Нахождение повторяющихся значений в таблице в MySQL
Главное меню » Базы данных » MySQL » Нахождение повторяющихся значений в таблице в MySQL

Для начала у вас должен быть установлен MySQL в вашей системе со своими утилитами: рабочая среда MySQL и клиентская оболочка командной строки. После этого у вас должны быть дубликаты некоторых данных или значений в таблицах базы данных. Давайте рассмотрим это на нескольких примерах. Прежде всего, откройте клиентскую оболочку командной строки с панели задач рабочего стола и введите свой пароль MySQL по запросу.
Мы нашли разные методы поиска дубликатов в таблице. Взгляните на них один за другим.
Поиск дубликатов в одном столбце
Во-первых, вы должны знать синтаксис запроса, используемого для проверки и подсчета дубликатов для одного столбца.
Вот объяснение вышеуказанного запроса:
Мы создали новую таблицу под названием «animals» в «data» нашей базы данных MySQL, имеющую повторяющиеся значения. Он имеет шесть столбцов с разными значениями, например, id, Name, Species, Gender, Age и Price, предоставляя информацию о различных домашних животных. После вызова этой таблицы с помощью запроса SELECT мы получаем следующий вывод в нашей клиентской оболочке командной строки MySQL.
Теперь мы попытаемся найти повторяющиеся и повторяющиеся значения из приведенной выше таблицы, используя функцию COUNT и GROUP BY в запросе SELECT. Этот запрос будет считать имена домашних животных, которые встречаются в таблице менее трех раз. После этого он отобразит эти имена, как показано ниже.
Использование того же запроса для получения разных результатов при изменении числа COUNT для имен домашних животных, как показано ниже.
Чтобы получить результаты для 3 повторяющихся значений для имен домашних животных, как показано ниже.
Искать дубликаты в нескольких столбцах
Синтаксис запроса для проверки или подсчета дубликатов для нескольких столбцов следующий:
Вот объяснение вышеуказанного запроса:
Мы использовали ту же таблицу под названием «животные» с повторяющимися значениями. Мы получили приведенный ниже результат, используя указанный выше запрос для проверки повторяющихся значений в нескольких столбцах. Мы проверяли и подсчитывали повторяющиеся значения для столбцов «Gender» и «Price», сгруппированные по столбцу «Price». Он покажет пол домашних животных и их цены, которые находятся в таблице, как дубликаты не более 5.
Поиск дубликатов в одной таблице с помощью INNER JOIN
Вот основной синтаксис для поиска дубликатов в одной таблице:
Вот описание служебного запроса:
У нас есть новая таблица order2 с повторяющимися значениями в столбце OrderNo, как показано ниже.
Мы выбираем три столбца: Item, Sales, OrderNo, которые будут отображаться в выводе. В то время как столбец OrderNo используется для проверки дубликатов. Внутреннее соединение выберет значения или строки, имеющие значения элементов более одного в таблице. После выполнения мы получим следующие результаты.
Поиск дубликатов в нескольких таблицах с помощью INNER JOIN
Вот упрощенный синтаксис для поиска дубликатов в нескольких таблицах:
Вот описание служебного запроса:
У нас есть две таблицы, «order1» и «order2», в нашей базе данных со столбцом «OrderNo» в обеих, как показано ниже.
Мы будем использовать INNER join для объединения дубликатов двух таблиц в соответствии с указанным столбцом. Предложение INNER JOIN получит все данные из обеих таблиц, объединив их, а предложение ON будет связывать столбцы с одинаковыми именами из обеих таблиц, например, OrderNo.
Чтобы получить определенные столбцы в выходных данных, попробуйте следующую команду:
Вывод
Теперь мы могли искать несколько копий в одной или нескольких таблицах информации MySQL и распознавать функции GROUP BY, COUNT и INNER JOIN. Убедитесь, что вы правильно построили таблицы и что выбраны правильные столбцы.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Как посчитать дубли в sql

Создание игр на Unreal Engine 4
Данный курс научит Вас созданию игр на Unreal Engine 4. Курс состоит из 12 модулей, в которых Вы с нуля освоите этот движок и сможете создавать самые разные игры.
В курсе Вы получите всю необходимую теоретическую часть, а также увидите массу практических примеров. Дополнительно, почти к каждому уроку идут упражнения для закрепления материала.
Помимо самого курса Вас ждёт ещё 5 бесплатных ценных Бонусов: «Динамическая смена дня и ночи», «Создание динамической погоды», «Создание искусственного интеллекта для NPC», «Создание игры под мобильные устройства» и «Создание прототипа RPG с открытым миром».
Подпишитесь на мой канал на YouTube, где я регулярно публикую новые видео.

Подписавшись по E-mail, Вы будете получать уведомления о новых статьях.
