SQL-Ex blog
Новости сайта «Упражнения SQL», статьи и переводы
Получение плана выполнения запроса в PostgreSQL
Введение
Сгенерировать план выполнения запроса позволяет ключевое слово EXPLAIN в PostgreSQL. Синтаксис создания плана в PostgreSQL имеет вид:
Для этой команды OPTION имеется много вариантов. Множественный выбор осуществляется перечислением через запятую. Вот эти варианты:
Значение Boolean может быть TRUE или FALSE. Вместо TRUE можно использовать ON или 1. Аналогично для FALSE используются OFF или 0.
Очень простой план выполнения запроса выглядит так:
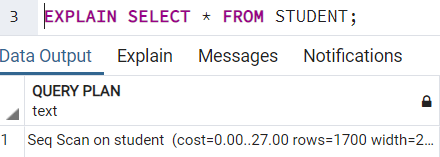
Объяснение синтаксиса
Прежде чем использовать EXPLAIN для генерации плана выполнения запроса, необходимо узнать об особенностях синтаксиса.
ANALYZE
Когда вы используете ключевое слово EXPLAIN, сначала выполняется ваш запрос PostgreSQL. После успешного выполнения запроса возвращается вся статистика времени выполнения, включая полное время на каждый узел плана и общее число строк, прочитанных запросом. Ключевое слово ANALYZE будет фактически выполнять запрос в реальном времени для сбора и подготовки плана выполнения. Поэтому, если вы выполняете следующий запрос:
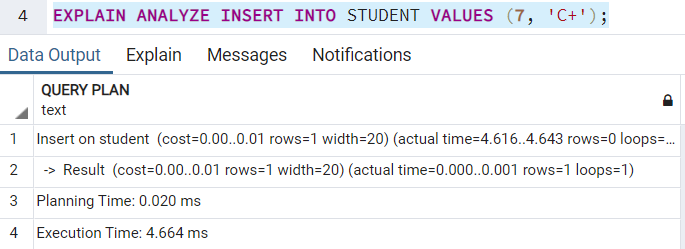
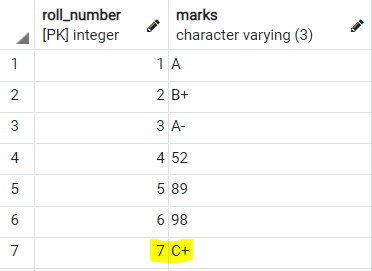
то строки на самом деле вставляются в таблицу:
VERBOSE
Это ключевое слово покажет дополнительную информацию, связанную с планом выполнения запроса. Эта опция по умолчанию имеет значение FALSE. Чтобы установить её в TRUE, можно написать:
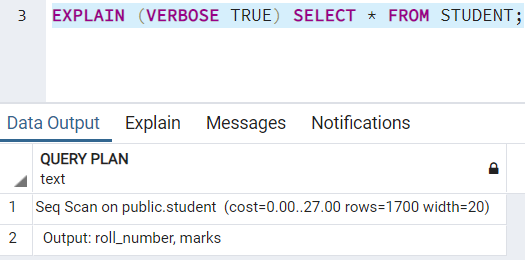
COSTS
Опция COSTS вернет значение стоимости каждого шага в запросе. Сделанные оценки представляют собой произвольные значения, которые присваиваются каждому шагу при выполнении любого запроса на основе ожидаемой нагрузки на ресурсы, которую он может создать. Значение по умолчанию всегда установлено в TRUE. Вы можете использовать это ключевое слово в плане выполнения своего запроса так:
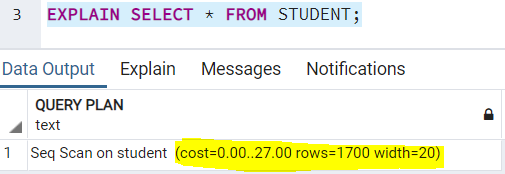
BUFFERS
Это ключевое слово имеет зависимость от ключевого слова ANALYZE, и может использоваться только вместе с ним. Значением по умолчанию является FALSE. Вы можете использовать его в плане выполнения своего запроса таки образом:
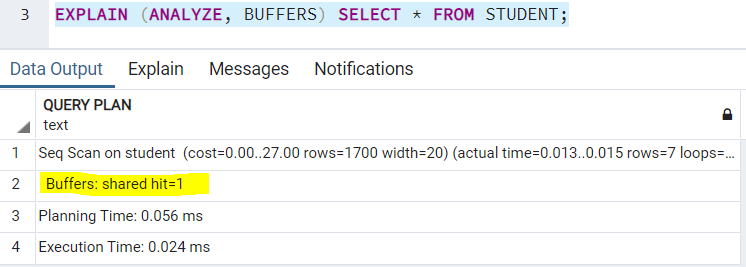
Замечание. Так как мы ранее выполняли этот запрос многократно (обсуждая другие ключевые слова), буферы показывают только разделяемые обращения, т.к. результаты находились в кэше. Если выполнить запрос с новым предложением WHERE, появятся также и разделяемые чтения.
