Как посмотреть историю сайта в прошлом? Инструкция и сервисы.

Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
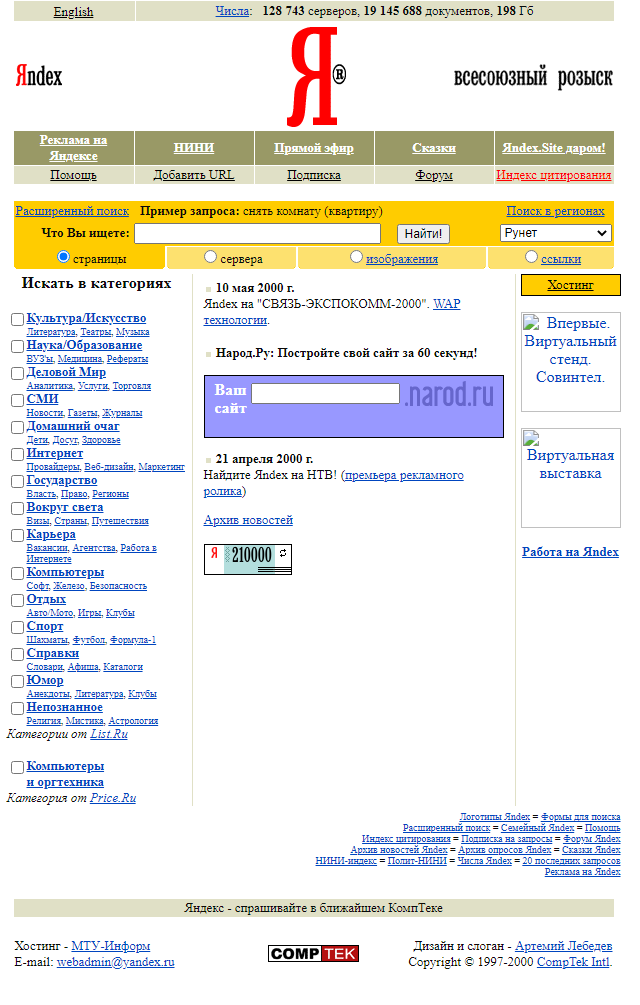
Как посмотреть сайт в прошлом
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.

График ниже показывает количество сохранений: первое было в 1998 году.

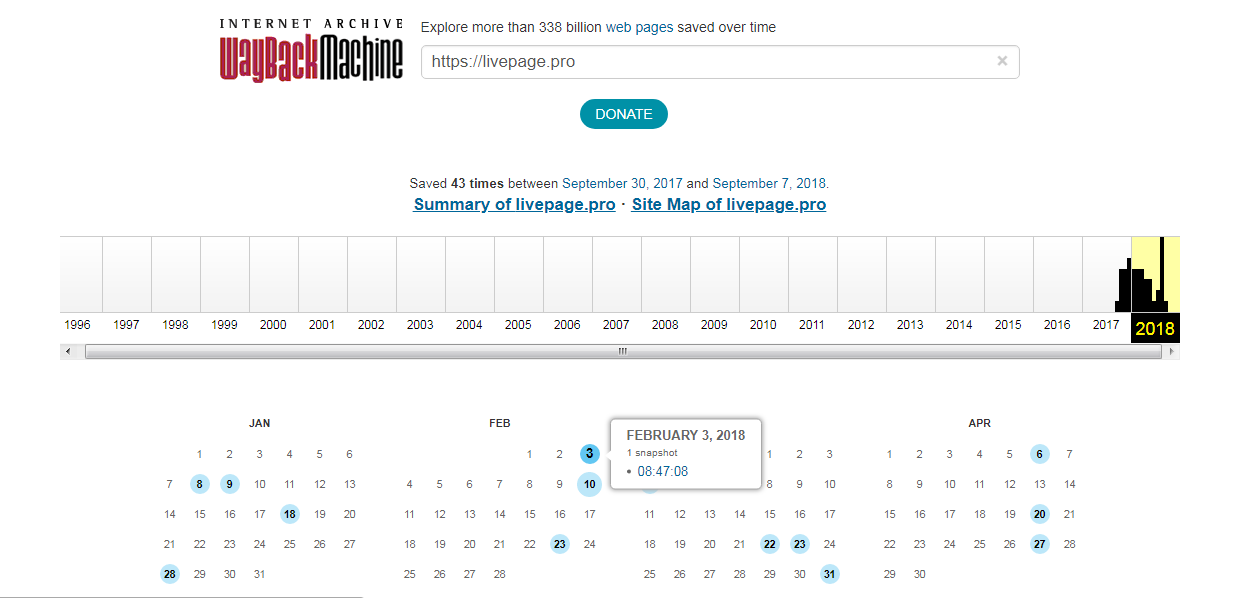
Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:

Как выгрузить сайт из ВебАрхива, расскажем дальше.
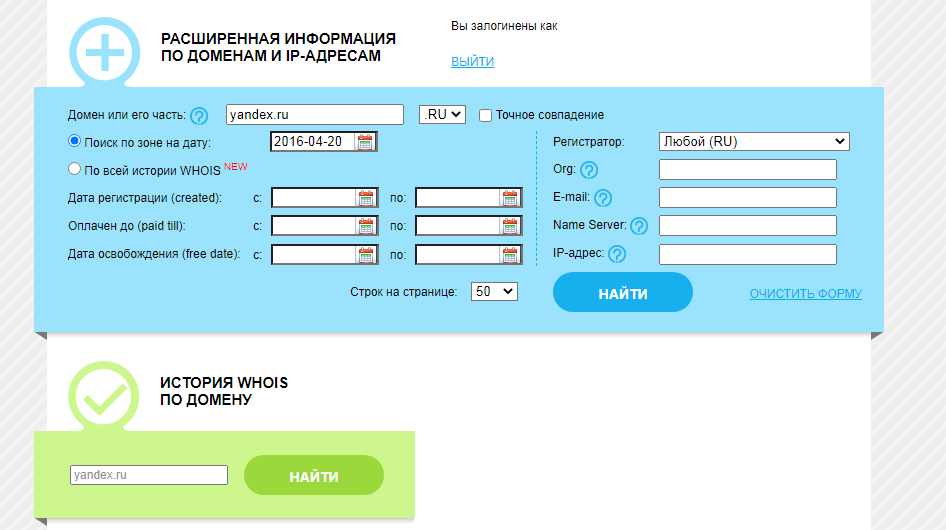
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/ и вводим данные в поиске по доменам и IP, либо по домену:
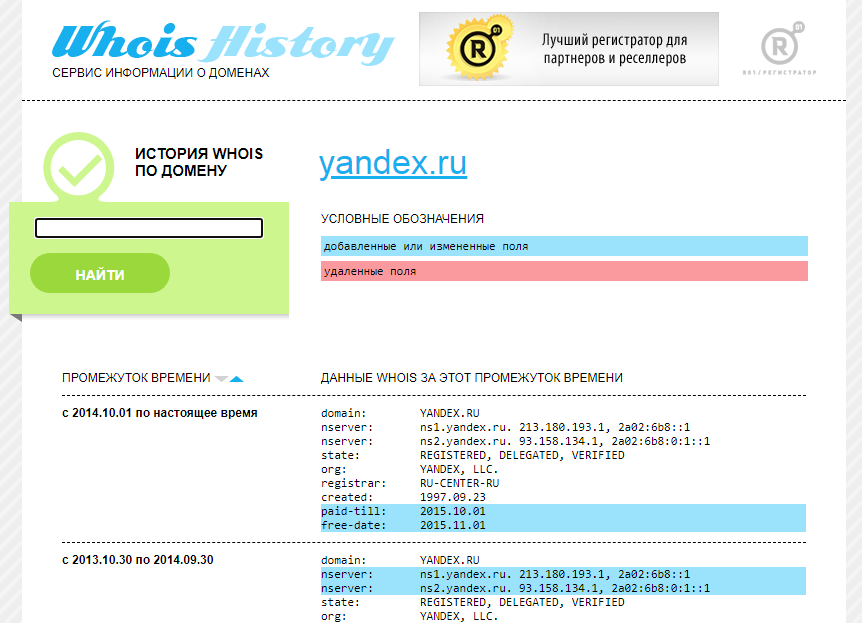
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
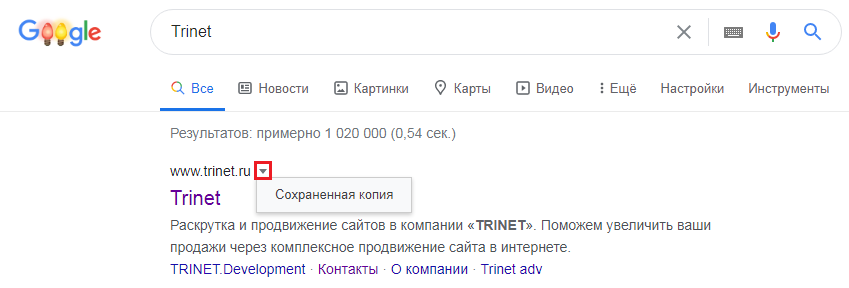
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
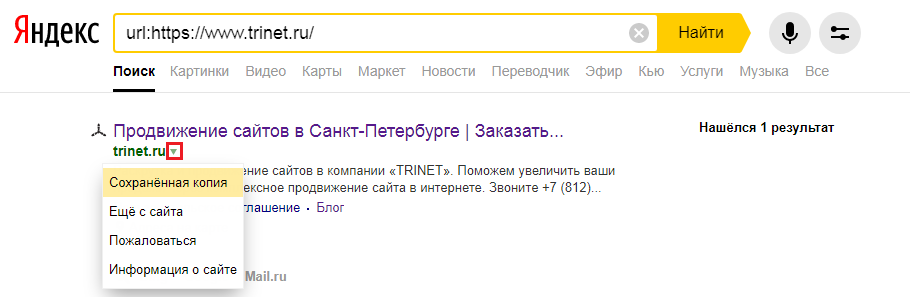
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.

Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:

Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.

Сервис Keys.so
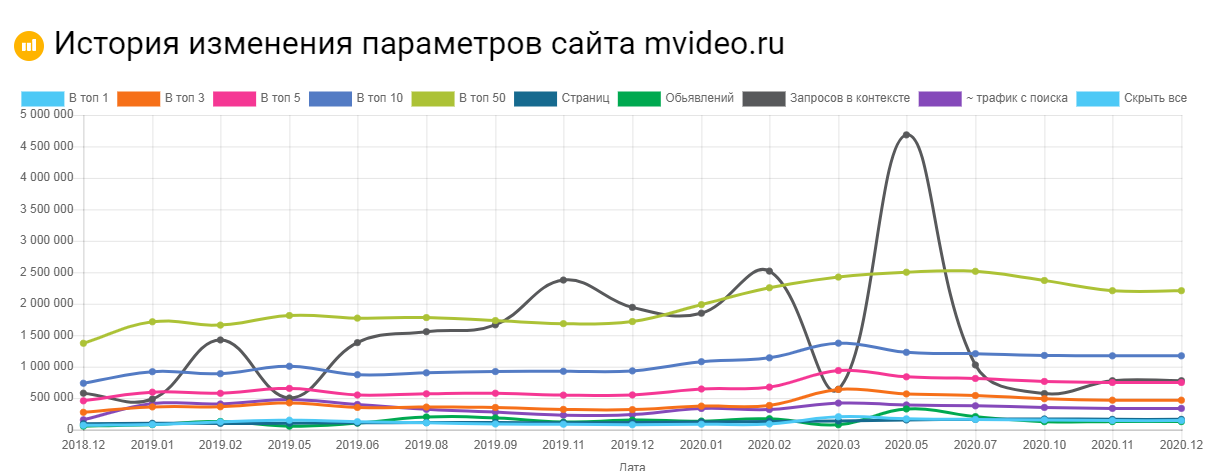
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
Сервис Архиварикс
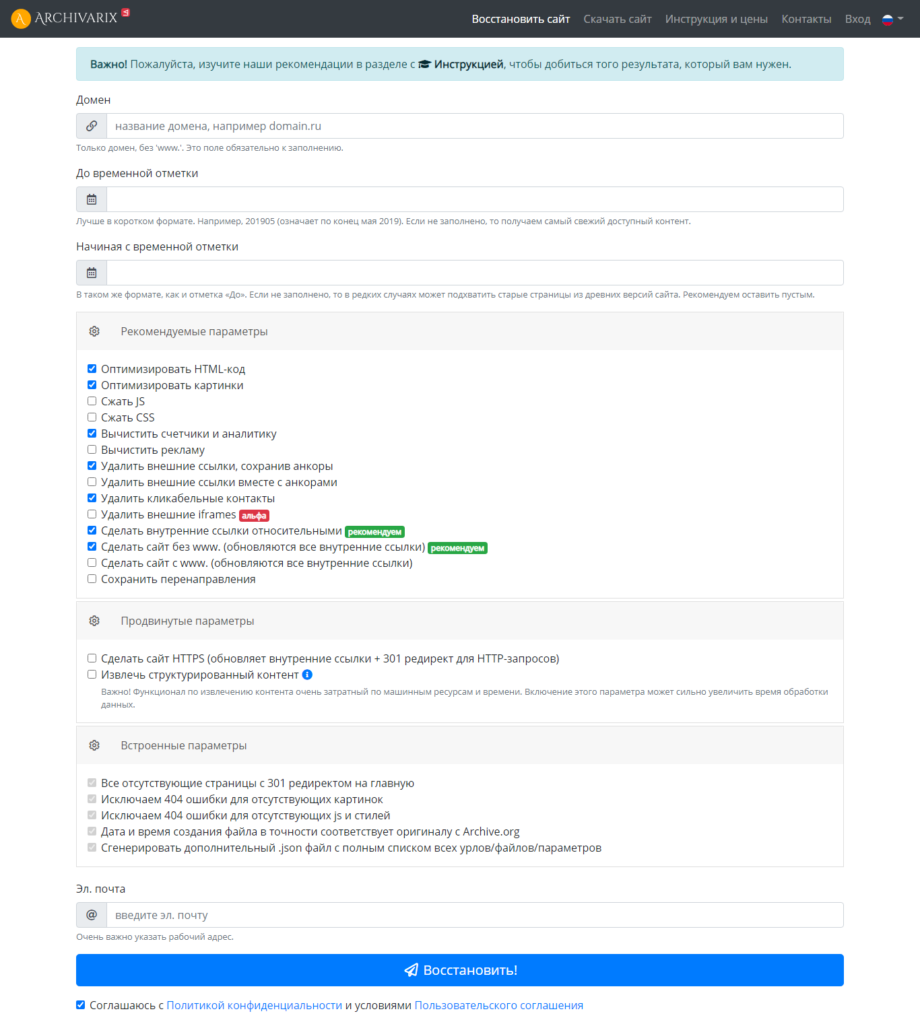
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/ и нажать кнопку «Восстановить».
Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.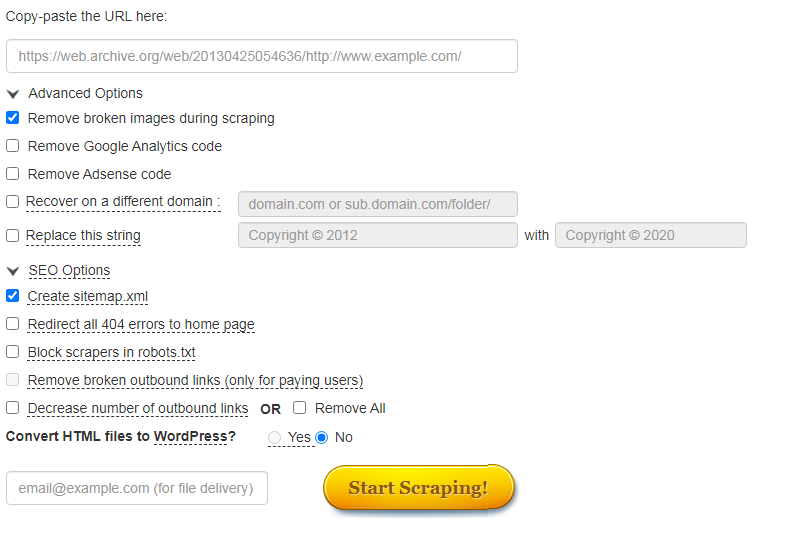
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
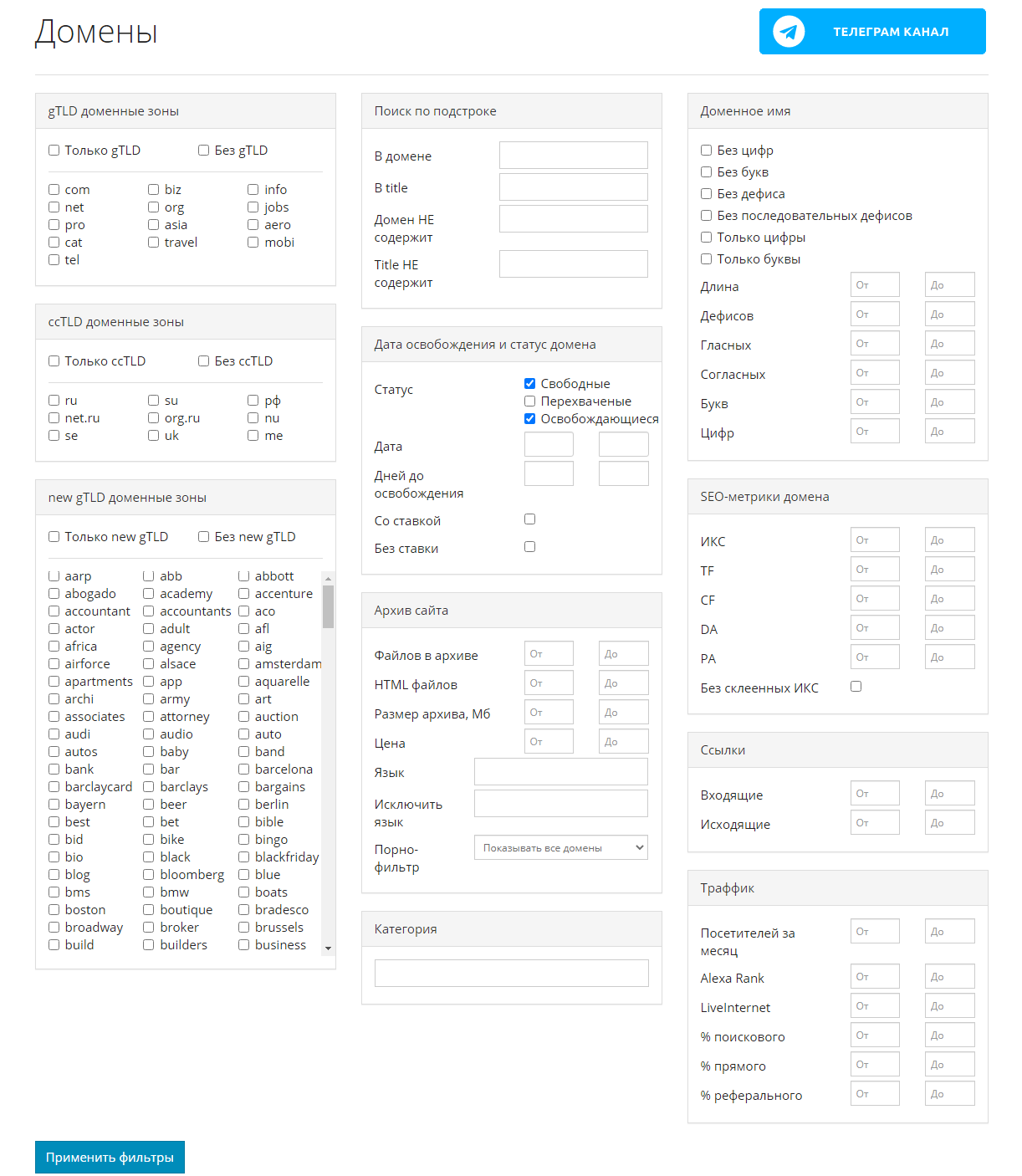
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Плагины
Восстановить сайт из бэкапа можно автоматически с помощью плагинов для CMS. Таких инструментов множество. Например, плагины Duplicator, UpdraftPlus для системы WordPress. Все, что нужно – это иметь резервную копию, которую также можно сделать с помощью этих плагинов, если сайтом владеете вы.
Множество сервисов, предоставляющие хостинг для сайта, сохраняют бэкапы и можно восстановить предыдущую версию собственного проекта.
Заключение
Мы привели примеры основных сервисов, в которых можно посмотреть изменения сайтов и восстановить их содержимое. Список не ограничивается только этими инструментами.
Если у вас есть интересные и проверенные сервисы, о которых мы не упомянули, расскажите в комментариях. А если нужна помощь со скачиванием контента или комплексные услуги по продвижению и созданию сайтов, обращайтесь к нашим специалистам.
9 способов найти удаленный сайт или страницу

Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
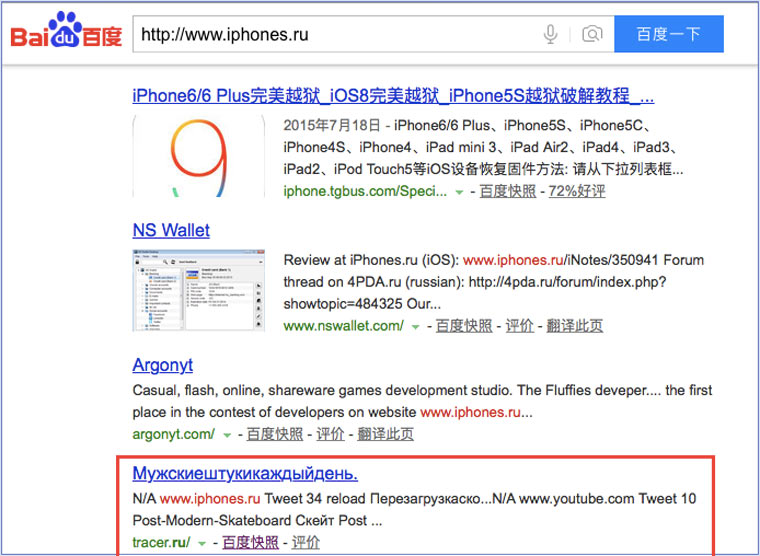
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
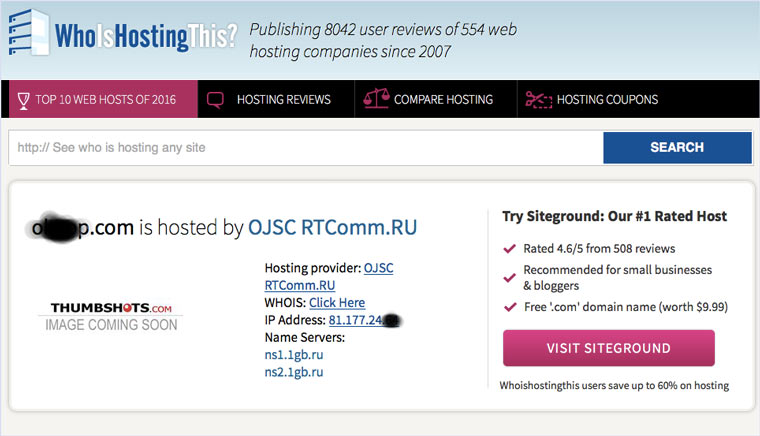
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com: 
Web Archive: как посмотреть, как выглядел сайт раньше?


Интернет в привычном для нас виде появился 36 лет назад — за это время он развивался семимильными шагами, а сайты тысячи раз меняли свой дизайн и контент. Web archive представляет собой своеобразную машину времени, которой может воспользоваться каждый пользователь.
Что такое Web Archive?
Это бесплатный сервис, где собраны истории многих интернет ресурсов — их архивные копии. Причем речь идет не о скриншотах, а о полноценных страницах с изображениями, рабочими ссылками и стилевым оформлением.
Получение информации о том или ином домене предполагает не только интересное времяпровождение с отслеживанием эволюции веб-проекта, но еще и возможность:
История создания архива интернета
Wayback Machine является одним из двух главных проектов archive.org. Этот некоммерческий сервис был создан в 1996 году Брюстером Кейлом. Машина времени сайтов имеет четкую цель: сбор и хранение копий ресурсов вместе со всем контентом для возможности свободного просмотра несуществующих или неподдерживающихся страниц в будущем. С 1999-го робот стал фиксировать еще и аудио, видео, иллюстрации, программное обеспечение.
База современного архива собиралась в течение 20 лет, у нее не существует аналогов. Статистика впечатляет: на сегодняшний день в сервисе находится 279 миллиардов страниц, 11 миллионов книг и статей, 100 тысяч программ и миллион картинок.
А знаете ли вы? Веб-архив сайтов часто имеет проблемы на законодательном уровне из-за нарушения авторских прав. По требованию правообладателей библиотека удаляет материалы из публичного доступа.
Как пользоваться веб-архивом?
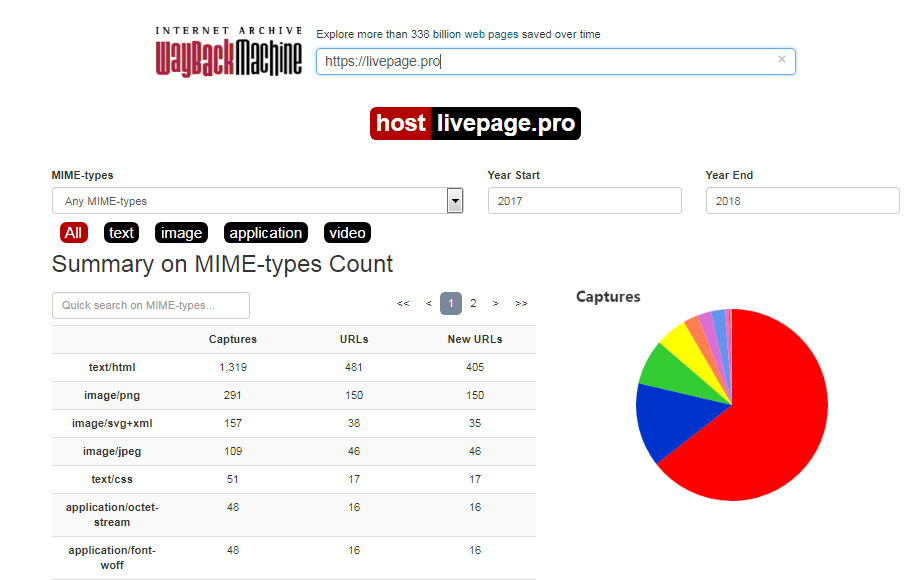
Сервис очень удобный в применении. Пошаговая инструкция такова:

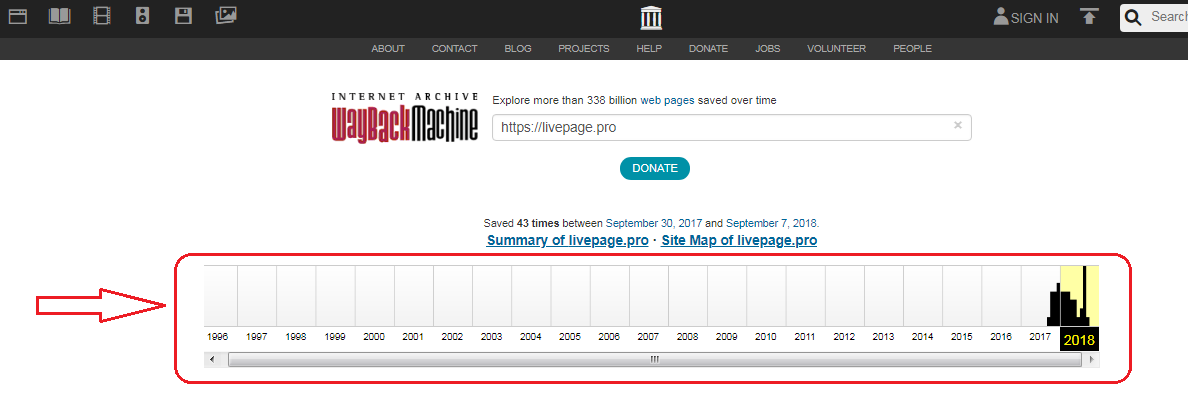
Каждый из них доступен для просмотра: нужно лишь выбрать год, месяц и день сохранения. Мы хотим посмотреть, как выглядел сайт раньше: допустим, 3 февраля текущего года. Наводим курсор на голубой кружок и жмем на время сохранения. Проще не бывает!
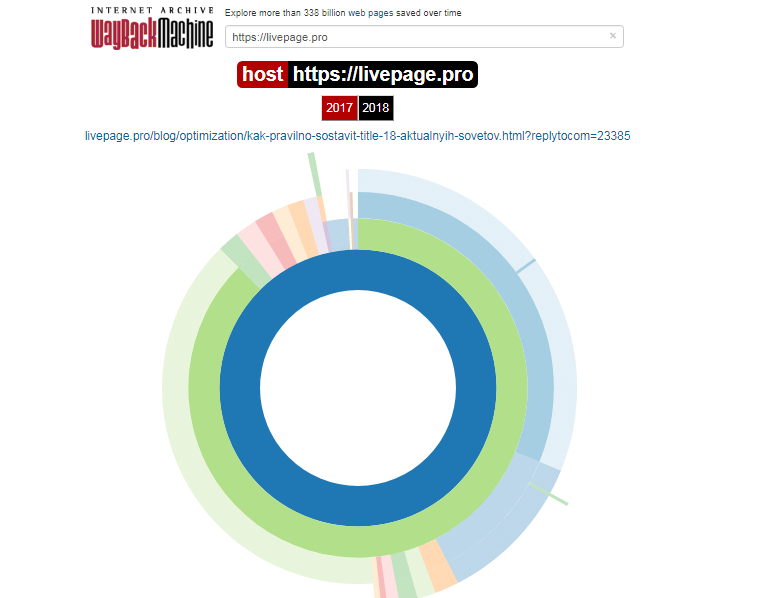
Алгоритм действий можно сократить. Для работы с сервисом напрямую, введите в строке своего браузера
В нашем случае это
Как восстановить сайт из веб-архива?
Плохая новость для тех, кто планирует просто найти архив сайта и скачать его привычным способом: страницы имеют вид статических html-файлов, к тому же их слишком много для того, чтобы заниматься этим вручную. Решить проблему можно при помощи специальных программ, к примеру, приложения на ruby. Необходимо лишь установить все на сервер и запустить восстановление страниц.
apt-get install ruby

gem install wayback_machine_downloader

Для удобства можно указать отметку снапшота — утилита определит число страниц и выведет выкачиваемые файлы на консоль. После скачивания и сохранения мы получим набор статических данных.

Как восстановить сайт без бэкапа?
Вернуть ресурс из небытия можно даже без резервного копирования.
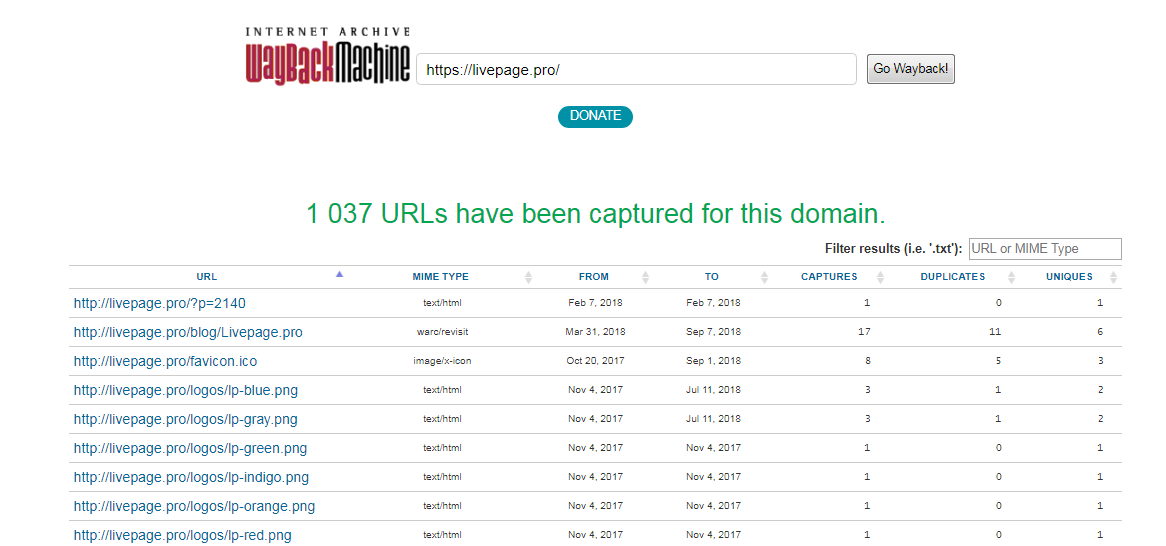
Войдите в режим расширенного поиска и укажите имя сайта. Получив результаты, кликайте по ссылкам «cached» или «копия».
Учтите!
Нужный вам проект может и не входить в архив сайтов интернета. Если вы его не нашли в библиотеке — значит, правообладатель потребовал удаления копий или же ресурс закрыли в соответствии с законом о защите интеллектуальной собственности. Возможен и другой вариант: через файл robots.txt был банально внесен соответствующий запрет.
Как найти уникальный контент из веб-архива для вашего сайта?
Статьи, расположенные на заброшенных ресурсах, обычно не представляют никакой ценности для их бывших владельцев. А ведь в мир иной ежедневно уходят десятки сайтов. И среди кучи хлама, выброшенного на помойку истории, можно найти настоящие самородки — приличные тексты, которые достанутся вам бесплатно.
Поисковики хорошо относятся к любому актуальному и уникальному контенту — можно не бояться попасть в их немилость только из-за того, что статьи взяты из веб-архива чужого сайта.
Итак, последовательность действий следующая:
При разумном подходе такой способ пополнения сайта контентом можно поставить на поток. Поиски материалов на мертвых блогах оправданы экономией времени на написание текстов и денег, которые бы вам пришлось заплатить авторам.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива?
Если вы дорожите контентом и не хотите видеть свою онлайн-площадку в электронной библиотеке, пропишите запретную директиву в файле robots.txt:
User-agent: ia_archiver
Disallow: /
User-agent: ia_archiver-web.archive.org
Disallow: /
После изменения в настройках веб-сканер перестанет создавать архивные копии вашего сайта, к тому же удалит уже сделанные слепки. Однако учтите, что ваш запрет действует лишь до тех пор, пока доступен robots.txt — когда закончится срок регистрации доменного имени, машина времени сайтов станет демонстрировать статьи всем желающим.
Важно! Если вы, наоборот, желаете активно пользоваться веб-архивом, введите соответствующий запрос на главной странице сервиса. Просто укажите адрес проекта в разделе Save Page Now, после чего нажмите кнопку Save Page. Повторяйте процедуру после внесения любых правок.
Аналоги Webarchive
Альтернативой рассматриваемой в обзоре электронной библиотеке может стать:
Архив интернета
Год: 1997
Собственник: Яндекс
Логотипы Яндекса
На сайте собран архив этих логотипов.
Internet Archive
Wayback Machine
Интересно посмотреть, как какой-то сайт выглядел прежде, а может как выглядел мой сайт?
Правда копии содержат не все страницы, когда-то без картинок, сайт Яндекс заблокировал свою историю.
То есть, не требуйте от сайта слишком многого. Архив, он и есть архив. А за ходом интернета сложно уследить, не то, что сохранить. Так что, как уж повезет.
Год: 2013
Собственник: Google
Логотипы Google

Веб-архив сайтов
Он использует базу The Wayback Machine. То есть, сохраняется не все.
Кроме этого, здесь можно за определенную плату восстановить сайт, то есть, получить его рабочую копию. Естественно, из того, что было сохранено.
Недорого, 120-240 руб.

Version Museum
Подобно тому, как прогулка по реальному музею, Музей версий стремится проиллюстрировать визуальные, материальные элементы различных версий технологии, а не только письменную историю, стоящую за ней.
Википедия и другие сайты уже делают фантастическую работу по детализации истории за сайтами, приложениями и всем остальным.
Этот сайт фокусируется на заметных изменениях с течением времени.
Если вы давно пользуетесь тем или иным продуктом, вероятно, будет некоторая ностальгия, когда вы будете смотреть на все предыдущие итерации этого продукта на протяжении многих лет.
На английском языке
Story of the Web
20 лет рунету
Архив интернет
Бесплатный сервис по поиску архивных копий сайтов.
С помощью данного сервиса вы можете проверить внешний вид и содержимое страницы в сети интернет на определенную дату.
База заметно уступает лидеру web.archive.org.
Информацию из Вебархива вы можете использовать в ознакомительных целях, либо для доказывания определенных обстоятельств в суде.
В данном случае рекомендуем вам надлежащим образом зафиксировать или нотариально заверить найденную архивную копию страницы сайта.
Archive.Today
У каждого сайта свои преимущества, мы можем пользоваться обоими в зависимости от нашей задачи.
Эволюция Интернета
Современный Интернет – это постоянно растущее число страниц и веб-приложений, связанных между собой ссылками. Он полон видеороликов, фотографий и интерактивного контента. Однако взаимодействие веб-технологий, благодаря которым все это так слаженно работает, остается скрытым от глаз обычного пользователя.
Веб-технологии постепенно развились до такого уровня, что у разработчиков появилась возможность создавать веб-содержание нового поколения. Сегодняшний Интернет является результатом непрерывных усилий открытого веб-сообщества, которое помогает разрабатывать такие технологии, как HTML5, CSS3 и WebGL, и добивается их поддержки всеми браузерами.
Цветные ленты на инфографике представляют взаимосвязи между веб-технологиями и браузерами, благодаря которым нам доступно столько функциональных веб-приложений.
Как посмотреть на сайт в прошлом: инструмент + способ восстановления

Сервис, который может показать, как выглядели сайты в прошлом, напоминает своеобразную машину времени в интернете. С его помощью можно перенестись на год, два или двадцать лет назад и увидеть, какими ресурсы были тогда. Зачем может понадобиться эта информация и как воспользоваться данным сервисом?
Для чего нужно искать старые версии сайтов
Причины, по которым может быть необходимо посмотреть сайт в прошлом времени, могут быть абсолютно разными. Часто это желание погрузиться в приятную ностальгию. Например, посмотреть, как раньше выглядели популярные площадки и соцсети. Или же посмотреть, как выглядел собственный сайт несколько лет назад. К счастью, существует инструмент, который позволяет это сделать, даже если сам ресурс уже давно не доступен.
Как это возможно? Если сайт существует в интернете хотя бы пару дней, он попадает в веб-архив. Инструмент сохраняет его код, благодаря чему, можно увидеть, как он выглядел даже много лет назад.
Причины, по которым возникает необходимость посмотреть порталы в прошлом времени:
Как узнать прошлое веб-ресурса с помощью archive.org
Чтобы узнать, как выглядел конкретный веб-ресурс ранее, можно воспользоваться сайтом для просмотра страниц в прошлом – a rchive.org. Для этого нужно выполнить следующее:
После этого откроется главная страница в том виде, какой она была в выбранный период.
Учитывайте, что кликабельными в календаре являются только дни, помеченные синим или зеленым цветом. Посмотреть, как выглядел сайт в даты без подсветки, не получится.
Если это страница Вконтакте
Аналогичным образом можно узнать содержимое страницы ВКонтакте. Достаточно указать на нее ссылку в соответствующем поле.
По сравнению с новостными или другими веб-ресурсами здесь будет меньше подсвеченных дат с сохранённым содержимым. Количество дат зависит от популярности страницы: у обычных пользователей их будет немного, в то время как у известных медиа-личностей – на порядок больше.
Дальнейшие действия такие же: надо выбрать любую из подсвеченных дат и перейти по кликабельной ссылке. В этой же вкладке откроется страница в ВКонтакте с актуальным на тот момент содержимым.
Как выглядели культовые сайты раньше
Для примера посмотрим, как выглядели популярные ресурсы раньше, а именно Яндекс, Google, YouTube, Википедия и VK. Все из них с течением времени претерпели кардинальные изменения в дизайне.
Поисковик Яндекс
Поисковую систему Яндекс официально анонсировали 23 сентября 1997 года. С тех прошло более 20 лет, и сегодня это одна из самых популярных поисковых систем в мире.
В веб-архиве первая сохраненная копия датируется 6 декабря 1998 года.
На тот момент выглядел Яндекс вот так:
Поисковик Google
Поисковая система Google была основа чуть позже – в 1998 году. Сейчас это самая популярная поисковая система в мире.
Первые сохраненные копии появились в веб-архиве в конце 1998 года. Например, 2 декабря Гугл выглядел вот так:
YouTube
Youtube начал свою работу в феврале 2005 года. Первые сохраненные в веб-архиве копии появились в конце апреля 2005 года. На то время сервис имел минималистичный дизайн, и видно, что он являлся не более, чем видеохостингом:
Википедия
Википедия появилась 15 января 2001 года. Сегодня она является наиболее крупным и популярным справочником в интернете и содержит более 40 миллионов статей, которые доступны на 301 языке.
В веб-архиве первая сохраненная копия Википедии датируется 27 июля 2001 года:
ВКонтакте
Популярная в России и других странах социальная сеть ВКонтакте была создана 10 октября 2006 года.
В веб-архиве первая сохраненная копия сайта датируется 8 ноября 2006 года. На нём видно, что сайт изначально был ориентирован на студентов и выпускников.
Можно ли восстановить сайт из вебархива?
При потере данных, восстановить свой сайт можно с помощью сайта https://webarchiveorg.ru/. Для этого нужно:
Услуга является платной, поэтому перед восстановлением рекомендуется ознакомиться с тарифами. Точная стоимость зависит от количества сайтов и его страниц.
Выводы
С помощью веб-архива можно посмотреть, какой дизайн и контент были у сайтов раньше, что может быть необходимо для восстановления данных, анализа конкурентов, поиска интересного контента с исчезнувших ресурсов или просто ради интереса.