Добавляйтесь ко мне в друзья ВКонтакте! Отзывы о сайте и обо мне оставляйте в моей группе.
Зачем Вы изучаете программирование/создание сайтов?
Создание мультиплеерной игры на Unreal Engine 4
В этом курсе Вы увидите пример создания мультиплеерной игры на Unreal Engine 4: создание персонажа, HUD, атака, блокировка, главное меню и многое другое.
Чтобы получить Видеокурс,
заполните форму
Как создать профессиональный Интернет-магазин
— Вы будете знать, как создать Интернет-магазин.
— Вы получите бесплатный подарок с подробным описанием каждого шага.
— Вы сможете уже приступить к созданию Интернет-магазина.
Поиск повторяющихся значений в таблице SQL
Легко найти duplicates с одним полем:
Поэтому, если у нас есть таблица
То есть, я хочу получить «Том», «Том».
ОТВЕТЫ
Ответ 1
Просто группируйтесь на обоих столбцах.
Примечание: более старый стандарт ANSI должен иметь все неагрегированные столбцы в GROUP BY, но это изменилось с идеей «функциональной зависимости»:
Ответ 2
если вы хотите, чтобы идентификаторы дубликатов использовали это:
для удаления дубликатов попробуйте:
Ответ 3
Ответ 4
Если вы хотите удалить дубликаты, здесь гораздо более простой способ сделать это, чем найти четные/нечетные строки в тройной выбор:
Намного легче читать и понимать IMHO
Примечание. Единственная проблема заключается в том, что вы должны выполнить запрос до тех пор, пока не удалите строки, поскольку каждый раз удаляйте только по 1 каждого дубликата
Ответ 5
Ответ 6
Ответ 7
Немного поздно на вечеринку, но я нашел действительно крутое обходное решение для поиска всех повторяющихся идентификаторов:
Ответ 8
попробуйте этот код
Ответ 9
В случае, если вы работаете с Oracle, этот способ был бы предпочтительнее:
Ответ 10
Это выбирает/удаляет все повторяющиеся записи, кроме одной записи из каждой группы дубликатов. Таким образом, удаление удаляет все уникальные записи + одну запись из каждой группы дубликатов.
Помните о большем количестве записей, это может вызвать проблемы с производительностью.
Ответ 11
Ответ 12
Если вы хотите увидеть, есть ли в вашей таблице повторяющиеся строки, я использовал ниже Query:
Ответ 13
Как мы можем считать дублированные значения? либо он повторяется 2 раза или больше 2. просто считайте их, а не групповыми.
Ответ 14
Это легкая вещь, которую я придумал. Он использует общее табличное выражение (CTE) и окно раздела (я думаю, что эти функции находятся в SQL 2008 и последующих версиях).
В этом примере найдены все ученики с дублирующимся именем и dob. Поля, которые вы хотите проверить на дублирование, перечислены в предложении OVER. Вы можете включать любые другие поля, которые вы хотите в проекции.
Ответ 15
Ответ 16
SELECT id, COUNT(id) FROM table1 GROUP BY id HAVING COUNT(id)>1;
Я думаю, что это будет работать правильно, чтобы искать повторяющиеся значения в определенном столбце.
Ответ 17
Ответ 18
Используя CTE, мы также можем найти повторяющееся значение
Ответ 19
Это также должно работать, возможно, попробуйте.
Особенно хорошо в вашем случае. Если вы ищете дубликаты, у которых есть префикс или общие изменения, например, например. новый домен в почте. то вы можете использовать replace() в этих столбцах
Ответ 20
Если вы хотите найти повторяющиеся данные (по одному или нескольким критериям) и выбрать фактические строки.
Ответ 21
Ответ 22
SELECT column_name,COUNT(*) FROM TABLE_NAME GROUP BY column1, HAVING COUNT(*) > 1;
Ответ 23
Удалить записи, имена которых повторяются
Ответ 24
Для проверки из дубликата записи в таблице.
Удалить дубликат записи в таблице.
Ответ 25
Мы можем использовать здесь, которые работают с агрегатными функциями, как показано ниже
Здесь в качестве двух полей id_account и data используются Count (*). Таким образом, он выдаст все записи, которые имеют более одного раза одинаковые значения в обоих столбцах.
Мы по какой-то причине ошибочно пропустили добавление каких-либо ограничений в таблицу SQL-сервера, и записи были вставлены дубликаты во все столбцы с интерфейсным приложением. Затем мы можем использовать запрос ниже, чтобы удалить дубликат запроса из таблицы.
Здесь мы взяли все отдельные записи оригинальной таблицы и удалили записи исходной таблицы. Мы снова вставили все различные значения из новой таблицы в исходную таблицу, а затем удалили новую таблицу.