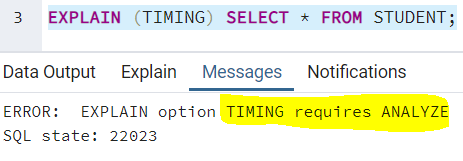
TIMING
TIMING детализирует время запуска и время выполнения на каждом узле. Значением по умолчанию является TRUE. Для его использования должно применяться ключевое слово ANALYZE. Если вы попытаетесь использовать ключевое слово TIMING без ANALYZE, то получите следующую ошибку:
План выполнения с включенным TIMING будет выглядеть так:
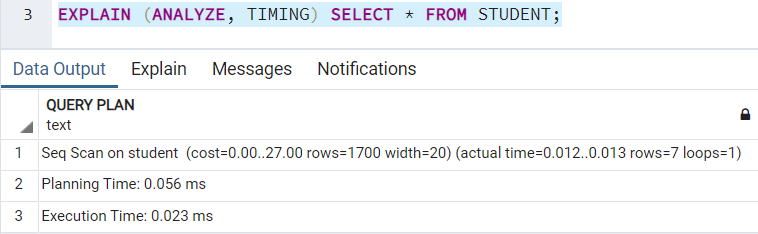
План выполнения с выключенным TIMING имеет вид:
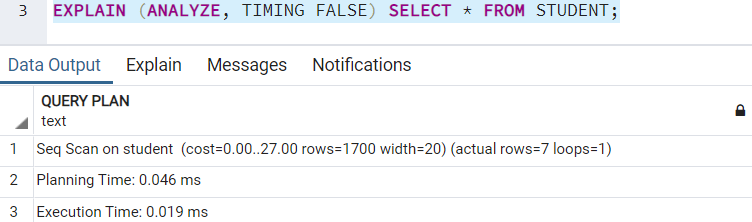
SUMMARY
Это ключевое слово добавляет итоговую информацию в план выполнения запроса. Вы можете использовать его вместе с ключевым словом ANALYZE. По умолчанию план запроса включает его. Если вы захотите выключить эту опцию, сделайте так:
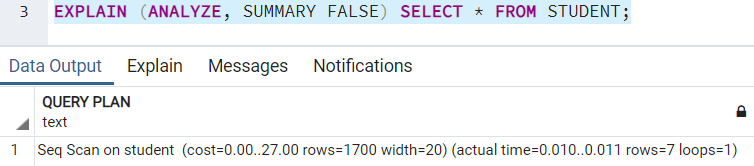
FORMAT
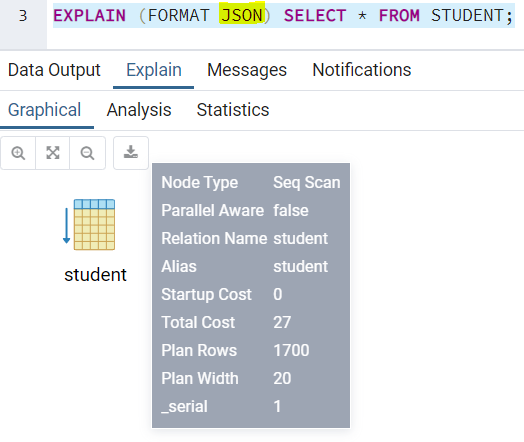
Примеры
Мы уже представили много примеров выше. При этом использовался очень простой запрос. Давайте воспользуемся более близкими к реальным запросами, как те, которые используют предложение WHERE или JOIN.
Предположим, что нам нужно посмотреть план выполнения для запроса, который выводит информацию о студенте с номером 5. План выглядит так:
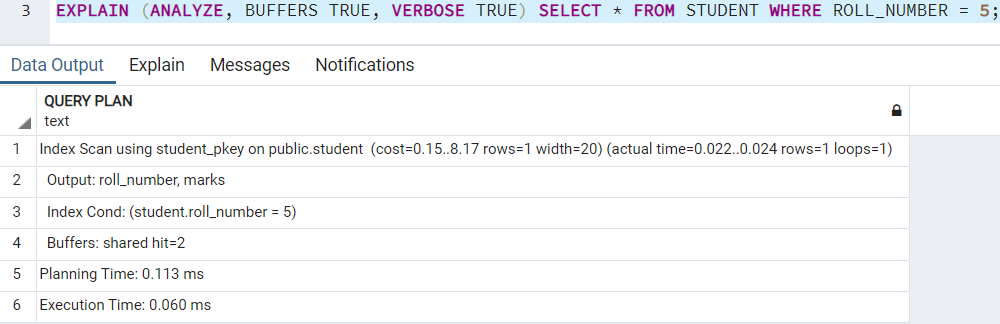
Выясним, нужны ли вам VERBOSE и BUFFERS в плане выполнения. Если необходимо проверить выходные столбцы, вы можете использовать VERBOSE. Если требуется проверить, сколько блоков было прочитано с диска, а сколько из кэша, можно использовать BUFFERS.
