Квантили распределений EXCEL
history 19 ноября 2016 г.
Рассмотрим вычисление квантилей для некоторых функций распределений, представленных в MS EXCEL .
Сначала дадим формальное определение квантиля, затем приведем примеры их вычисления в MS EXCEL.
Определение
Точное значение квантиля в нашем случае можно найти с помощью формулы =НОРМ.СТ.ОБР(0,21)
СОВЕТ : Процедура вычисления квантилей имеет много общего с вычислением процентилей выборки (см. статью Процентили в MS EXCEL ).
Квантили специальных видов
Часто используются Квантили специальных видов:
В качестве примера вычислим медиану (0,5-квантиль) логнормального распределения LnN(0;1) (см. файл примера лист Медиана ). 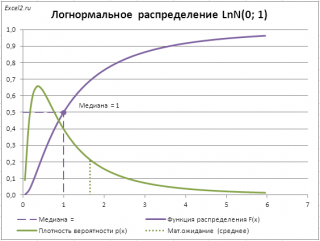
Это можно сделать с помощью формулы =ЛОГНОРМ.ОБР(0,5; 0; 1)
Квантили стандартного нормального распределения
Необходимость в вычислении квантилей стандартного нормального распределения возникает при проверке статистических гипотез и при построении доверительных интервалов.
В данных задачах часто используется специальная терминология:
Однако, при проверке гипотез и построении доверительных интервалов чаще используется «верхний» α-квантиль. Покажем почему.
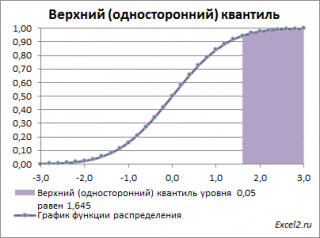
Действительно, для α=0,05, верхний 0,05-квантиль стандартного нормального распределения равен 1,645. Т.к. функция плотности вероятности стандартного нормального распределения является четной функцией, то вычисления в MS EXCEL верхнего квантиля можно сделать по двум формулам:
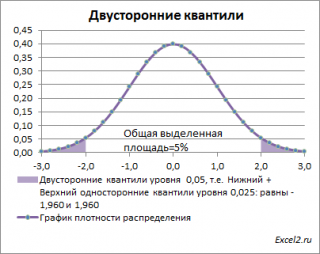
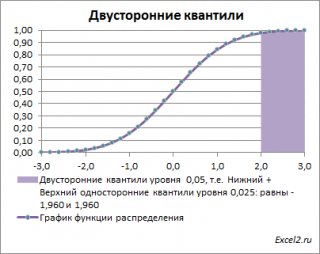
Другими словами, двусторонние α-квантили задают интервал, в который рассматриваемая случайная величина попадает с заданной вероятностью α.
Квантили распределения Стьюдента
Квантили распределения ХИ-квадрат
Вычислять квантили распределения ХИ-квадрат с n -1 степенью свободы требуется, если проводится проверка гипотезы о дисперсии нормального распределения (см. статью Проверка статистических гипотез в MS EXCEL о дисперсии нормального распределения ).
Результат равен 3,25.
Квантили F-распределения
Вычислять квантили распределения Фишера с n 1 -1 и n 2 -1 степенями свободы требуется, если проводится проверка гипотезы о равенстве дисперсий двух нормальных распределений (см. статью Двухвыборочный тест для дисперсии: F-тест в MS EXCEL ).
Чтобы вычислить верхний 0,05/2-квантиль для F -распределения с числом степеней свободы 10 и 12, необходимо записать формулу =F.ОБР.ПХ(0,05/2;10;12) =FРАСПОБР(0,05/2;10;12) =F.ОБР(1-0,05/2;10;12)
Квантили распределения Вейбулла
После логарифмирования обеих частей выражения, выразим x через соответствующее ему значение F(x) равное P: 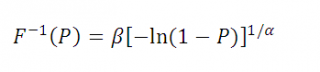
Квантили экспоненциального распределения
Задача : Случайная величина имеет экспоненциальное распределение : 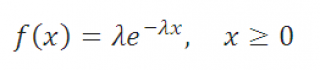
Требуется выразить p -квантиль x p через параметр распределения λ и заданную вероятность p .
Решение : Вспоминаем, что p -квантиль – это такое значение x p случайной величины X, для которого P(X
Нормальное распределение (Гаусса) в Excel
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
Кривая нормального распределения Гаусса имеет следующий вид.

График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.

Формула состоит из двух математических констант:
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии ( σ 2 ). Кратко обозначается N(m, σ 2 ) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ 2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.

Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:

Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X 0 =1 и остается рассчитать только соотношение 1 на корень из 2 пи.
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.

Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.

В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец 0, т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.

Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:

Это факт показан на картинке:

Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:

Для наглядности можно взглянуть на рисунок.

