Как определить объем текста
Информационный объем текста складывается из информационных весов составляющих его символов.
Современный компьютер может обрабатывать числовую, текстовую, графическую, звуковую и видео информацию. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется всего два символа 0 и 1. Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц – машинным языком.
Какой длины должен быть двоичный код, чтобы с его помощью можно было закодировать васе символы клавиатуры компьютера?
Достаточный алфавит
В алфавит мощностью 256 символов можно поместить практически все символы, которые есть на клавиатуре. Такой алфавит называется достаточным.
Единице в 8 бит присвоили свое название – байт.
1 байт = 8 бит.
Таким образом, информационный вес одного символа достаточного алфавита равен 1 байту.
Для измерения больших информационных объемов используются более крупные единицы измерения информации:
Единицы измерения количества информации:
1 килобайт = 1 Кб = 1024 байта
1 мегабайт = 1 Мб = 1024 Кб
1 гигабайт = 1 Гб = 1024 Гб
Информационный объем текста
Книга содержит 150 страниц.
На каждой странице – 40 строк.
В каждой строке 60 символов (включая пробелы).
Найти информационный объем текста.
1. Количество символов в книге:
60 * 40 * 150 = 360 000 символов.
2. Т.к. 1 символ весит 1 байт, информационный объем книги равен
3. Переведем байты в более крупные единицы:
360 000 / 1024 = 351,56 Кб
351,56 / 1024 = 0,34 Мб
Ответ: Информационный объем текста 0,34 Мб.
Задача:
Информационный объем текста, подготовленного с помощью компьютера, равен 3,5 Кб. Сколько символов содержит этот текст?
Информационный объем текста 3,5 Мб. Найти количество символов в тексте.
1. Переведем объем из Мб в байты:
3,5 Мб * 1024 = 3584 Кб
3584 Кб * 1024 = 3 670 016 байт
2. Т.к. 1 символ весит 1 байт, количество символов в тексте равно


SEO-анализ текста от Text.ru – это уникальный сервис, не имеющий аналогов. Возможность подсветки «воды», заспамленности и ключей в тексте позволяет сделать анализ текста интерактивным и легким для восприятия.
SEO-анализ текста включает в себя:
С помощью данного онлайн-сервиса можно определить число слов в тексте, а также количество символов с пробелами и без них.
Возможность нахождения поисковых ключей в тексте и определения их количества полезна как для написания нового текста, так и для оптимизации уже существующего. Расположение ключевых слов по группам и по частоте сделает навигацию по ключам удобной и быстрой. Сервис также найдет и морфологические варианты ключей, которые выделятся в тексте при нажатии на нужное ключевое слово.
Данный параметр отображает процент наличия в тексте стоп-слов, фразеологизмов, а также словесных оборотов, фраз, соединительных слов, являющихся не значимыми и не несущими смысловой нагрузки. Небольшое содержание «воды» в тексте является естественным показателем, при этом:
Процент заспамленности текста отражает количество поисковых ключевых слов в тексте. Чем больше в тексте ключевых слов, тем выше его заспамленность:
Данный параметр показывает количество слов, состоящих из букв различных алфавитов. Часто это буквы русского и английского языка, например, слово «стол», где «о» – буква английского алфавита. Некоторые копирайтеры заменяют в русских словах часть букв на английские, чтобы обманным путем повысить уникальность текста. SEO-анализ текста от Text.ru успешно выявляет такие слова.
SEO-анализ текста доступен через API. Подробнее в API-проверке.

К огда человек только начинает учиться копирайтингу, автор испытывает уйму сложностей даже в таких простых вещах, как определение объёма текста. Кажется: сущая мелочь, но и с ней надо уметь справиться.
Как узнать объём текста? Предлагаю вашему вниманию несколько удобных вариантов.
Редактор Word (или другая программа для работы с текстом). Когда вы набираете символы в Office, внизу страницы ведётся подсчёт слов и символов с пробелами.
Чтоб увидеть всю статистику, кликните на надпись внизу, и перед глазами появится табличка, как на картинке (изображение увеличивается).