Теперь предположим, что нам требуется соединить 2 таблицы (например, student [содержащую номер и оценки] и home [содержащую номер, город проживания и штат]) и вернуть информацию пользователю. Тогда план выполнения будет такой:
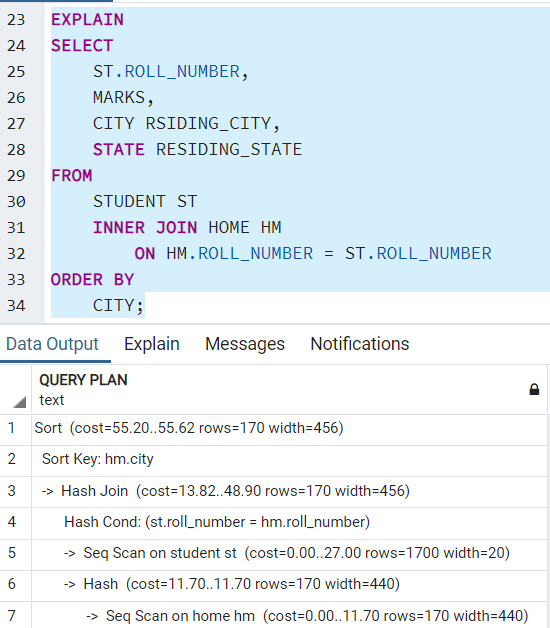
Заключение
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись
SQL-Ex blog
Новости сайта «Упражнения SQL», статьи и переводы
Анатомия плана запроса в PostgreSQL
Начинать оптимизацию запроса следует с планировщика запросов (Query Planner). В этой статье объясняется, как выполняется запрос, и как понимать команду EXPLAIN.
Введение
Понимание плана запроса в PostgreSQL является критичным навыком для разработчиков и администраторов баз данных. Это, вероятно, первое, на что мы должны обратить внимание в начале оптимизации запроса, а также первая вещь для проверки того, действительно ли ваш оптимизированный запрос оптимизирован так, как вы ожидали.
Жизненный цикл запроса в базе данных PostgreSQL
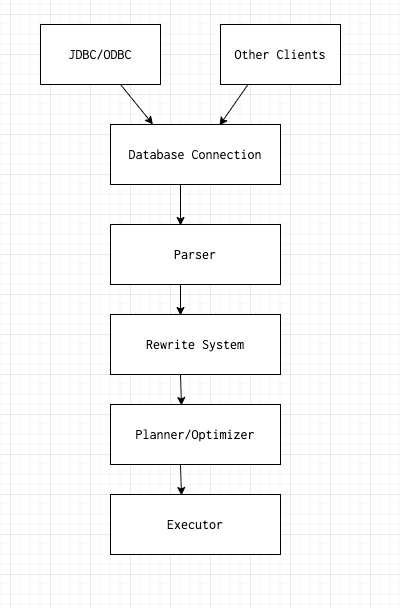
Диаграмма жизненного цикла запроса в PostgreSQL
Вторая фаза предназначена для трансляции запроса в промежуточный формат, известный как дерево разбора. Обсуждение внутреннего устройства дерева разбора выходит за рамки настоящей статьи, но вы можете представить себе это как скомпилированную форму запроса SQL.
Третья фаза это то, что мы называем системой перезаписи системы/правил. Она берет дерево разбора, сгенерированное на втором этапе, и переписывает его в виде, с которым может начать работать планировщик/оптимизатор.
Четвертая фаза является наиболее важной, это сердце базы данных. Без планировщика исполнительный механизм будет решать вслепую, как выполнить запрос, какие индексы использовать, стоит ли сканировать небольшие таблицы для исключения уже ненужных строк и т.д. Это стадия как раз будет обсуждаться в этой статье.
Установка данных
Давайте установим некую фиктивную таблицу с тестовыми данными для выполнения экспериментов.

Затем наполним эту таблицу данными. Я использовал скрипт Python, приведенный ниже, для генерации случайных строк.
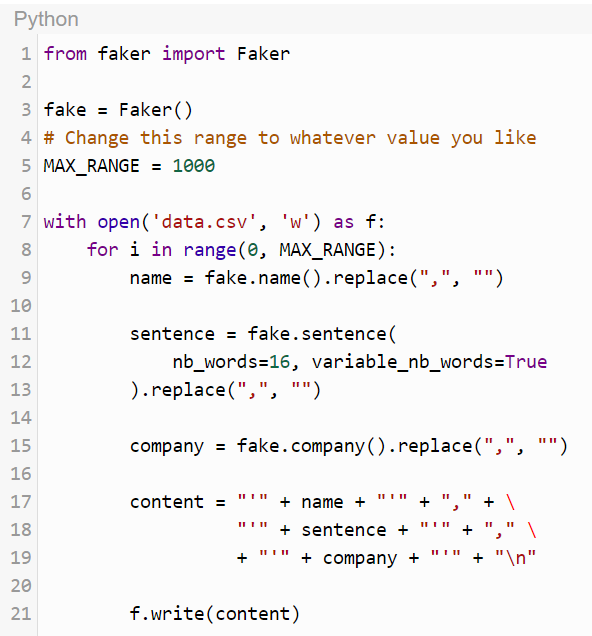
Скрипт использует библиотеку Faker для генерации тестовых данных. Он генерирует csv файл на корневом уровне, который может быть импортирован как обычный csv в PostgreSQL при помощи следующей команды.

Поскольку id есть serial, он будет автоматически заполняться самим PostgreSQL.

Теперь таблица содержит 1119284 записей.
Большинство последующих примеров будут основаны на этой таблице. Она намеренно сделана простой, чтобы сфокусироваться на процессе, а не на сложности таблицы/данных.
Переходим к этапу планирования
PostgreSQL и многие другие системы баз данных позволяют пользователям видеть то, что фактически происходит под капотом на этапе планирования. Мы можем сделать это, выполняя то, что называется командой EXPLAIN (объяснить).
ОБЪЯСНЕНИЕ запроса в PostgreSQL
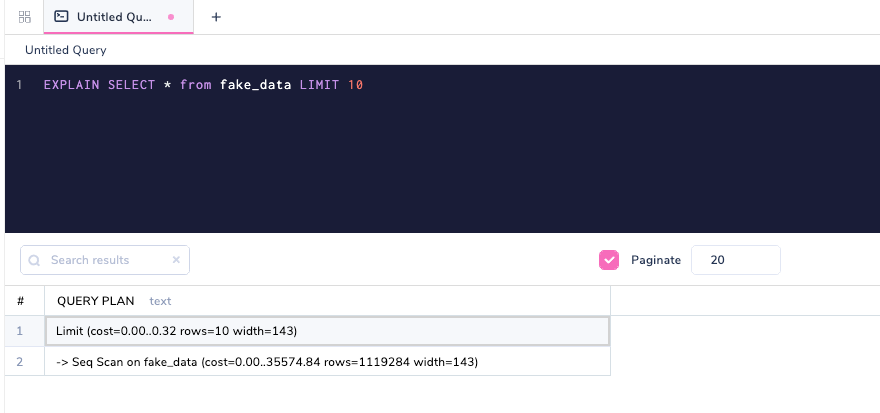
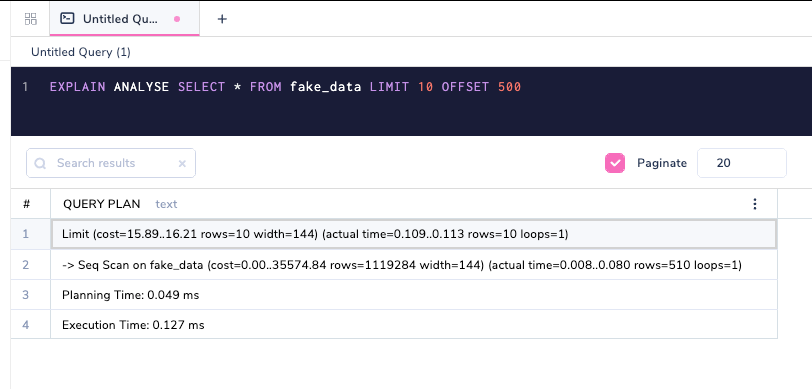
При использовании EXPLAIN вы можете посмотреть планы запросов до их фактического выполнения базой данных. Мы перейдем к пониманию каждого из них ниже, но давайте сначала взглянем на другую расширенную версию EXPLAIN, которая называется EXPLAIN ANALYSE.
Объяснение и анализ вместе
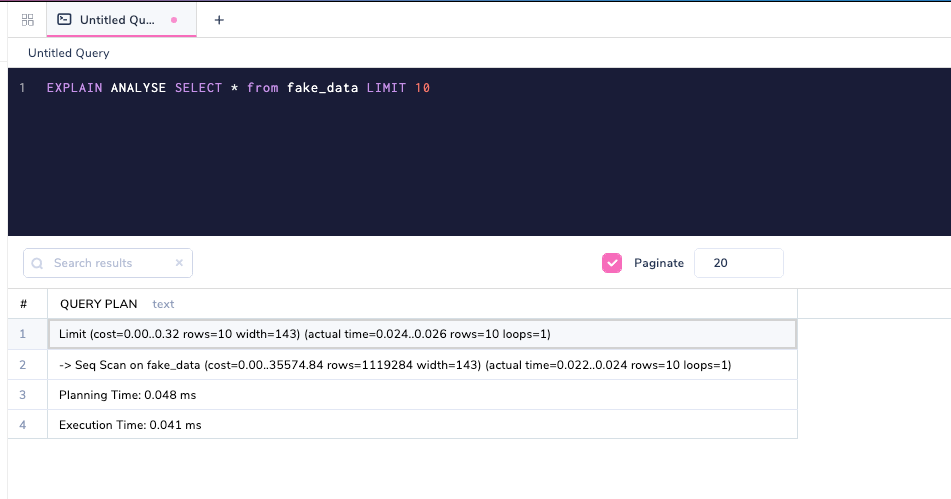
Добавление аргумента ANALYZE к запросам выводит информацию о времени.
В отличие от EXPLAIN, EXPLAIN ANALYSE фактически выполняет запрос в базе данных. Этот вариант весьма полезен для понимания ситуации, когда планировщик играет свою партию неверно; т.е. имеется ли огромное различие в генерируемом плане между EXPLAIN и EXPLAIN ANALYSE.
Что такое буферы и кэши в базах данных?
Давайте перейдем к более интересной метрике, которая называется BUFFERS. Она объясняет как много данных приходит из кэша PostgreSQL и как много считывается с диска.
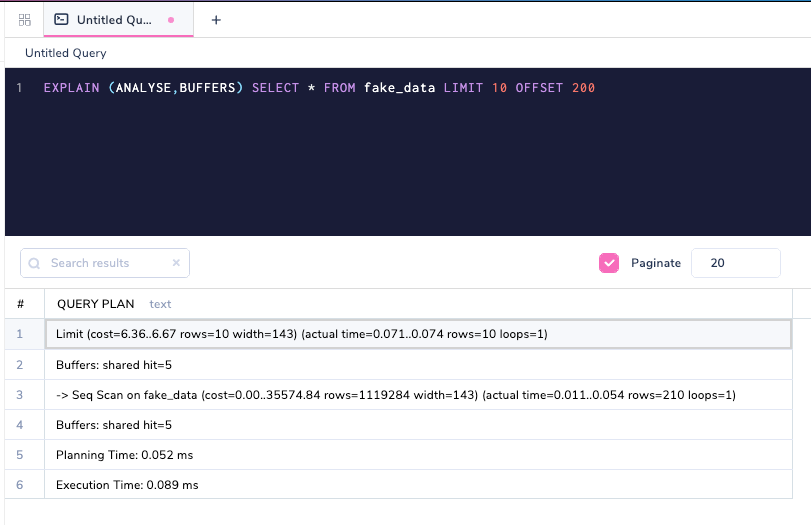
Включение BUFFERS в качестве аргумента показывает, сколько страниц попадает в запрос.
Buffers : shared hit=5 означает, что пять страниц было извлечено из кэша самого PostgreSQL. Давайте настроим смещение в запросе для получения отличных строк.
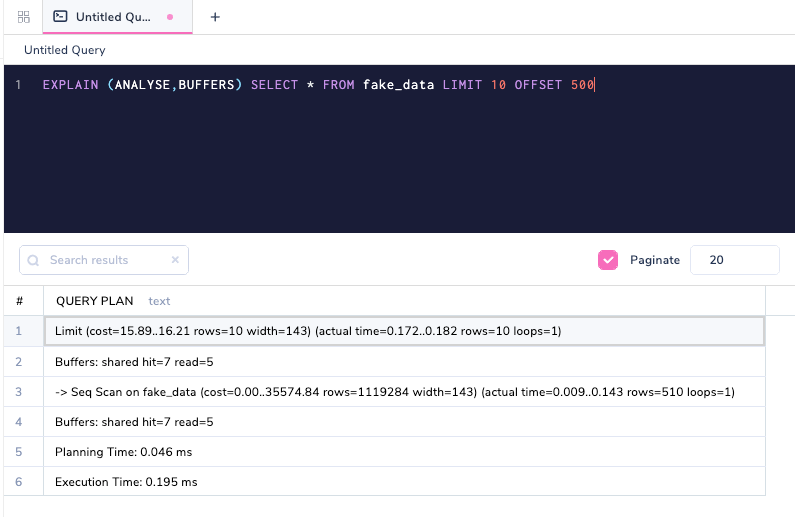
Изменение OFFSET приводит к отличающемуся числу запросов страниц.
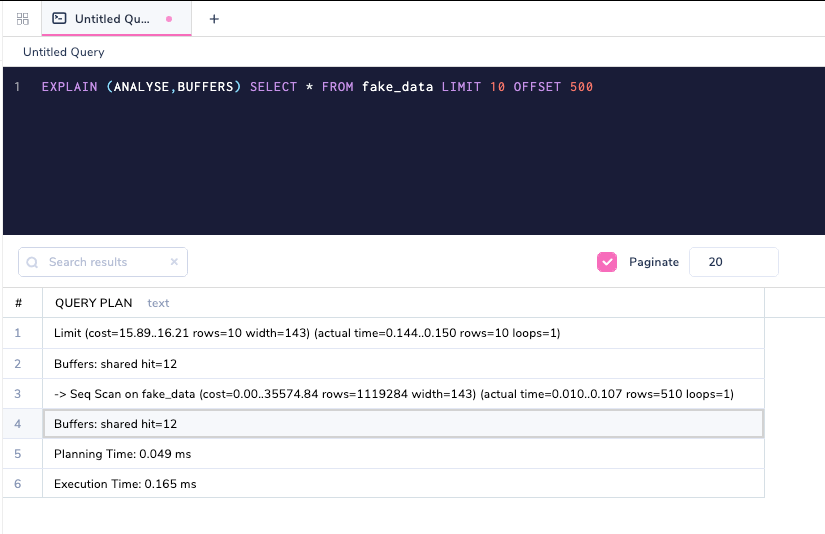
Повторное выполнение запроса показывает, что кэш теперь предоставляет все результаты.
Аргумент команды VERBOSE
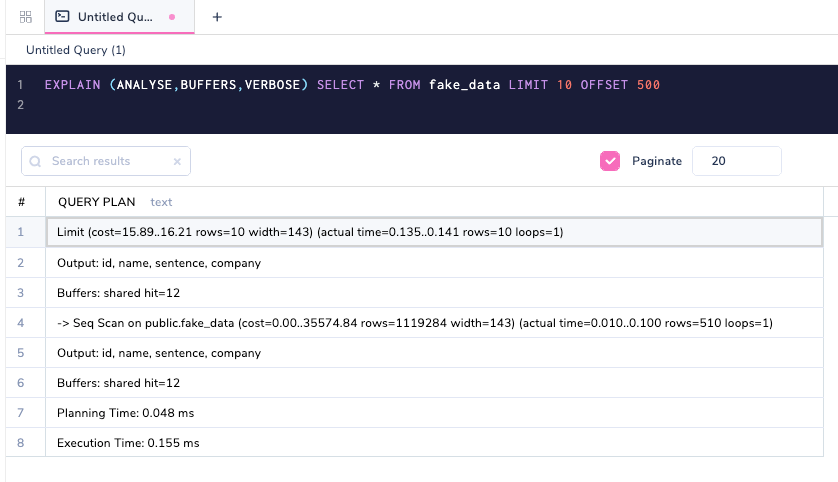
Аргумент команды VERBOSE даст еще больше информации для сложного запроса.
Заметим, что Output: id, name, sentence, company является дополнительным. В плане сложного запроса будет много другой информации, которая будет напечатана. По умолчанию опции COSTS и TIMING установлены в TRUE, и нет необходимости указывать их явно, если вы не захотите их отключить (FALSE).
FORMAT в объяснении PostgreSQL
PostgreSQL имеет возможность представлять план в замечательном формате, таком как JSON, поэтому эти планы могут интерпретироваться независимым от языка способом.

Этот запрос напечатает план запроса в формате JSON. Вы можете просмотреть этот формат в Arctype, скопировав его вывод и вставив его в другую таблицу, как показано ниже в GIF.
Вставка вывода EXPLAIN JSON в таблицу, и использование просмотра JSON для проверки.
Элементы плана запроса
Любой план запроса вне зависимости от сложности обладает некоторой фундаментальной структурой. В этом разделе мы сфокусируем внимание на этих структурах, которые помогут нам понять план запроса в абстрактной манере.
Узлы запроса
Узел можно представлять себе как этап выполнения запроса базой данных. Узлы зачастую являются вложенными, как показано выше; Seq Scan выполняется раньше, после чего применяется предложение Limit. Давайте добавим предложение Where, чтобы понять дальнейшее вложение.
Стоимость в планировщике запросов
Стоимости являются решающей частью плана запроса к базе данных, и они легко могут быть неправильно поняты из-за того, в каком виде они представлены. Давайте посмотрим снова на простой план со стоимостью.
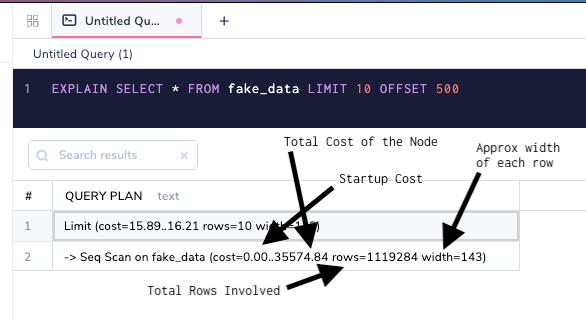
Стоимость представлена внутри вывода EXPLAIN.
Планирование и выполнение базой данных
Куда двигаться дальше
Мы прошли путь от рассмотрения жизненного цикла запроса до того, как планировщик принимает свои решения. Я намеренно не касался таких вопросов, как типы узлов (сканирование, сортировка, соединения), поскольку каждый из них требует отдельной статьи. Целью настоящей статьи является дать общее понимание того, как работает планировщик, что влияет на его решения и какие инструменты предоставляет PostgreSQL для лучшего понимания планировщика.
Давайте вернемся к вопросам, которые мы задавали выше.
Q: Разве PostgreSQL недостаточно умен, чтобы оптимизировать мои запросы автоматически? Почему я должен беспокоиться о планировщике?
A: PostgreSQL действительно умен настолько, насколько это возможно. Планировщик становится лучше и лучше с каждым релизом, но не существует такого полностью автоматизированного/совершенного планировщика. В действительности это непрактично, т.к. оптимизация может быть хорошей для одного запроса, но плохой для другого. Планировщик должен где-то прочертить линию и обеспечить согласованное поведение и производительность. Большая ответственность лежит на разработчиках/администраторах баз данных, чтобы писать оптимизированные запросы и лучше понимать поведение базы данных.
Q: Достаточно ли мне смотреть только на планировщика?
A: Конечно, нет. Имеется много других вещей, таких как предметная экспертиза приложения, проектирование таблиц, архитектура базы данных и т.д., которые очень важны. Но вам, как разработчику/администратору баз данных, понимание и улучшение этих абстрактных навыков чрезвычайно важно для карьерного роста.
С этими фундаментальными знаниями мы теперь можем уверенно читать любой план и понимать, что происходит на высоком уровне. Оптимизация запросов очень обширная тема, которая требует знания множества вещей, происходящих внутри базы данных. В последующих статьях мы увидим, как планируются и выполняются запросы и их узлы, какие факторы влияют на поведение планировщика, и как мы можем оптимизировать их.
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Как посмотреть план запроса postgresql
14.1.1. Азы EXPLAIN
Взгляните на следующий простейший пример, просто иллюстрирующий формат вывода:
Приблизительная стоимость запуска. Это время, которое проходит, прежде чем начнётся этап вывода данных, например для сортирующего узла это время сортировки.
Приблизительная общая стоимость. Она вычисляется в предположении, что узел плана выполняется до конца, то есть возвращает все доступные строки. На практике родительский узел может досрочно прекратить чтение строк дочернего (см. приведённый ниже пример с LIMIT ).
Ожидаемое число строк, которое должен вывести этот узел плана. При этом так же предполагается, что узел выполняется до конца.
Ожидаемый средний размер строк, выводимых этим узлом плана (в байтах).
Важно понимать, что стоимость узла верхнего уровня включает стоимость всех его потомков. Также важно осознавать, что эта стоимость отражает только те факторы, которые учитывает планировщик. В частности, она не зависит от времени, необходимого для передачи результирующих строк клиенту, хотя оно может составлять значительную часть общего времени выполнения запроса. Тем не менее планировщик игнорирует эту величину, так как он всё равно не сможет изменить её, выбрав другой план. (Мы верим в то, что любой правильный план запроса выдаёт один и тот же набор строк.)
Возвращаясь к нашему примеру:
Эти числа получаются очень просто. Выполните:
и вы увидите, что tenk1 содержит 358 страниц диска и 10000 строк. Общая стоимость вычисляется как (число_чтений_диска * seq_page_cost) + (число_просканированных_строк * cpu_tuple_cost). По умолчанию, seq_page_cost равно 1.0, а cpu_tuple_cost — 0.01, так что приблизительная стоимость запроса равна (358 * 1.0) + (10000 * 0.01) = 458.
Теперь давайте изменим запрос, добавив в него предложение WHERE :
Теперь давайте сделаем ограничение более избирательным:
В данном случае планировщик решил использовать план из двух этапов: сначала дочерний узел плана просматривает индекс и находит в нём адреса строк, соответствующих условию индекса, а затем верхний узел собственно выбирает эти строки из таблицы. Выбирать строки по отдельности гораздо дороже, чем просто читать их последовательно, но так как читать придётся не все страницы таблицы, это всё равно будет дешевле, чем сканировать всю таблицу. (Использование двух уровней плана объясняется тем, что верхний узел сортирует адреса строк, выбранных из индекса, в физическом порядке, прежде чем читать, чтобы снизить стоимость отдельных чтений. Слово « bitmap » (битовая карта) в имени узла обозначает механизм, выполняющий сортировку.)
Теперь давайте добавим ещё одно условие в предложение WHERE :
В некоторых случаях планировщик предпочтёт « простой » план сканирования индекса:
В плане такого типа строки таблицы выбираются в порядке индекса, в результате чего чтение их обходится дороже, но так как их немного, дополнительно сортировать положения строк не стоит. Вы часто будете встречать этот тип плана в запросах, которые выбирают всего одну строку. Также он часто задействуется там, где условие ORDER BY соответствует порядку индекса, так как в этих случаях для выполнения ORDER BY не требуется дополнительный шаг сортировки.
Но для этого потребуется обойти оба индекса, так что это не обязательно будет выгоднее, чем просто просмотреть один индекс, а второе условие обработать как фильтр. Измените диапазон и вы увидите, как это повлияет на план.
Следующий пример иллюстрирует эффекты LIMIT :
Давайте попробуем соединить две таблицы по столбцам, которые мы уже использовали:
В этом примере число выходных строк соединения равно произведению чисел строк двух узлов сканирования, но это не всегда будет так, потому что в дополнительных условиях WHERE могут упоминаться обе таблицы, так что применить их можно будет только в точке соединения, а не в одном из узлов сканирования. Например:
Заметьте, что здесь планировщик решил « материализовать » внутреннее отношение соединения, поместив поверх него узел плана Materialize (Материализовать). Это значит, что сканирование индекса t2 будет выполняться только единожды, при том, что узлу вложенного цикла соединения потребуется прочитать данные десять раз, по числу строк во внешнем соединении. Узел Materialize сохраняет считанные данные в памяти, чтобы затем выдать их из памяти на следующих проходах.
Если немного изменить избирательность запроса, мы можем получить совсем другой план соединения:
Здесь планировщик выбирает соединение по хешу, при котором строки одной таблицы записываются в хеш-таблицу в памяти, после чего сканируется другая таблица и для каждой её строки проверяется соответствие по хеш-таблице. Обратите внимание, что и здесь отступы отражают структуру плана: результат сканирования битовой карты по tenk1 подаётся на вход узлу Hash, который конструирует хеш-таблицу. Затем она передаётся узлу Hash Join, который читает строки из узла внешнего потомка и проверяет их по этой хеш-таблице.
Ещё один возможный тип соединения — соединение слиянием:
Соединение слиянием требует, чтобы входные данные для него были отсортированы по ключам соединения. В этом плане данные tenk1 сортируются после сканирования индекса, при котором все строки просматриваются в правильном порядке, но таблицу onek выгоднее оказывается последовательно просканировать и отсортировать, так как в этой таблице нужно обработать гораздо больше строк. (Последовательное сканирование и сортировка часто бывает быстрее сканирования индекса, когда нужно отсортировать много строк, так как при сканировании по индексу обращения к диску не упорядочены.)
Один из способов посмотреть различные планы — принудить планировщик не считать выбранную им стратегию самой выгодной, используя флаги, описанные в Подразделе 18.7.1. (Это полезный, хотя и грубый инструмент. См. также Раздел 14.3.) Например, если мы убеждены, что последовательное сканирование и сортировка — не лучший способ обработать таблицу onek в предыдущем примере, мы можем попробовать
14.1.2. EXPLAIN ANALYZE
Заметьте, что значения « actual time » (фактическое время) приводятся в миллисекундах, тогда как оценки cost (стоимость) выражаются в произвольных единицах, так что они вряд ли совпадут. Обычно важнее определить, насколько приблизительная оценка числа строк близка к действительности. В этом примере они в точности совпали, но на практике так бывает редко.
В ряде случаев EXPLAIN ANALYZE выводит дополнительную статистику по выполнению, включающую не только время выполнения узлов и число строк. Для узлов Sort и Hash, например выводится следующая информация:
Для узла Sort показывается использованный метод и место сортировки (в памяти или на диске), а также задействованный объём памяти. Для узла Hash выводится число групп и пакетов хеша, а также максимальный объём, который заняла в памяти хеш-таблица. (Если число пакетов больше одного, часть хеш-таблицы будет выгружаться на диск и занимать какое-то пространство, но его объём здесь не показывается.)
Другая полезная дополнительная информация — число строк, удалённых условием фильтра:
Эти значения могут быть особенно ценны для условий фильтра, применённых к узлам соединения. Строка « Rows Removed » выводится, только когда условие фильтра отбрасывает минимум одну просканированную строку или потенциальную пару соединения, если это узел соединения.
Похожую ситуацию можно наблюдать при сканировании « неточного » индекса. Например, рассмотрим этот план поиска многоугольников, содержащих указанную точку:
Планировщик полагает (и вполне справедливо), что таблица слишком мала для сканирования по индексу, поэтому он выбирает последовательное сканирование, при котором все строки отбрасываются условием фильтра. Но если мы принудим его выбрать сканирование по индексу, мы получим:
Здесь мы видим, что индекс вернул одну потенциально подходящую строку, но затем она была отброшена при перепроверке условия индекса. Это объясняется тем, что индекс GiST является « неточным » для проверок включений многоугольников: фактически он возвращает строки с многоугольниками, перекрывающими точку по координатам, а затем для этих строк нужно выполнять точную проверку.
EXPLAIN принимает параметр BUFFERS (который также можно применять с ANALYZE ), включающий ещё более подробную статистику выполнения запроса:
Когда команда UPDATE или DELETE имеет дело с иерархией наследования, вывод может быть таким:
В этом примере узлу Update помимо изначально упомянутой в запросе родительской таблицы нужно обработать ещё три дочерние таблицы. Поэтому формируются четыре плана сканирования, по одному для каждой таблицы. Ясности ради для узла Update добавляется примечание, показывающее, какие именно таблицы будут изменяться, в том же порядке, в каком они идут в соответствующих внутренних планах. (Эти примечания появились в Postgres Pro 9.5; до этого о целевых таблицах приходилось догадываться, изучая внутренние планы узла.)
Под заголовком Planning time (Время планирования) команда EXPLAIN ANALYZE выводит время, затраченное на построение плана запроса из разобранного запроса и его оптимизацию. Время собственно разбора или перезаписи запроса в него не включается.
14.1.3. Ограничения
Оценки стоимости и числа строк для узла Index Scan показываются в предположении, что этот узел будет выполняться до конца. Но в действительности узел Limit прекратил запрашивать строки, как только получил первые две, так что фактическое число строк равно 2 и время выполнения запроса будет меньше, чем рассчитал планировщик. Но это не ошибка, а просто следствие того, что оценённые и фактические значения выводятся по-разному.
Для узлов BitmapAnd (Логическое произведение битовых карт) и BitmapOr (Логическое сложение битовых карт) фактическое число строк всегда равно 0 из-за ограничений реализации.