На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.

Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:


Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.

Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:

Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.

Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.

То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от 0 до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.

Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).

Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.

Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.

Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
Нормальное распределение в Excel
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.

Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ( z ) или вероятности Φ(z) по нормированным данным (z).
z – значение стандартизованной переменной
интегральная – если 0, то рассчитывается плотность ϕ( z ) , если 1 – значение функции Ф(z), т.е. вероятность P(Z
Квантили распределений EXCEL
Медиана и квартили


Квантили нормального распределения
Математическое описание
Крайне важное определение: математическое ожидание – это площадь под графиком распределения. Если мы говорим о дискретном распределении – это сумма событий умноженных на соответсвующие вероятности, также известно как момент:
(2) E(X) = Σ(pi•Xi) E – от английского слова Expected (ожидание)
Для математического ожидания справедливы равенства:
(3) E(X + Y) = E(X) + E(Y)
(4) E(X•Y) = E(X) • E(Y)
Центральный момент степени k:
Среднее значение
Среднее значение (μ) закона распределения – это математическое ожидание случайной величины (случайная величина – это событие), например, сколько в среднем посетителей заходит в магазин в час:
| Кол-во посетителей | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Количество наблюдений | 114 | 115 | 52 | 52 | 24 | 13 | 30 |
| Таблица 1. Количество посетителей в час | |||||||
Чтобы найти среднее значение всех результатов необходимо сложить всё вместе и разделить на количество результатов:
μ = (114 • 0 + 115 • 1 + 52 • 2 + 52 • 3 + 24 • 4 + 13 • 5 + 30 • 6) / 400 = 716/400 = 1.79
То же самое мы можем проделать используя формулу 2:
μ = M(X) = Σ(Xi•pi) = 0 • 0.29 + 1 • 0.29 + 2 • 0.13 + 3 • 0.13 + 4 • 0.06 + 5 • 0.03 + 6 • 0.08 = 1.79 Момент первой степени, формула (5)
Собственно, формула 2 представляет собой среднее арифметическое всех значений
Итог: в среднем, 1.79 посетителя в час
| Количество посетителей | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Вероятность (%) | 28.5 | 28.8 | 13 | 13 | 6 | 3.3 | 7.5 |
| Таблица 2. Закон распределения количества посетителей | |||||||
Отклонение от среднего
Посмотрите на это распределение, можно предположить, что в среднем случайная величина равна 100±5, поскольку кажется, что таких значений несравнимо больше чем тех, что меньше 95 или больше 105:
График 2. График функции вероятности. Распределение ≈ 100±5
Среднее значение по формуле (2): μ = 99.95, но как посчитать, насколько далеко все значения находятся от среднего? Вам должна быть знакома запись 100±5. Что бы получить это значение ±, нам необходимо определить диапазон значений вокруг среднего. И мы могли бы использовать в качестве меры удалённости “разность” между средним и случайными величинами:
но сумма таких расстояний, а следовательно и любое производное от этого числа, будет равно нулю, поэтому в качестве меры выбрали квадрат разниц между величинами и средним значением:
Соответственно, среднее значение удалённости – это математическое ожидание квадратов удалённости:
(9) σ 2 = E[(X – E(X)) 2 ] Поскольку вероятности любой удалённости равносильны – вероятность каждого из них – 1/n, откуда: (10) σ 2 = E[(X – E(X)) 2 ] = ∑[(Xi – μ) 2 ]/n Она же формула центрального момента (6) второй степени
σ возведена в квадрат, поскольку вместо расстояний мы взяли квадрат расстояний. σ 2 называется дисперсией. Корень из дисперсии называется средним квадратическим отклонением, или среднеквадратическим отклоненим, и его используют в качестве меры разброса:
Возвращаясь к примеру, посчитаем среднеквадратическое отклонение для графика 2:
Квантиль
График 3. Функция распределения. Медиана
График 4. Функция распределения. 4-квантиль или квартиль
График 5. Функция распределения. 0.34-квантиль
Для анализа функции распределения ввели понятие квантиль. Квантиль – это случайная величина при заданном уровне вероятности, т.е.: квантиль для уровня вероятности 50% – это случайная величина на графике плотности вероятности, которая имеет вероятность 50%. На примере с графиком 3, квантиль уровня 0.5 = 99 (ближайшее значение, поскольку распределение дискретно и события со значением 99.3 просто не существует)
То есть, если мы говорим о дециле (10-квантиле), то это означает, что мы разбили график на 10 частей, что соответствует девяти линяям, и для каждого дециля нашли значение случайной величины.
Также, используется обозначение x-квантиль, где х – дробное число, например, 0.34-квантиль, такая запись означает значение случайной величины при p = 0.34.
Для дискретного распределения квантиль необходимо выбирать следующим образом: квантиль гарантирует вероятность, поэтому, если рассчитанный квантиль не совпадает с одним и значений, необходимо выбирать меньшее значение.
Построение интервалов
Квантили используют для построения доверительных интервалов, которые необходимы для исследования статистики не одного конкретного события (например, интерес – случайное число = 98), а для группы событий (например, интерес – случайное число между 96 и 99). Доверительный интервал бывает двух видов: односторонний и двусторонний. Параметр доверительного интервала – уровень доверия. Уровень доверия означает процент событий, которые можно считать успешными.
Двусторонний доверительный интервал
Двусторонний доверительный интервал строится следующим образом: мы задаёмся уровнем значимости, например, 10%, и выделяем область на графике так, что 90% всех событий попадут в эту область. Поскольку интервал двусторонний, то мы отсекаем по 5% с каждой стороны, т.е. мы ищем 5й перцентиль, 95й перцентиль и значения случайной величины между ними будут являться доверительной областью, значения за пределами доверительной области называются “критическая область“
Первый квартиль
Значение квартиля Q1 находится в интервале 68,98 – 71,70, соответствующего частоте fQ1 = 150:4 = 37,5
Третий квартиль
Значение квартиля находится в интервале 68,98 – 71,70, соответствующего частоте fQ3 = (3*150):4 = 112,5
Квартили непрерывного распределения
Если функция распределения F (х) случайной величины х непрерывна, то 1-й квартиль является решением уравнения F(х) =0,25, второй – F(х) =0,5, а третий F(х) =0,75.
Например, решив аналитическим способом это уравнение для Логнормального распределения lnN(μ; σ 2 ), получим, что медиана (2-й квартиль ) вычисляется по формуле e μ или в MS EXCEL =EXP(μ). При μ=1, медиана равна 2,718. 
Примечание : Напомним, что интеграл от функции плотности вероятности по всей области задания случайной величины равен единице: 
Поэтому, линии квартилей ( х=квартиль ) делят площадь под графиком функции плотности вероятности на 4 равные части.
Квартили в MS EXCEL
Моменты случайной величины
Моменты случайно величины описывают различные аспекты характера и формы нашего распределения.
#1 — первый момент случайной величины — среднее значение данных, которое показывает место распределения.
#2 — второй момент случайной величины — дисперсия, которая показывает разброс распределения. Большие значения имеют больший размах, чем маленькие.
#3 — третий момент случайной величины — коэффициент асимметрии — мера того, насколько неравномерным является распределение. Коэффициент асимметрии положителен, если распределение наклонено влево и левый хвост короче правого. То есть среднее значение находится правее. И наоборот:
#4 — четвертый момент случайной величины — коэффициент эксцесса, который описывает то, насколько толстый хвост и насколько острый пик распределения. Этот коэффициент показывает, насколько вероятно найти точки экстремума в данных. Чем выше значение, тем вероятнее выбросы. Это похоже на разброс (дисперсию), но между ними есть отличия.
Как видно на графике, чем выше значение пики, тем выше коэффициент эксцесса, т.е. у верхней кривой коэффициент эксцесса выше, чем у нижней.
Статистический анализ роста доли дохода в Excel за период
Пример 2. В таблице приведены данные о доходах предпринимателя за год. Доказать, что примерно 75% значений меньше, чем третий квартиль доходов.
Вид исходной таблицы:

Определим 3-й по формуле:


Определим соотношение чисел, меньше полученного числа, к общему количеству значений по формуле:
=СЧЁТЕСЛИ(B2:B13;” Пример 3. Имеется диапазон случайных чисел, отсортированный в порядке возрастания. Определить соотношение суммы чисел, которые меньше 1-го квартиля, к сумме чисел, которые превышают значение 1-го квартиля.
Чтобы сгенерировать случайное число в Excel воспользуемся функцией:
После генерации отсортируем случайно сгенерированные числа по возрастанию. Вид исходной таблицы данных со случайными числами:

Формула для расчета имеет следующий вид (формула массива CTRL+SHIFT+ENTER):
Функции СУММ с вложенными функциями ЕСЛИ выполняют расчет суммы только тех чисел, которые меньше и больше соответственно значения, возвращаемого функцией для исследуемого диапазона. Из полученных значений вычисляется частное. Результат расчетов:

Общая сумма чисел исследуемого диапазона, которые меньше 1-го квартиля, составляет всего 8,57% от общей суммы чисел, которые больше 1-го квартиля.
Расчет квартилей в R и SAS
Функция quantile в R использует все девять алгоритмов расчета квантилей, в соответствии с нумерацией, предложенной Hyndman and Fan в работе 1996 г. (рис. 15; если вы не знакомы с R, рекомендую начать с Алексей Шипунов. Наглядная статистика. Используем R! ). Квантиль при i-м методе расчета:

Расчет децилей для дискретного ряда
Определяем номер дециля по формуле:  ,
,
Если номер дециля – целое число, то значение дециля будет равно величине элемента ряда, которое обладает накопленной частотой равной номеру дециля. Например, если номер дециля равен 20, его значение будет равно значению признака с S =20 (накопленной частотой равной 20).
Если номер дециля – нецелое число, то дециль попадает между двумя наблюдениями. Значением дециля будет сумма, состоящая из значения элемента, для которого накопленная частота равна целому значению номера дециля, и указанной части (нецелая часть номера дециля) разности между значением этого элемента и значением следующего элемента.
Например, если номер дециля равна 20,25, дециль попадает между 20-м и 21-м наблюдениями, и его значение будет равно значению 20-го наблюдения плюс 1/4 разности между значением 20-го и 21-го наблюдений.
Квантили специальных видов
Часто используются Квантили специальных видов:
В качестве примера вычислим медиану (0,5-квантиль) логнормального распределения LnN(0;1) (см. файл примера лист Медиана ). 
Это можно сделать с помощью формулы =ЛОГНОРМ.ОБР(0,5; 0; 1)
Квантили стандартного нормального распределения
Необходимость в вычислении квантилей стандартного нормального распределения возникает при проверке статистических гипотез и при построении доверительных интервалов.
В данных задачах часто используется специальная терминология:


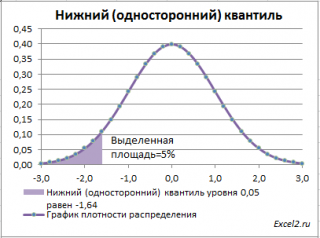
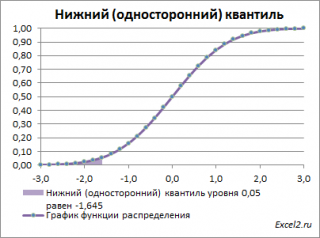
Однако, при проверке гипотез и построении доверительных интервалов чаще используется “верхний” α-квантиль. Покажем почему.
Верхним α – квантилем называют такое значение x α , для которого вероятность, того что случайная величина X примет значение больше или равное x α равна альфа: P(X>= x α )= α . Из определения понятно, что верхний альфа – квантиль любого распределения равен нижнему (1- α) – квантилю. А для распределений, у которых функция плотности распределения является четной функцией, верхний α – квантиль равен нижнему α – квантилю со знаком минус . Это следует из свойства четной функции f(-x)=f(x), в силу симметричности ее относительно оси ординат.
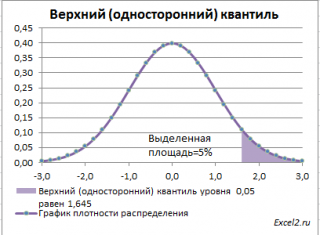
Действительно, для α=0,05, верхний 0,05-квантиль стандартного нормального распределения равен 1,645. Т.к. функция плотности вероятности стандартного нормального распределения является четной функцией, то вычисления в MS EXCEL верхнего квантиля можно сделать по двум формулам:
Чтобы пояснить название « верхний» квантиль , построим график плотности вероятности и функцию вероятности стандартного нормального распределения для α=0,05.




Вычислить двусторонний 0,05 – квантиль это можно с помощью формул MS EXCEL: =НОРМ.СТ.ОБР(1-0,05/2) или =-НОРМ.СТ.ОБР(0,05/2)
Другими словами, двусторонние α-квантили задают интервал, в который рассматриваемая случайная величина попадает с заданной вероятностью α.
Квантили распределения Стьюдента
Чтобы вычислить в MS EXCEL верхний 0,05/2 – квантиль для t-распределения с 10 степенями свободы (или тоже самое двусторонний 0,05-квантиль ), необходимо записать формулу =СТЬЮДЕНТ.ОБР.2Х(0,05; 10) или =СТЬЮДРАСПОБР(0,05; 10) или =СТЬЮДЕНТ.ОБР(1-0,05/2; 10) или =-СТЬЮДЕНТ.ОБР(0,05/2; 10)
Квантили распределения ХИ-квадрат
Вычислять квантили распределения ХИ-квадрат с n -1 степенью свободы требуется, если проводится проверка гипотезы о дисперсии нормального распределения (см. статью Проверка статистических гипотез в MS EXCEL о дисперсии нормального распределения ).
Чтобы вычислить верхний 0,05/2 – квантиль для ХИ 2 -распределения с числом степеней свободы 10, т.е. χ 2 0,05/2,n-1 , необходимо в MS EXCEL записать формулу =ХИ2.ОБР.ПХ(0,05/2; 10) или =ХИ2.ОБР(1-0,05/2; 10)