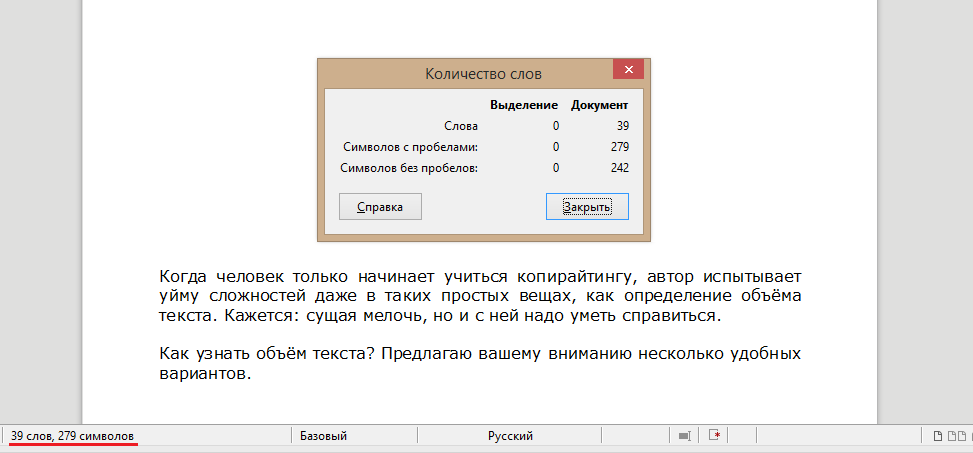
Подсчёт объёма текста в Word
TextAnalyzer. Об этом сервисе для вебмастеров я уже писала. Онлайн-инструмент выручает меня в работе над SEO-статьями. Закиньте контент в редактор, кликните на кнопку, и всего через две секунды вы сможете узнать объём текста (с пробелами и без).
Также посчитать объём текста легко в Istio.com, Content Watch, 1y.ru, text.ru или других сервисах для «сеошников», копирайтеров, журналистов.
Как видите, узнать объём текста не составляет никакого труда. В следующий раз расскажу в блоге о том, как определить объём текста с учётом ключевых слов. Этот материал будет полезен тем, кто осваивает SEO-копирайтинг. Удачи начинающим авторам!
Определение количества информации в сообщении

Все мы привыкли к тому, что все вокруг можно измерить. Мы можем определить массу посылки, длину стола, скорость движения автомобиля. Но как определить количество информации, содержащееся в сообщении? Ответ на вопрос в статье.
Итак, давайте для начала выберем сообщение. Пусть это будет «Принтер — устройство вывода информации.«. Наша задача — определить, сколько информации содержится в данном сообщении. Иными словами — сколько памяти потребуется для его хранения.
Определение количества информации в сообщении
Для решения задачи нам нужно определить, сколько информации несет один символ сообщения, а потом умножить это значение на количество символов. И если количество символов мы можем посчитать, то вес символа нужно вычислить. Для этого посчитаем количество различных символов в сообщении. Напомню, что знаки препинания, пробел — это тоже символы. Кроме того, если в сообщении встречается одна и та же строчная и прописная буква — мы считаем их как два различных символа. Приступим.
В слове Принтер 6 различных символов (р встречается дважды и считается один раз), далее 7-й символ пробел и девятый — тире. Так как пробел уже был, то после тире мы его не считаем. В слове устройство 10 символов, но различных — 7, так как буквы с, т и о повторяются. Кроме того буквы т и р уже была в слове Принтер. Так что получается, что в слове устройство 5 различных символов. Считая таким образом дальше мы получим, что в сообщении 20 различных символов.
Далее вспомним формулу, которую называют главной формулой информатики:
Подставив в нее вместо N количество различных символов, мы узнаем, сколько информации несет один символ в битах. В нашем случае формула будет выглядеть так:
Вспомним степени двойки и поймем, что i находится в диапазоне от 4 до 5 (так как 2 4 =16, а 2 5 =32). А так как бит — минимальная единица измерения информации и дробным быть не может, то мы округляем i в большую сторону до 5. Иначе, если принять, что i=4, мы смогли бы закодировать только 2 4 =16 символов, а у нас их 20. Поэтому получаем, что i=5, то есть каждый символ в нашем сообщении несет 5 бит информации.
Осталось посчитать сколько символов в нашем сообщении. Но теперь мы будем считать все символы, не важно повторяются они или нет. Получим, что сообщение состоит из 39 символов. А так как каждый символ — это 5 бит информации, то, умножив 5 на 39 мы получим:
5 бит x 39 символов = 195 бит
Это и есть ответ на вопрос задачи — в сообщении 195 бит информации. И, подводя итог, можно написать алгоритм нахождения объема информации в сообщении:
Как посчитать байты в предложении
Для информации существуют свои единицы измерения информации. Если рассматривать сообщения информации как последовательность знаков, то их можно представлять битами, а измерять в байтах, килобайтах, мегабайтах, гигабайтах, терабайтах и петабайтах.
Давайте разберемся с этим, ведь нам придется измерять объем памяти и быстродействие компьютера.
Единицей измерения количества информации является бит – это наименьшая (элементарная) единица.
Байт – основная единица измерения количества информации.