Ответ 26
Удалить записи, имена которых повторяются
УДАЛИТЬ ИЗ CTE ГДЕ T> 1
Ответ 27
Вы можете использовать ключевое слово SELECT DISTINCT, чтобы избавиться от дубликатов. Вы также можете отфильтровать по имени и получить всех с этим именем на столе.
Как вывести повторяющиеся значения в столбце на T-SQL? Microsoft SQL Server
Приветствую всех на сайте Info-Comp.ru! В этой небольшой заметке я покажу, как можно на SQL вывести повторяющиеся значения в столбце таблицы в Microsoft SQL Server. Все будет рассмотрено очень подробно и с примерами.

Исходные данные для примеров
Сначала давайте я расскажу, какие данные я буду использовать в статье, чтобы Вы четко понимали и видели, какие результаты будут возвращаться, если выполнять те или иные действия.
Сразу скажу, что все данные тестовые.
Следующей инструкцией мы создаем таблицу Goods и добавляем в нее несколько строк, в некоторых из которых значение столбца Price будет повторяться.
Останавливаться на том, что делает та или иная инструкция, я не буду, так как это другая тема, если Вам интересно, можете более подробно посмотреть в следующих статьях:
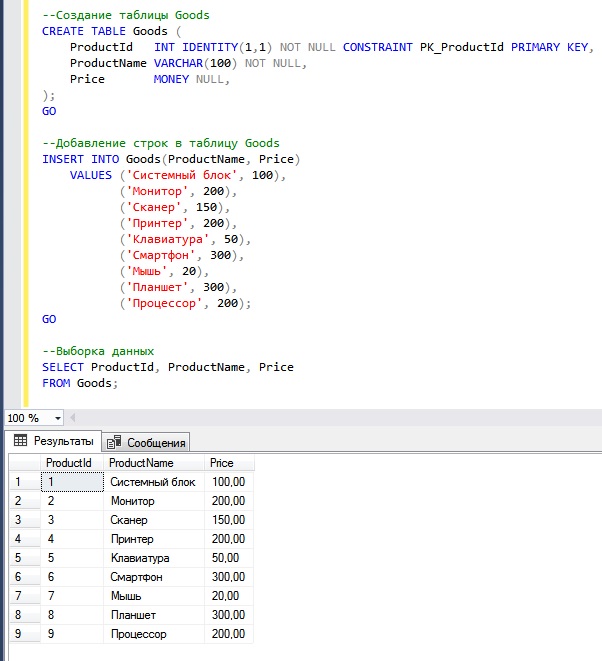
Вы видите, какие данные есть, именно к ним я буду посылать SQL запрос, который будет определять и выводить повторяющиеся значения в столбце Price.
Выводим повторяющиеся значения в столбце на T-SQL
Основной алгоритм определения повторяющихся значений в столбце состоит в том, что нам нужно сгруппировать все строки по столбцу, в котором необходимо найти повторяющиеся значения, и подсчитать количество строк в каждой сгруппированной строке, а затем просто поставить фильтр (>1) на итоговое количество, отбросив тем самым строки со значением 1, т.е. если значение встречается всего один раз, значит, оно не повторяется, и нам не нужно.
Вот пример всего вышесказанного.
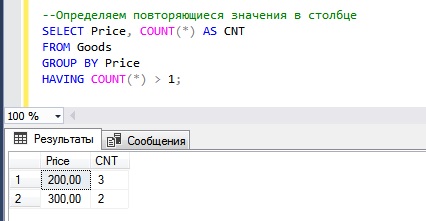
Мы видим, что у нас есть всего два значения, которые повторяются — это 200 и 300. Первое значение, т.е. 200, повторяется 3 раза, второе — 2 раза.
Данные сгруппировали мы конструкцией GROUP BY, подсчитали количество значений встроенной функцией COUNT, а отфильтровали сгруппированные строки конструкцией HAVING.
Выводим все строки с повторяющимися значениями на T-SQL
Но в большинстве случаев просто узнать повторяющиеся в столбце значения недостаточно, иногда необходимо вывести все записи в этой таблице, которые содержат эти повторяющиеся значения.
Это можно реализовать с помощью подзапроса, но использовать подзапрос, в котором будет группировка, не очень удобно, и уж точно неудобочитаемо. Поэтому мне нравится в каких-то подобных случаях использовать CTE (обобщённое табличное выражение) для повышения читабельности кода. Также чтобы сделать результирующий набор данных более наглядным, его можно отсортировать по целевому столбцу, тем самым мы сразу увидим строки с повторяющимися значениями.
Вот пример, в котором мы выводим все строки с повторяющимися значениями в столбце, отсортированные по столбцу Price.
