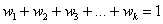 .
.
Аналогично для совокупности генеральной: 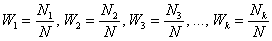 , где
, где 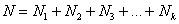 – её объем, и, очевидно:
– её объем, и, очевидно: 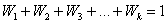
И тут вспоминается Пример 2 об оценках по матанализу в группе из 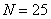 студентов:
студентов: 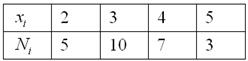
– пожалуйста, пример дискретного вариационного ряда, где варианты 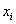 – это оценки, а частоты
– это оценки, а частоты 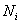 – количество студентов, получивших ту или иную оценку.
– количество студентов, получивших ту или иную оценку.
Для разминки найдём относительные частоты: 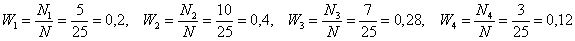
и непременно проконтролируем, что: 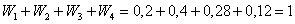 .
.
Все вычисления обычно проводят на калькуляторе либо в Экселе, а результаты заносят в таблицу, при этом, в статистике данные чаще располагают не в строках, а в столбцах: 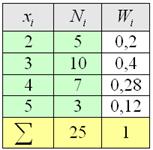
Такое расположение обусловлено тем, что количество вариант может быть достаточно велико, и они просто не вместятся в строчку. Не редкость, когда их 10-20, а бывает, и 100-200, что тоже и неоднократно встречалось в моей практике. И это не какие-то супер-пупер расчёты, а учебные задачи!
После сей позитивной новости продолжаем 🙂
Откуда берутся дискретные вариационные ряды? Такие ряды появляются в результате учёта дискретной характеристики статистической совокупности, причём, варианты ряда не отличаются большим разнообразием. Например, оценки (коих не так много) в примере выше.
И сейчас мы примем непосредственное участие в этом процессе:
По результатам выборочного исследования рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4, 4, 5, 2, 3, 3, 4, 5, 5, 2, 3, 6, 5, 4, 6, 4, 3. Требуется:
– составить вариационный ряд и построить полигон частот;
– найти относительные частоты и построить эмпирическую функцию распределения.
Чего томиться? – вся тема урока в одной задаче!
Решение: в условии прямо сказано о том, что перед нами выборка из генеральной совокупности (всех рабочих цеха), и первое, что логично сделать – подсчитать её объем, т.е. количество рабочих. В данном случае это легко сделать устно: 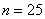 .
.
Квалификационные разряды – есть величина дискретная, и поэтому нам предстоит составить дискретный вариационный ряд (обратите внимание, что в условии ничего не сказано о характере ряда).
Если у вас под рукой нет вычислительных программ, то вручную (Эксель разберём ниже). При этом оптимальным может быть следующий алгоритм: сначала окидываем взглядом все числа и определяем среди них минимальное (примерно) и максимальное (примерно). В данном случае ориентировочный диапазон – от 1 до 7. Записываем их в столбец на черновике и обводим в кружочки. Далее начинаем вычёркивать карандашом числа из исходного списка: 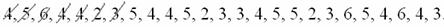
и делать около соответствующих кружков засечки: 
После того, как все числа будут вычеркнуты, подсчитываем количество засечек в каждой строке: 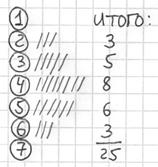
И обязательно проверяем, получается ли у нас в сумме объём выборки 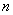 :
: 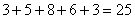 , отлично, искомый ряд составлен, заносим полученные значения в таблицу на чистовик:
, отлично, искомый ряд составлен, заносим полученные значения в таблицу на чистовик: 
…ну что же, вполне и вполне логично – рабочих средней квалификации много, а учеников и мастеров – мало. Полученные результаты позволяют достаточно точно судить об уровне квалификации всего цеха (если, конечно, выборка представительна)
Построенный вариационный ряд также называют статистическим распределением выборки, причём, этот термин применИм не только для дискретного, но и для интервального ряда, который мы рассмотрим на следующем уроке.
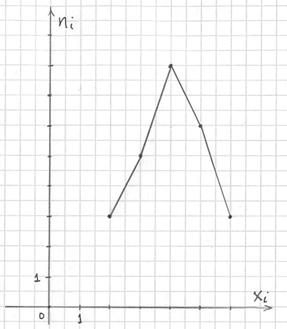
Построим полигон частот. Это статистический аналог многоугольника распределения дискретной случайной величины (кто изучал). Полигон частот – это ломаная, соединяющая соседние точки 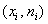 :
: 
…эх, ностальгия. Но, пятилетку-другую, думается, так решать ещё будут.
Теперь современный способ:
Решаем! – исходные данные с пошаговой инструкцией прилагаются.
Вторая часть задачи. Найдём относительные частоты 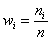 , для этого каждую частоту
, для этого каждую частоту 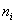 делим на
делим на  и результат заносим в дополнительный столбец, далее я перехожу к электронной версии:
и результат заносим в дополнительный столбец, далее я перехожу к электронной версии: 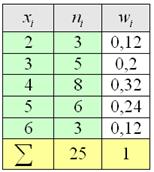
– обязательно проверяем, что сумма относительных частот равна единице!
Иногда требуется построить полигон относительных частот. Как вы правильно догадываетесь – это ломаная, соединяющая соседние точки  . Но такое задание больше характерно для интервального вариационного ряда.
. Но такое задание больше характерно для интервального вариационного ряда.
А теперь посмотрим на относительные частоты и задумаемся, на что они похожи? …Правильно, на вероятности. Так, например, можно сказать, что 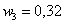 – есть примерная вероятность того, что наугад выбранный рабочий цеха будет иметь 4-й разряд. «Примерная» – по той причине, что перед нами выборка.
– есть примерная вероятность того, что наугад выбранный рабочий цеха будет иметь 4-й разряд. «Примерная» – по той причине, что перед нами выборка.
А вот если учесть ВСЕХ рабочих цеха (всю генеральную совокупность), то рассчитанные относительные частоты 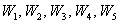 – и есть в точности эти вероятности.
– и есть в точности эти вероятности.
Построим эмпирическую функцию распределения 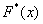 . Это статистический аналог функции распределения из тервера. Данная функция определяется, как отношение:
. Это статистический аналог функции распределения из тервера. Данная функция определяется, как отношение:
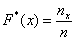 , где
, где 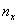 – количество вариант СТРОГО МЕНЬШИХ, чем
– количество вариант СТРОГО МЕНЬШИХ, чем 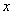 ,
,
при этом «икс» «пробегает» все значения от «минус» до «плюс» бесконечности.
Очевидно, что на интервале 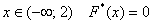 , и, кроме того, функция равна нулю ещё и в точке
, и, кроме того, функция равна нулю ещё и в точке 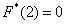 . Почему? Потому, что значение
. Почему? Потому, что значение 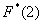 определяет количество вариант, которые СТРОГО меньше двух, а это количество равно нулю.
определяет количество вариант, которые СТРОГО меньше двух, а это количество равно нулю.
На промежутке 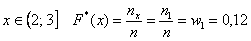 – и опять обратите внимание, что значение
– и опять обратите внимание, что значение 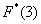 не учитывает рабочих 3-го разряда, т.к. речь идёт о вариантах, которые СТРОГО меньше трёх.
не учитывает рабочих 3-го разряда, т.к. речь идёт о вариантах, которые СТРОГО меньше трёх.
На промежутке 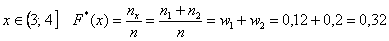 и далее процесс продолжается по принципу накопления частот:
и далее процесс продолжается по принципу накопления частот:
– если 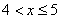 , то
, то  ;
;
– если 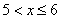 , то
, то 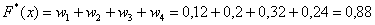 ;
;
– и, наконец, если 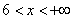 , то
, то 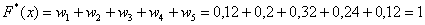 – и в самом деле, для ЛЮБОГО «икс» из интервала
– и в самом деле, для ЛЮБОГО «икс» из интервала 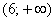 ВСЕ частоты расположены СТРОГО левее этого «икс».
ВСЕ частоты расположены СТРОГО левее этого «икс».
Накопленные относительные частоты удобно записывать в отдельный столбец таблицы, при этом алгоритм вычислений очень прост: сначала сносим слева 1-е значение (красная стрелка), а каждое следующее получаем как сумму предыдущего и относительной частоты из текущего левого столбца (зелёные обозначения): 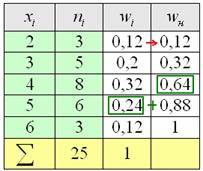
Вот, кстати, ещё один довод за вертикальную ориентацию данных – справа по надобности можно приписывать дополнительные столбцы.
Саму функцию принято записывать в кусочном виде: 
а её график представляет собой ступенчатую фигуру: 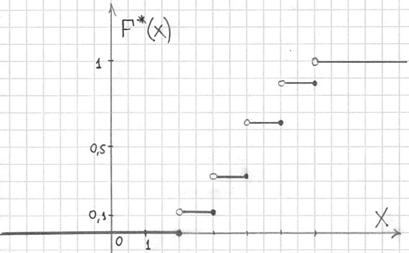
Эмпирическая функция распределения не убывает и принимает значения из промежутка 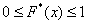 , и если у вас вдруг получится не так, то ищите ошибку.
, и если у вас вдруг получится не так, то ищите ошибку.
И сейчас мы автоматизируем процесс; видео, к сожалению, не вписалось по ширине, посему смотрим его на Ютубе:
 Как построить эмпирическую функцию распределения?
Как построить эмпирическую функцию распределения?
Эмпирическая функция распределения 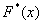 строится по выборке и приближает теоретическую функцию распределения
строится по выборке и приближает теоретическую функцию распределения 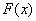 . Легко догадаться, что последняя образуется на основании исследования всей генеральной совокупности, но если рабочих в цехе ещё пересчитать можно, то звёзды на небе – уже вряд ли. Вот поэтому и важнА именно эмпирическая функция, и ещё важнее, чтобы выборка была репрезентативна, дабы приближение было хорошим.
. Легко догадаться, что последняя образуется на основании исследования всей генеральной совокупности, но если рабочих в цехе ещё пересчитать можно, то звёзды на небе – уже вряд ли. Вот поэтому и важнА именно эмпирическая функция, и ещё важнее, чтобы выборка была репрезентативна, дабы приближение было хорошим.
Миниатюрная задача для закрепления материала:
Дано статистическое распределение выборки 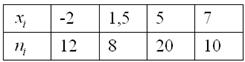
Составить эмпирическую функцию распределения, выполнить чертёж
Самостоятельно решить Пример 5 в Экселе, все числа и обозначения уже там.
Свериться с образцом можно ниже. По поводу красоты чертежа сильно не запаривайтесь, главное, чтобы было правильно – этого обычно достаточно для зачёта.
И я жду вас на третьем уроке, где речь пойдёт об интервальном вариационном ряде.
Пример 5. Решение: заполним расчётную таблицу: 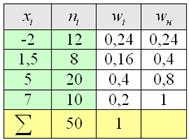
Составим эмпирическую функцию распределения: 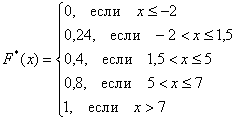
Выполним чертёж: 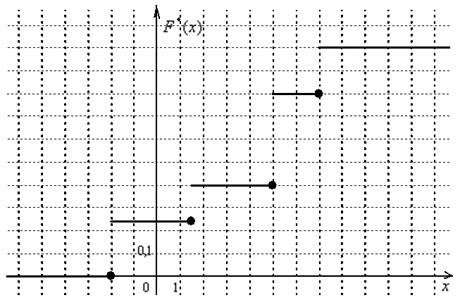
Автор: Емелин Александр
(Переход на главную страницу)
 Zaochnik.com – профессиональная помощь студентам
Zaochnik.com – профессиональная помощь студентам
cкидкa 15% на первый зaкaз, прoмoкoд: 5530-hihi5
Tutoronline.ru – онлайн репетиторы по математике и другим предметам