Байт – довольно мелкая единица измерения информации. Например, 1 символ – это 1 байт.
Производные единицы измерения количества информации
1 килобайт (Кб)=1024 байта =2 10 байтов
1 мегабайт (Мб)=1024 килобайта =2 10 килобайтов=2 20 байтов
1 гигабайт (Гб)=1024 мегабайта =2 10 мегабайтов=2 30 байтов
1 терабайт (Гб)=1024 гигабайта =2 10 гигабайтов=2 40 байтов
Методы измерения количества информации
Итак, количество информации в 1 бит вдвое уменьшает неопределенность знаний. Связь же между количеством возможных событий N и количеством информации I определяется формулой Хартли:
Алфавитный подход к измерению количества информации
При этом подходе отвлекаются от содержания (смысла) информации и рассматривают ее как последовательность знаков определенной знаковой системы. Набор символов языка, т.е. его алфавит можно рассматривать как различные возможные события. Тогда, если считать, что появление символов в сообщении равновероятно, по формуле Хартли можно рассчитать, какое количество информации несет в себе каждый символ:
Вероятностный подход к измерению количества информации
Этот подход применяют, когда возможные события имеют различные вероятности реализации. В этом случае количество информации определяют по формуле Шеннона:
I – количество информации,
N – количество возможных событий,
Pi – вероятность i-го события.
Задача 1.
Шар находится в одной из четырех коробок. Сколько бит информации несет сообщение о том, в какой именно коробке находится шар.
Имеется 4 равновероятных события (N=4).
По формуле Хартли имеем: 4=2 i . Так как 2 2 =2 i , то i=2. Значит, это сообщение содержит 2 бита информации.
Задача 2.
Чему равен информационный объем одного символа русского языка?
В русском языке 32 буквы (буква ё обычно не используется), то есть количество событий будет равно 32. Найдем информационный объем одного символа. I=log2 N=log2 32=5 битов (2 5 =32).
Примечание. Если невозможно найти целую степень числа, то округление производится в большую сторону.
Задача 3.
Чему равен информационный объем одного символа английского языка?
Задача 4.
Световое табло состоит из лампочек, каждая из которых может находиться в одном из двух состояний (“включено” или “выключено”). Какое наименьшее количество лампочек должно находиться на табло, чтобы с его помощью можно было передать 50 различных сигналов?
С помощью N лампочек, каждая из которых может находиться в одном из двух состояний, можно закодировать 2 N сигналов.
2 5 6 , поэтому пяти лампочек недостаточно, а шести хватит. Значит, нужно 6 лампочек.
Задача 5.
Метеостанция ведет наблюдения за влажностью воздуха. Результатом одного измерения является целое число от 0 до 100, которое записывается при помощи минимально возможного количества битов. Станция сделала 80 измерений. Определите информационный объем результатов наблюдений.
В данном случае алфавитом является множество чисел от 0 до 100, всего 101 значение. Поэтому информационный объем результатов одного измерения I=log2101. Но это значение не будет целочисленным, поэтому заменим число 101 ближайшей к нему степенью двойки, большей, чем 101. это число 128=2 7 . Принимаем для одного измерения I=log2128=7 битов. Для 80 измерений общий информационный объем равен 80*7 = 560 битов = 70 байтов.
Задача 6.
Определите количество информации, которое будет получено после подбрасывания несимметричной 4-гранной пирамидки, если делают один бросок.
Пусть при бросании 4-гранной несимметричной пирамидки вероятности отдельных событий будут равны: p1=1/2, p2=1/4, p3=1/8, p4=1/8.
Тогда количество информации, которое будет получено после реализации одного из них, можно вычислить по формуле Шеннона:
Задача 7.
Задача 8.
Оцените информационный объем следующего предложения:
Тяжело в ученье – легко в бою!
Так как каждый символ кодируется одним байтом, нам только нужно подсчитать количество символов, но при этом не забываем считать знаки препинания и пробелы. Всего получаем 30 символов. А это означает, что информационный объем данного сообщения составляет 30 байтов или 30 * 8 = 240 битов.
Как посчитать байты?
Более того, сколько байтов в MG?
Первоначально мегабайт использовался для описания кратного байта (2 20 = 1024 x 1024 = 1,048,576 XNUMX XNUMX) в компьютерном программировании. Однако несколько международных организаций и большинство носителей информации (включая жесткие диски и DVD) используют латинский подход к измерению, в соответствии с которым мегабайт является 10 3 байт (1000 x 1000 = 1,000,000.)
Сколько байтов в слове?
Типы различных единиц памяти
| Имя и фамилия | Равно | Размер (в байтах) |
|---|---|---|
| Байт | Биты 8 | 1 |
| килобайт | 1024 Б | 1024 |
| мегабайт | 1, 024 Килобайт | 1, 048, 576 |
8 Mb = 1 МБ. 1 мегабит = 1/8 мегабайта = 0.125 мегабайта. 1 МБ = 1/8 МБ = 0.125 МБ.
Сколько байтов в 1024 КБ?
1 килобайт
равен 1024 байтам (двоичный).
Килобайт против байтов.
| Килобайт (КБ) | Байт (B) |
|---|---|
| 1,024 байт | 1 байт |
| 1,000 × 8 бит | 1 × 8 бит |
| 8,000 биты | 8 биты |
Почему 1 МБ равен 1024 байтам?
Но в мегабайте действительно 1024 килобайта. Причина этого потому что компьютеры основаны на двоичной системе. Это означает, что жесткие диски и память измеряются в степени двойки.
Сколько байтов в 4 словах?
| слово | B |
|---|---|
| 4 | = 8 |
| 5 | = 10 |
| 6 | = 12 |
| 7 | = 14 |
Почему слово 2 байта?
Если символ 8 бит или 1 байт, то СЛОВО должно быть в минимум 2 символов, поэтому 16 бит или 2 байта.
Сколько байтов в предложении?
Сколько байтов в предложении? Символы ASCII всегда представлены одним байтом, и все компьютеры, по крайней мере, за последние 40 лет, имеют 8-битный байт. Таким образом, поскольку в этом предложении 12 символов (посчитайте пробелы!), Есть 12 байт и 96 бит.
Сколько байтов требуется для реальных 20?
Какой самый большой размер байта?
Итак, что будет после терабайт? По состоянию на 2018 год йоттабайт (1 септиллион байт) был самым крупным утвержденным стандартным размером хранилища Системой единиц (СИ). Для контекста, есть 1,000 терабайт в петабайте, 1,000 петабайт в эксабайте, 1,000 эксабайт в зеттабайте и 1,000 зеттабайт в йоттабайте.
Сколько МБ составляет 40 Мбит / с?
Сколько мегабайт в секунду в мегабитах в секунду? 1 мегабайт / сек равен 8 × мегабит / сек. 1 Мегабит / с = 0.125 Мегабайт / сек.
МБ больше, чем КБ?
Сколько МБ в 150 Мбит / с?
Это означает, что если ваша скорость передачи данных составляет 150 Мбит / с, вы можете передавать 18.75 МБ в секунду (МБ / с).
КБ больше, чем ГБ?
Другие размеры файлов, о которых нужно знать
Что вы называете 1024 байтами?
Килобайт (КБ) составляет 1,024 байта, а не одну тысячу байтов, как можно было бы ожидать, потому что компьютеры используют двоичную (основание два) математику вместо десятичной (десятичной) системы. Хранилище и память компьютера часто измеряются в мегабайтах (МБ) и гигабайтах (ГБ).
Сколько ГБ в 1024?
Конвертировать 1024 мегабайт в гигабайты
| 1024 мегабайт (МБ) | 1.000001 Gigabytes (Гб) |
|---|---|
| 1 МБ = 0.000977 ГБ | 1 ГБ = 1,024 МБ |
Что больше МБ или ГБ?
Мегабайт (МБ) составляет 1,024 килобайта. А гигабайт (ГБ) это 1,024 мегабайта.
Как называется 1024 ТБ?
Петабайт (PB) составляет 1,024 ТБ. Из 1 ПБ данных, если они записаны на DVD, будет создано примерно 223,100 878 DVD, т. Е. Стопка высотой около 1,024 футов или стопка компакт-дисков высотой в милю. Университет Индианы в настоящее время создает системы хранения, способные хранить петабайты данных. Эксабайт (ЭБ) составляет XNUMX ПБ.
Почему у байтов всего 8 бит?
Сколько символов в 1024 байтах?
Один байт = 1 символ. 1 килобайт = 1024 байта = 1024 символа. 1 мегабайт = 1024 килобайта = 1,048,576 1,048,576 байт = XNUMX XNUMX символов.
Как называется 16 бит?
Общая длина двоичного числа
Каждая 1 или 0 в двоичном числе называется битом. Оттуда группа из 4 битов называется полубайтом, а 8-битные составляют байт. … Это может быть 16, 32, 64 или даже больше.
Сколько байтов в абзаце?
16 байт: параграф (на процессорах Intel x86)
Как посчитать байты в предложении
· упаковка данных, архивирование. Естественно уплотнение данных производить с точностью не до байта, а до бита;
· алгоритмы сортировок и структуры данных, использующие элементы внутреннего представления хранимых данных: поразрядные сортировки, кодовые деревья;
· моделирование машинной арифметики. Если нас не устраивает точность представления данных, принятая в компьютере, мы сможем программно смоделировать данные более высокой точности. При этом можно пользоваться разными формами их представления, в том числе принятыми двоичными форматами данных;
· работа с растрами, битовыми картами ( bitmap). Например, для контроля свободного пространства на диске файловая система часто использует карту памяти – массив байтов, каждый разряд которого определяется состояние отдельного блока: 0 – свободен, 1 – занят.
long vv ; // Машинное слово двойной длины
for(int i=0; i // Количество разрядов в long
< … vv … >// Цикл поразрядной обработки слова
Поразрядные операции и их интерпретация
Операции, которые выполняют различные операции (в основном, логические) над отдельными разрядами машинного слова, называются поразрядными. В стандартной классификации операций по приоритетам они относятся к различным группам. В качестве операндов у них часто используются константы, именуемые масками. Маска – это константа, с определенной расстановкой единичных и нулевых разрядов. Естественно, коль скоро речь идет о двоичном представлении, то наиболее удобным является использование эквивалента в виде шестнадцатеричных констант.
Прежде всего, необходимо вспомнить основные отношения размерностей ( 1.3): одна шестнадцатеричная цифра кодирует значения четырех двоичных разрядов (тетрада), байт представляется двумя цифрами. Как правило, в маске устанавливаются в 1 отдельные разряды, либо группы рядом стоящих разрядов (битовые поля):
Часто требуется, чтобы маска была программируемой, задаваемой во время работы программы. В этом случае нужно организовать процесс «пробегания» единичного бита по заданному полю.
Образно говоря, машинное слово – это массив двоичных разрядов, и алгоритмы работы с машинными словами в первом приближении аналогичны алгоритмам, работающим с массивами. Но с точки зрения возможных операций все обстоит с точностью до «наоборот». В «джентльменском наборе» команд процессора отсутствую команды прямой адресации битов. Взамен их используются поразрядные операции, выполняющие одну и ту же логическую операцию или операцию перемещения над всеми разрядами машинного слова одновременно. Другое их название – машинно-ориентированные операции – отражает тот факт, что они поддерживаются в любой системе команд и любом языке Ассемблера. К ним относятся:

Рис.91-1. Схема выполнения поразрядных операций
b = a & 0x0861; // Выделить разряды 0,5,6,11
b = a & 0x00F0; // Выделить разряды с 4 по 7
// (разряды второй цифры справа)
Выделение разрядов по маске может сопровождаться проверкой их значений.
if (( a & 0 x 100)!=0) … // Установлен ли 8-ой разряд –
// (младший разряд второго по счету байта)
a |= 0x0861; // Установить в 1 разряды 0,5,6,11
a |= 0x00F0; // Установить в 1 разряды с 4 по 7
// (разряды второй цифры справа)
0x0861; // Очистить разряды 0,5,6,11, остальные сохранить
0x00F0; // Очистить разряды с 4 по 7, остальные сохранить
// (разряды второй цифры справа)
a ^= 0x0861; // Инвертировать разряды 0,5,6,11
a ^= 0x00F0; // Инвертировать разряды с 4 по 7
// (разряды второй цифры справа)
a // сдвиг влево на одну шестнадцатеричную цифру;
a = 1 // установить 1 в n-й разряд машинного слова.
Операции сдвига часто используются для «подгонки» групп двоичных разрядов к требуемому их местоположению в машинном слове. После чего в дело вступают операции И, ИЛИ для выделения и изменения значений полей.
long a =0 x 12345678; // Поменять местами две младшие цифры
int n=0xFF00; n>>=4; // n=0xFFF0;
unsigned u=0xFF00; u>>=4; // u=0x0FF0;
//— Формирование маски в заданном диапазоне разрядов
long set_mask(int r0, int dn)<
m = 1 // Сдвинуть единичный разряд на r0 разрядов влево
v |= m; // Установить очередной разряд из m в v
m // Переместить единичный бит в следу ющий разряд
//—— Определение разрядности числа
int wordlen ( unsigned long vv )<
for (int i=0; vv!=0; i++, vv>>=1);
//—— Подсчет количества единичных разрядов
int what_is_1( unsigned long n)
< if (n & 1) s++; n >>=1; > // Проверить младший разряд и сдвинуть слово
Алгоритмы поразрядной сортировки
В смысле идей поразрядные сортировки не несут ничего нового, они базируются на известных алгоритмах, основанных на разделении (распределении). Только вот само разделение основано на использовании двоичного представления целых чисел.
//————— Поразрядная сортировка разделением
void bitsort(int A[],int a,int b, unsigned m)<
if (a >= b) return; // Интервал сжался в точку
if (m == 0) return; // Проверяемые разряды закончились
// Разделить массив на две части по значению разряда,
// установленного в маске m
int j,vv; // Цикл разделения массива
if ((A[i] & m) ==0) // Слева с разрядом =0
i++, j—; // Обмен и сдвиг границ
bitsort(A,a,j,m >>1); // Рекурсивный вызов
bitsort(A,i,b,m >>1); > // для следующего разряда
Для самого первого вызова рекурсивной функции для всего исходного массива необходимо определить старший значащий разряд в его элементах. Для этого ищется максимальный элемент и для него определяется маска единичного разряда m, пробегающая последовательно все разряды справа налево до тех пор, пока она не превысит значение этого максимума.
void mainsort(int B[], int n)<
int max,i; unsigned m;
if (B[i] > max) max = B[i];
for ( m =1; m max ; m // Единичная маска, превышающая максимум
m >>=1; // Старший разряд разделения
Замечание: отрицательные значения вносят свои коррективы в связи с особенностью их форм представления. Ведь поразрядная сортировка фактически работает в формате беззнакового представления. Дополнительный код (см. 1.3) отображает отрицательные числа в область больших беззнаковых (положительных), переворачивая диапазон представления. В соответствии с этим отрицательные числа будут располагаться после положительных, причем отсортированными в обратном порядке. И, наконец, в качестве первого разряда разделения нужно брать старший (знаковый) разряд.
for ( m =1, i =0; i sizeof ( int )-1; i ++; m // Двигать до старшего (знакового) разряда
//—— Поразрядная лексикографическая сортировка
void sort(int in[], int n)
int * v 0= new int [ n ]; // Создать 2 «кармана»
if (in[i] > max) max=in[i];
for (m=1; m // для каждого разряда, начиная с младшего
for (i=i0=i1=0;i // распределить в 2 кармана по значению
v 0[ i 0++]= in [ i ]; // очередного разряда (двоичной цифры)
delete []v0; delete []v1;>
 Поразрядная распределяющая сортировка. Рецепт: возьмите идеи распределения по карманам, использования на каждом шаге очередного двоичного разряда, но от старшего к младшему и слияния последовательностей, то получите поразрядную распределяющую сортировку. Парадокс в том, что получаемые в карманах последовательности не являются упорядоченными, тем не менее, к ним применяется классическое слияние как для упорядоченных последовательностей. Интуитивное объяснение всего происходящего: при слиянии меньшие значения постепенно перемещаются вперед.
Поразрядная распределяющая сортировка. Рецепт: возьмите идеи распределения по карманам, использования на каждом шаге очередного двоичного разряда, но от старшего к младшему и слияния последовательностей, то получите поразрядную распределяющую сортировку. Парадокс в том, что получаемые в карманах последовательности не являются упорядоченными, тем не менее, к ним применяется классическое слияние как для упорядоченных последовательностей. Интуитивное объяснение всего происходящего: при слиянии меньшие значения постепенно перемещаются вперед.
//—— Поразрядная распределяющая сортировка
void sort(int in[], int n)
int *v0=new int[n]; // Создать 2 «кармана»
if (in[i] > max) max=in[i]; // Определение максимального
for (m=1; m // значащего разряда
for (i0=i1=0; i0+i1 // Распределение по значению
if ((in[i0+i1] & m) ==0) // очередного разряда
for (i0=i1=0; i0+i1 // Обычное слияние
if (v0[i0] // по сравнению значений
in[i0+i1] = v0[i0], i0++; // в последовательности
in[i0+i1] = v1[i1], i1++; // max+1 играет роль ограничителя
> delete []v0; delete []v1;>
Упаковка данных полями переменной длины
Наибольшую плотность упаковки можно достичь, если сделать границы слов (байтов) «прозрачными», представив упакованные данные в виде неограниченной последовательности разрядов, «плотно» уложенных в массиве машинных слов (байтов). Для того, чтобы вынести за скобки часть программы, работающую с отдельными двоичными разрядами и их группами (полями), и, учитывая тот факт, что разряды записываются и извлекаются только последовательно, разработаем две функции добавления и выделения очередного разряда по заданному номеру. Он будет передаваться ссылкой на переменную – счетчик, которая увеличивается при каждом вызове функции.
//——— Извлечение и запись разряда (бита)
int nb = n/8; // номер байта
int ni = n%8; // номер разряда в байте
return (c[nb]>>ni) & 1; > //сдвинуть к младшему и выделить
void putbit(char c[], int &n, int v )<
int nb = n /8; // Сформировать маску разряда ni
int ni = n %8; // очистить старое по маске и установить
n ++; // новый разряд, сдвинув его в позицию ni
Функция, извлекающая последовательность разрядов числа (младшими вперед), производит повторную сборку их в машинное слово заданной размерности с использованием операций сдвига и поразрядного ИЛИ. Функция упаковки слова выделяет последовательность битов, начиная с младшего, используя операцию сдвига, и вызывает функцию записи разряда.
//——- Извлечение слова заданной размерности
unsigned long getword(char c[], int &n, int sz) <
void putword(char c[], int &n, int sz, long v)<
//—- Упаковка и распаковка переменных различной размерности
case 0: return ; // 00 – конец последовательности
if(vv==0) putword(c,n,2,0); // запись 2-разрядного кода 00
else if (vv putword(c,n,2,1); // запись 2-разрядного кода 01
putword(c,n,8,vv);> // запись 8-разрядного кода числа
else if (vv putword(c,n,2,2); // запись 2-разрядного кода 10
putword(c,n,16,vv);> // запись 16-разрядного кода числа
putword(c,n,2,3); // запись 2-разрядного кода 11
putword(c,n,32,vv);> // запись 32-разрядного кода числа
Машинная арифметика произвольной точности
Для понимания ниже изложенного материала необходимо детально проработать п. «1.3. Описание данных. Типы данных и переменные» в той его части, которая касается двоичной и шестнадцатеричной систем счисления, машинных слов и основ внутреннего представления данных.
Поразрядные операции более примитивными, чем арифметические. Именно потому на их основе можно запрограммировать алгоритмы выполнения арифметических операций, использующих форматы внутреннего (двоичного) представления данных. Естественно, это имеет смысл не для воспроизведения уже имеющегося, а, например, для создания арифметики произвольной точности. В предлагаемом примере программно моделируются целые (со знаком) произвольной размерности, представленные массивами беззнаковых байтов в форме, соответствующей их внутреннему представлению в памяти (дополнительный код).
Операция сложения выполняется побайтно. Возникающий при сложении двух байтов перенос (8-й разряд, выделяемый маской 0x0100) используется в операции сложения следующих двух байтов.
//——Сложение целых произвольной разрядности
typedef unsigned char uchar;
void add(uchar out[], uchar in1[], uchar in2[], int n)
unsigned w; // Рабочая переменная для сложения двух байтов
out [i] = w = in1[i]+in2[i]+carry;
carry = (w & 0x0100) >>8; // Разряд переноса сдвинуть вправо на 8
Для того, чтобы продемонстрировать работоспособность алгоритма и соответствие его принятым форматам представления данным, необходимо взять в качестве параметров функции любой базовый тип (например, long ), сформировать на него указатель как на область памяти, заполненную беззнаковыми байтами.
long a=125000, b=30000, c;
Для моделирования операции вычитания необходимо сформировать дополнительный код числа: произвести побайтную инверсию и добавить 1 к результату. Последнее можно сделать, установив первоначально в 1 перенос и распространив его по массиву байтов, аналогично сложению.
//—— Получение отрицательного числа в дополнительном коде
typedef unsigned char uchar;
void neg(uchar in[], int n)
unsigned w; // Рабочая переменная для сложения двух байтов
for (i=0; i // Инвертированин всех разрядов
in [i] = w = in[i]+carry; // установкой переноса в 1
Для моделирования операции умножения необходимо реализовать операции сдвига на 1 разряд влево и вправо.
//——Сдвиг целых произвольной разрядности
void lshift(uchar in[], int n)
z =( in [ i ] & 0 x 80)>>7; // Выделить старший разряд (перенос)
in[i] // Сдвинуть влево и установить
in[i] |=carry; // старый перенос в младший разряд
carry = z; // Запомнить новый перенос
void rshift(uchar in[], int n) // Сдвиг арифметический
z = in[i] & 1; // Выделить младший разряд (перенос)
in[i] >>= 1; // Сдвинуть вправо и установить
in[i] |= carry // старый перенос в старший разряд
carry = z; // Запомнить новый перенос
В переменной carry запоминается значение старшего (младшего) разряда, который переносится в следующий байт на место младшего (старшего). Сдвиг влево происходит от младшего байта к старшему, вправо – наоборот. Сдвиг вправо – арифметический, освобождающийся старший разряд старшего байта устанавливается как копия сдвигаемого (начальное значение переноса carry). Это обеспечивает сохранение знака отрицательного числа при сдвиге вправо (аналог деления на 2).
В операции умножения реализован самый простой алгоритм сложения и сдвига. Он, как и все алгоритмы машинной арифметики для внутреннего представления данных, использует свойства двоичной системы.
cc = aa*bb = aa * Σ bbi * 2 i = Σ bbi *(aa * 2 i )
//——Умножение целых произвольной разрядности
void mul(uchar out[], uchar aa[], uchar bb[], int n)
for (i=0; i // Цикл по количеству разрядов
if (bb[0] & 1 ) // Разряд множителя равен 1
add(out,out,aa,n); // Добавить множимое к произведению
Арифметика в других формах представления данных
В арифметике произвольной точности совсем не обязательно придерживаться форматов внутреннего представления даже двоичной системы. Данные могут быть представлены десятичной системе счисления, при этом операции производятся над каждой цифрой числа отдельно с учетом взаимного влияния десятичных разрядов через переносы, заемы, то есть так, как «учат в школе». Возможны два варианта представления десятичных цифр :
Например, число 17665 выглядит в этих формах представления следующим образом :
long ss=0x00017655; // или
В качестве иллюстрации технологии работы с отдельными цифрами числа в десятичной системе счисления рассмотрим пример функции, добавляющей 1 к числу во внешней форме представления, то есть в виде текстовой строки. Добавление 1 состоит в поиске первой цифры, отличной от 9, к которой добавляется 1. Все встречающиеся «на пути» цифры 9 превращаются в 0. Если процесс «превращения девяток» доходит до конца строки, то производится расширение строки следующей цифрой 1.
//—— Инкремент числа во внешней форме представления
for (int i=0; s[i]!=0; i++); // Поиск конца строки
if ( s [ n ]==’9′ ) // 9 превращается в 0
else < s [ n ]++; return ; >> // добавить 1 к цифре и выйти
for (s[i+1]=0; i>0; i—) s[i]=’0′ ; // Записать в строку 1000.
Другие арифметические операции также моделируются по принципу «цифра за цифрой». Так, при сложении суммируется очередная пара цифр, переведенных во внутреннее представление, и при получении результирующей суммы, превышающей 9, формируется перенос в следующий разряд. Вычитание производится, соответственно, с учетом заема.
//—— Сложение чисел во внешней форме представления
void add(char out[],char c1[],char c2[])<
int l 1= strlen ( c 1)-1; // Определение разрядности суммы
int l 2= strlen ( c 2)-1; // и индексов младших цифр слагаемых
int l=l1; if (l2>l1) l=l2;
l ++; out [ l +1]=0; // В сумме на 1 цифру больше
v = v 1+ v 2+ carry ; // Сложение с учетом входного
else carry =0; // переноса (во внутренней форме)
out [ l ]= v +’0′; // Запись цифры результата
Лабораторный практикум
1. Программа деления целых чисел произвольной длины во внутреннем представлении с использованием операций вычитания, инкремента и проверки на знак результата. Частное определяется как количество вычитаний делителя из делимого до появления отрицательного результата (проверить на переменных типа long).
2. Программа деления целых чисел произвольной длины во внутреннем представлении с восстановлением остатка. Очередной разряд частного определяется вычитанием делителя из делимого. Если результат положителен, то разряд равен 1, если отрицателен, то делитель добавляется к делимому (восстановление остатка) и разряд частного считается равным 0. После каждого вычитания делимое и частное сдвигаются на 1 разряд влево. Перед началом операции делитель выравнивается с делимым путем сдвига на n /2 разрядов влево.
3. Умножение чисел произвольной длины, представленных непосредственно строками цифр. Первоначально формируется строка символов произведения с необходимым количеством нулей. Далее для каждой пары цифр сомножителей к нему добавляется частичное произведение: значения цифр переводятся во внутреннюю форму и перемножаются, после чего выделяется младшая и старшая цифры результата, которые суммируются с соответствующими цифрами произведения с учетом переноса и его распространения в старшие цифры.
5. Умножение чисел произвольной длины, представленных непосредственно строками цифр. Произведение формируется через многократное сложение одного из множителей с накапливаемым произведением, количество сложений определяется вторым сомножителем.
7. Вычитание чисел произвольной длины, представленных непосредственно строками цифр с использованием дополнительного кода вычитаемого (в десятичной системе счисления).
13. Первые 15 наиболее часто встречающихся символов кодируются 4-битными кодами от 0000 до 1110. Код 1111 обозначает, что следующие за ним 8 бит кодируют один из остальных символов. Разработать функции упаковки и распаковки строки с определением наиболее часто встречающихся символов и коэффициента уплотнения.
Вопросы без ответов
Содержательно сформулируйте результат функции, определите, какие свойства машинного слова и какие действия над ним она производит. Вызов функции оформите с формальным параметром – шестнадцатеричной константой и прокомментируйте полученный результат.