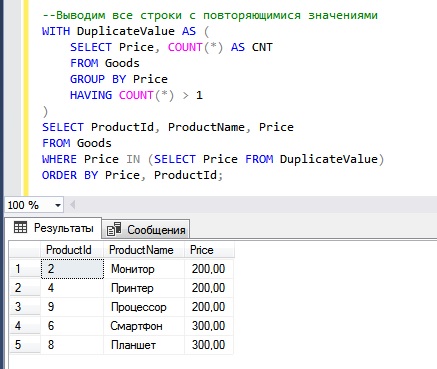
Как видим, сначала у нас идут все строки со значением 200, а затем строки со значением 300. Сортировку мы осуществили конструкцией ORDER BY. Если у Вас возникает вопрос, что такое DuplicateValue, то это всего лишь название CTE выражения, в принципе Вы его можете назвать и по-другому.
Заметка!
Для комплексного изучения языка T-SQL рекомендую почитать мои книги и пройти курсы:
У меня на этом все, надеюсь, материал был Вам полезен. Удачи Вам, пока!
Поиск повторяющихся значений в таблице SQL
Дубликаты с одним полем легко найти:
Так что если у нас есть стол
То есть я хочу получить «Том», «Том».
Причина, по которой мне это нужно: я допустил ошибку и позволил вставить дубликаты name и email значения. Теперь мне нужно удалить / изменить дубликаты, поэтому мне нужно сначала найти их.
Просто сгруппируйте по обоим столбцам.
Примечание: более старый стандарт ANSI должен иметь все неагрегированные столбцы в GROUP BY, но это изменилось с идеей «функциональной зависимости» :
Поддержка не соответствует:
если вы хотите идентификаторы дупс, используйте это:
чтобы удалить дубликаты, попробуйте:
Если вы хотите удалить дубликаты, вот гораздо более простой способ сделать это, чем найти четные / нечетные строки в тройном суб-выборе:
И так, чтобы удалить:
Гораздо проще читать и понимать ИМХО
Немного опоздал на вечеринку, но я нашел действительно крутой обходной путь, чтобы найти все дубликаты ID:
Это выбирает / удаляет все дублирующиеся записи, кроме одной записи из каждой группы дубликатов. Таким образом, удаление оставляет все уникальные записи + одну запись из каждой группы дубликатов.
Помните о большом количестве записей, это может вызвать проблемы с производительностью.
Если вы работаете с Oracle, этот способ будет предпочтительнее:
Если вы хотите увидеть, есть ли в вашей таблице повторяющиеся строки, я использовал ниже Query:
Это легкая вещь, которую я придумал. Он использует общее табличное выражение (CTE) и окно раздела (я думаю, что эти функции есть в SQL 2008 и более поздних версиях).
Этот пример находит всех студентов с одинаковыми именами и документами. Поля, которые вы хотите проверить на дублирование, идут в предложении OVER. Вы можете включить любые другие поля, которые вы хотите в проекции.
Используя CTE, мы также можем найти двойное значение
SELECT id, COUNT(id) FROM table1 GROUP BY id HAVING COUNT(id)>1;
Я думаю, что это будет работать правильно для поиска повторяющихся значений в определенном столбце.
Это также должно работать, может быть, попробовать.
Особенно хорошо в вашем случае, если вы ищете дубликаты, у которых есть какой-то префикс или общие изменения, например, новый домен в почте. тогда вы можете использовать replace () в этих столбцах
Если вы хотите найти дубликаты данных (по одному или нескольким критериям) и выбрать фактические строки.
Удалить записи, имена которых повторяются
Для проверки из дубликата записи в таблице.
Удалить дубликат записи в таблице.
SELECT column_name,COUNT(*) FROM TABLE_NAME GROUP BY column1, HAVING COUNT(*) > 1;
Мы можем использовать здесь, которые работают с агрегатными функциями, как показано ниже
Здесь в качестве двух полей id_account и data используются Count (*). Таким образом, он выдаст все записи, которые имеют более одного раза одинаковые значения в обоих столбцах.
Мы по какой-то причине ошибочно пропустили добавление каких-либо ограничений в таблицу SQL-сервера, и записи были вставлены дубликаты во все столбцы с интерфейсным приложением. Затем мы можем использовать запрос ниже, чтобы удалить дубликат запроса из таблицы.
Здесь мы взяли все отличные записи исходной таблицы и удалили записи исходной таблицы. Мы снова вставили все различные значения из новой таблицы в исходную таблицу, а затем удалили новую таблицу.
Вы можете попробовать это
Вы можете использовать ключевое слово SELECT DISTINCT, чтобы избавиться от дубликатов. Вы также можете фильтровать по имени и получить всех с этим именем на столе.
Точный код будет отличаться в зависимости от того, хотите ли вы также найти дублирующиеся строки или только разные идентификаторы с одинаковыми адресом электронной почты и именем. Если id является первичным ключом или иным образом имеет уникальное ограничение, это различие не существует, но вопрос не определяет это. В первом случае вы можете использовать код, приведенный в нескольких других ответах: