HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Веб-архивы Интернета: как искать удалённую информацию и восстанавливать сайты
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Какие существуют веб-архивы Интернета
Я знаю о трёх архивах веб-сайтов (если вы знаете больше, то пишите их в комментариях):
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».

Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:

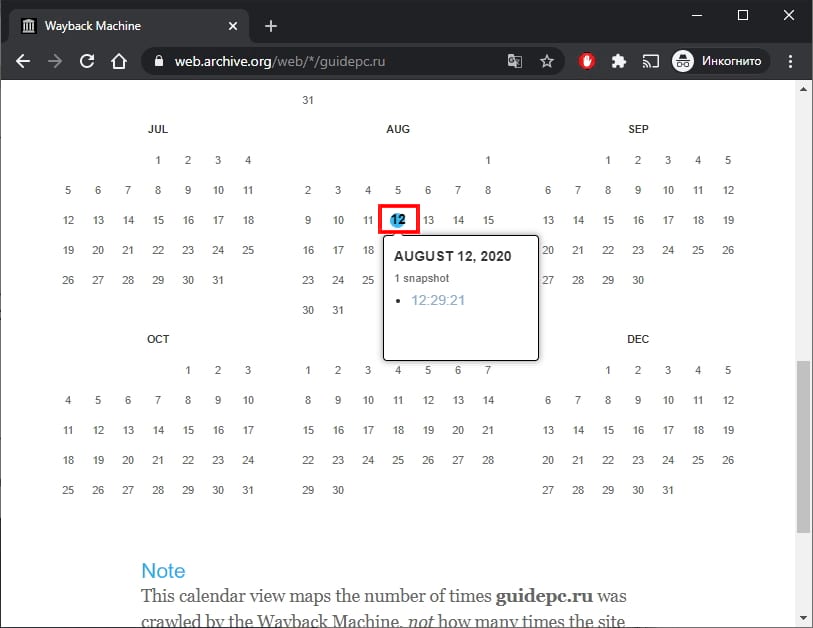
В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
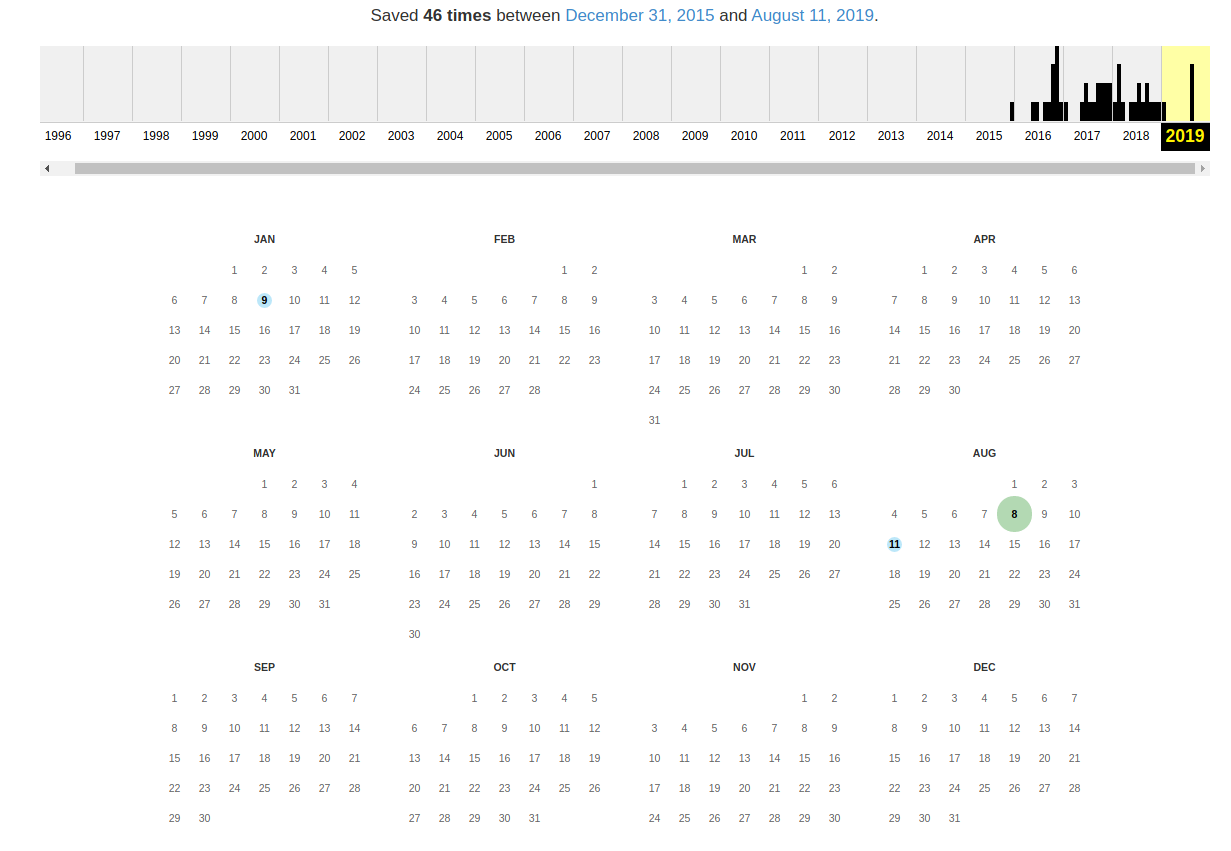
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.

При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время:

Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/
Кроме календаря доступна следующие страницы:
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
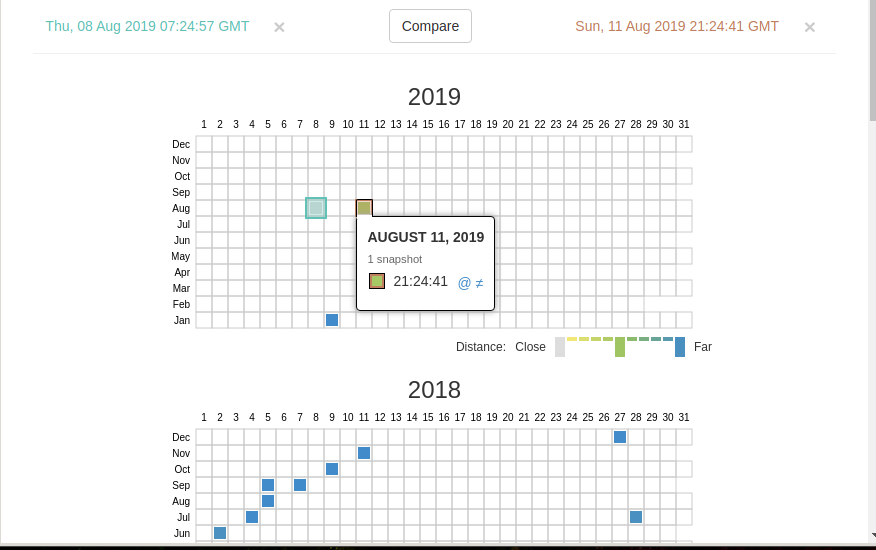
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
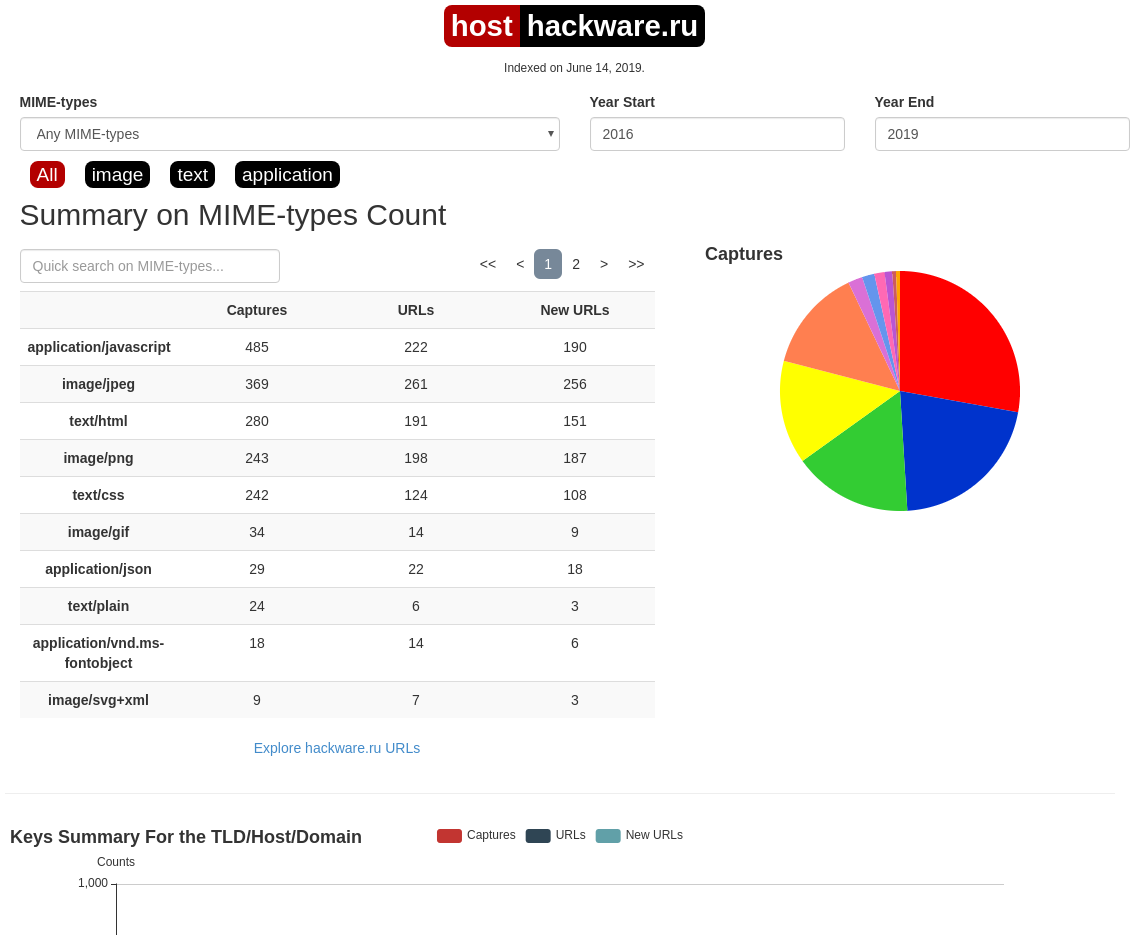
Summary
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Поиск по Интернет архиву
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
Данный сервис сохраняет следующие части страницы:
Не сохраняются следующие части веб-страниц:
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
Дату можно продолжить далее, указав часы, минуты и секунды:
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
Также возможно обратиться ко всем снимкам указанного URL:
Все сохранённые страницы домена:
Все сохранённые страницы всех субдоменов
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
web-arhive.ru
Архив интернет (Web archive) — это бесплатный сервис по поиску архивных копий сайтов. С помощью данного сервиса вы можете проверить внешний вид и содержимое страницы в сети интернет на определённую дату.
На момент написания, этот сервис, вроде бы, нормально не работает («Database Exception (#2002)»). Если у вас есть по нему какие-то новости, то пишите их в комментариях.
Поиск сразу по всем Веб-архивам
Может так случиться, что интересующая страница или файл отсутствует в веб архиве. В этом случае можно попытаться найти интересующую сохранённую страницу в другом Архиве Интернета. Специально для этого я сделал довольно простой сервис, который для введённого адреса даёт ссылки на снимки страницы в рассмотренных трёх архивах.

Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
Например, текстовый вид:
Как полностью скачать сайт из веб-архива
Если вы хотите восстановить удалённый сайт, то вам поможет программа Wayback Machine Downloader.
Программа загрузит последнюю версию каждого файла, присутствующего в Архиве Интернета Wayback Machine, и сохранить его в папку вида ./websites/example.com/. Она также пересоздаст структуру директорий и автоматически создаст страницы index.html чтобы скаченный сайт без каких либо изменений можно было бы поместить на веб-сервер Apache или Nginx.
Об установке программы и дополнительных опциях смотрите на странице https://kali.tools/?p=5211
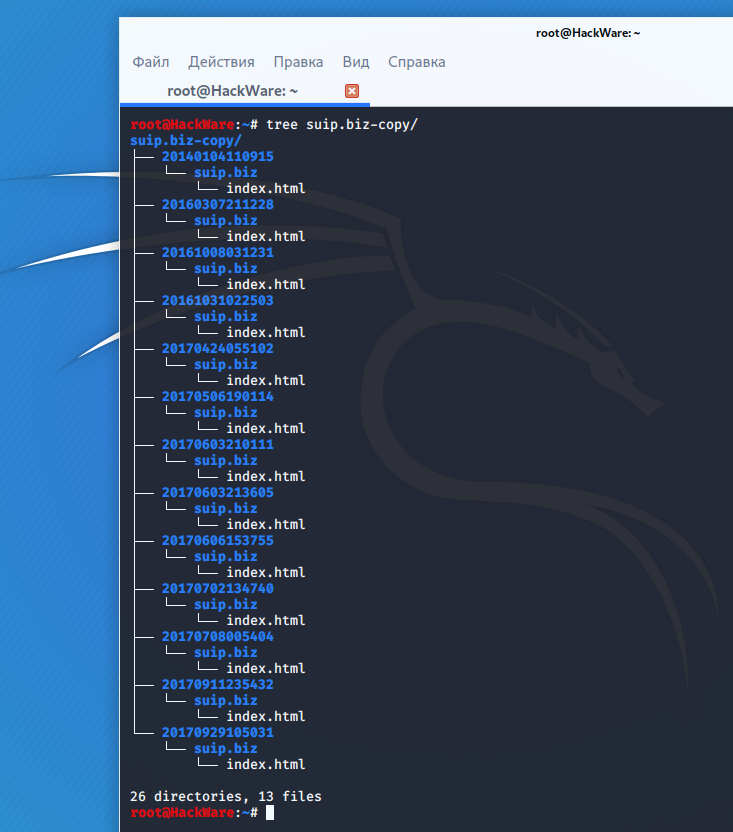
Пример скачивания полной копии сайта suip.biz из веб-архива:
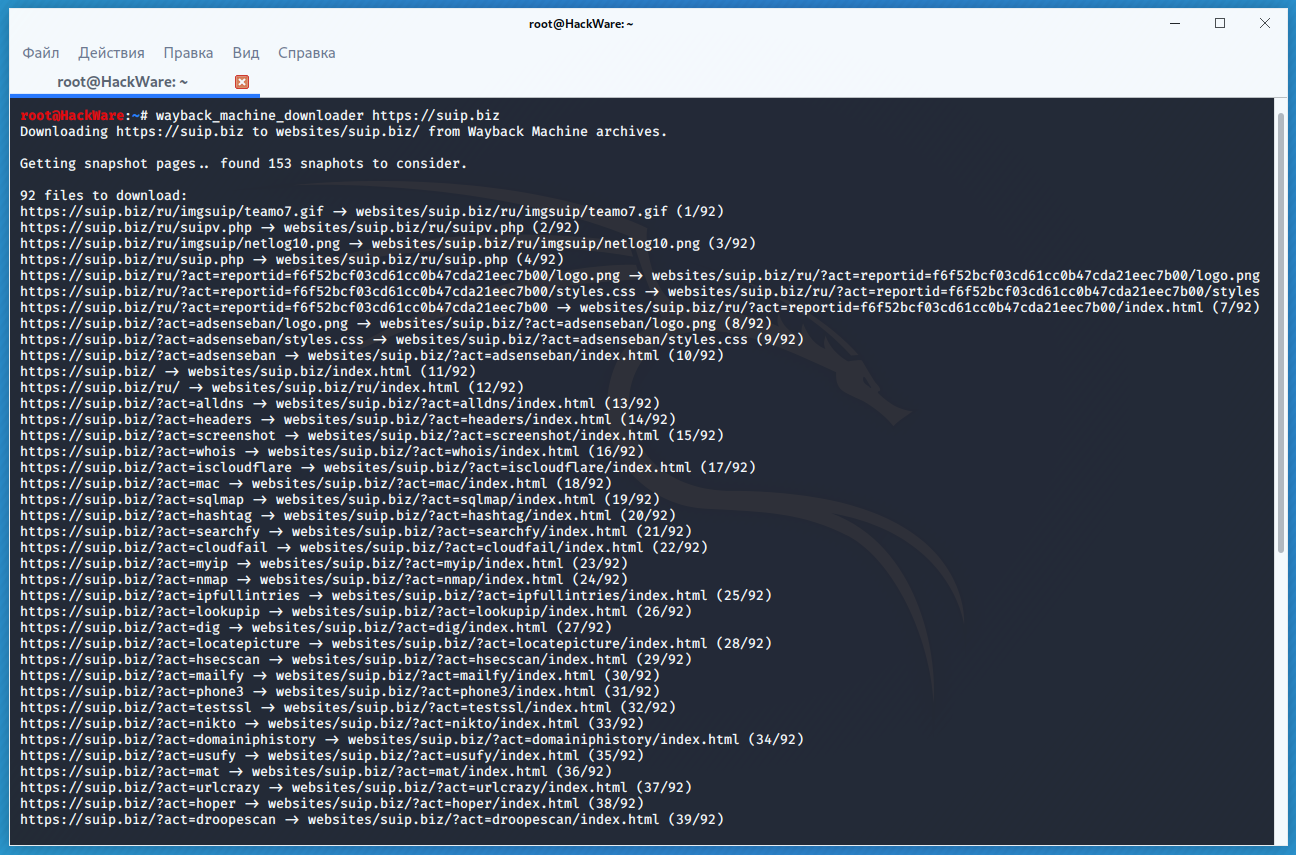
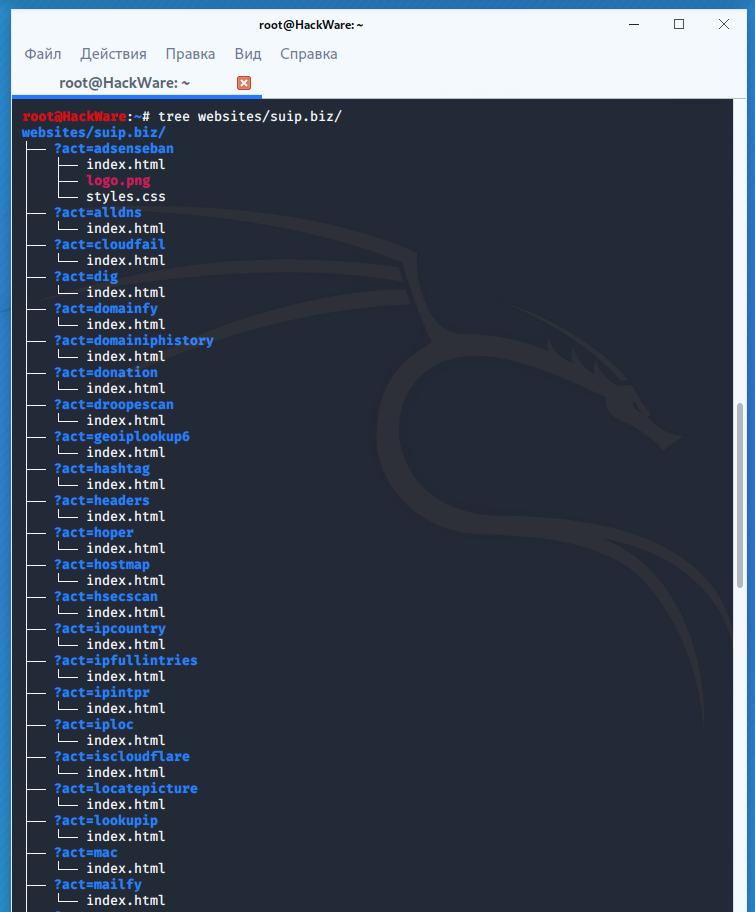
Структура скаченных файлов:
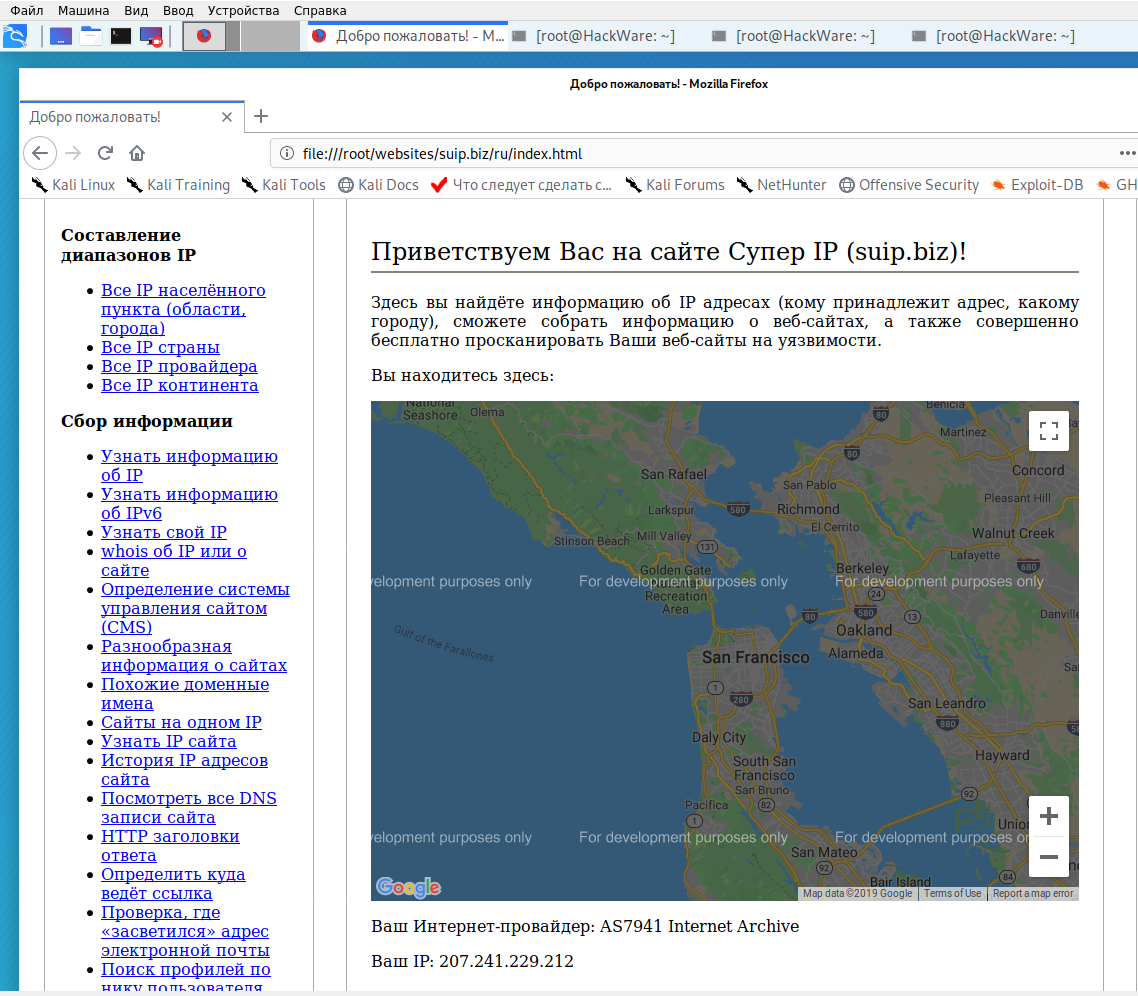
Локальная копия сайта, обратите внимание на провайдера Интернет услуг:
Как скачать все изменения страницы из веб-архива
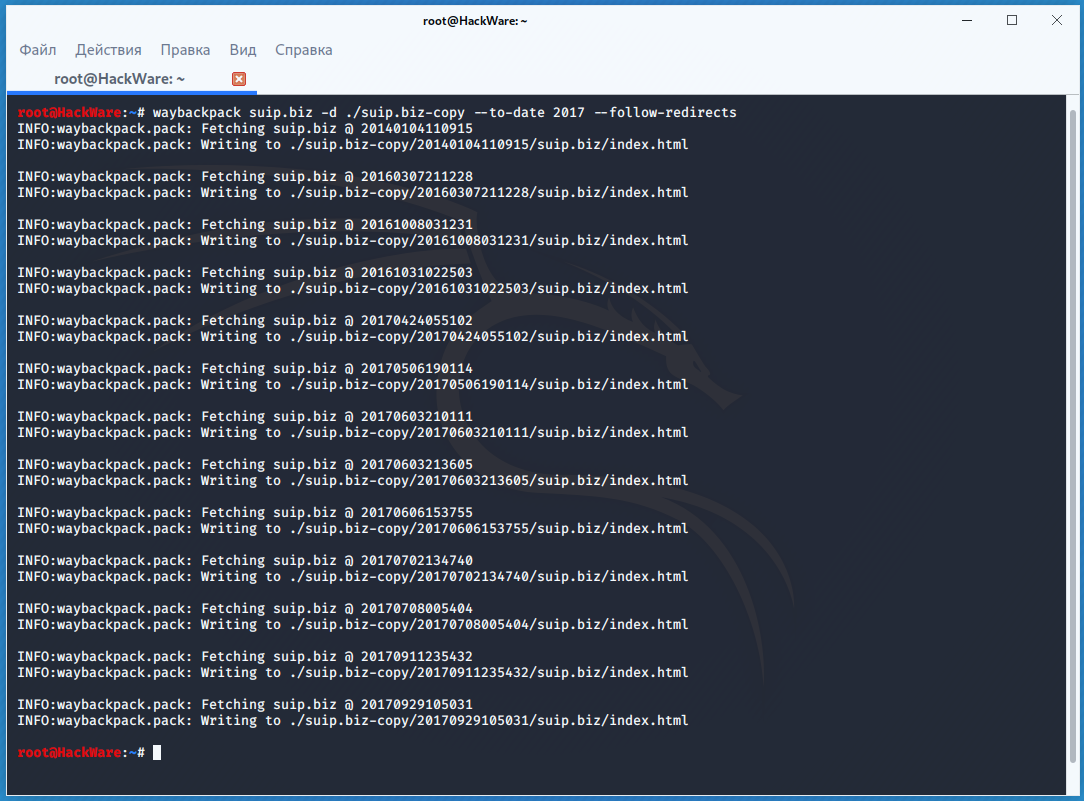
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects):
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
Как узнать все страницы сайта, которые сохранены в веб-архиве
Для получения ссылок, которые хранятся в Архиве Интернета, используйте программу waybackurls.
Эта программа извлекает все URL указанного домена, о которых знает Wayback Machine. Это можно использовать для быстрого составления карты сайта.
Чтобы получить список всех страниц о которых знает Wayback Machine для домена suip.biz:
Заключение
Предыдущие три программы рассмотрены совсем кратко. Дополнительную информацию об их установке и об имеющихся опциях вы сможете найти по ссылкам на карточки этих программ.
Ещё парочка программ, которые работают с архивом интернета:
Как посмотреть старую версию любого сайта и окунуться в ностальгию?

Всем привет! Скажите, хотел бы вы ненадолго вернуться в прошлое, чтобы увидеть себя молодого или маленького со стороны, пообщаться, глянуть, каким вы были? К сожалению, такое совершить пока невозможно. Но зато такое можно проделать с любым веб-ресурсом. Я имею в виду, что можно вернуться на год или два назад, чтобы увидеть как выглядел cайт раньше, какой у него был дизайн, даже какая стояла реклама.
Да. Оказывается есть специальный сервис, который несколько десятков раз в году (10-20-100) делает архивные копии сaйтов, и любой желающий может абсолютно бесплатно посмотреть прошлые версии своих или чужих ресурсов. На самом деле это очень крутая вещь, поэтому я настоятельно рекомендую вам окунуться в прошлое. Поэтому сегодня я вам покажу, как посмотреть старую версию сайта одним очень классным и проверенным способом.
Archive.org
Заходите на сайт Archive.org и впишите в специальное поле адрес вашего сайта.

После этого вы увидите годовую ленту и календарь с отмеченными датами. Перемещаясь по ленте, вы выбираете год, в который вы хотите вернуться, и уже для каждого года активируется свой календарь с отмеченными датами. Именно в эти числа была создана архивная копия, а значит вы можете посмотреть состояние на тот момент. Нажмите на любое число, отмеченное кружком. Я наведу на 15 марта 2016 года и тут же появится вставка со временем. Жмите на нее.

Конечно мой сайт не сильно изменился за последний год, но на 15 марта 2016 года из нет. То есть я не наблюдаю баннеров в правом сайдбаре, не наблюдаю некоторые рубрики, например «Эксперименты» или Заработок![]() и финансы». Также слегка изменено меню, топ комментаторов стал таким, каким был на тот момент, т.е. еще до того, как я исключил себя из этого топа. Правда некоторые моменты отображаются неправильно, например некоторые комментаторы или виджет вконтакте.
и финансы». Также слегка изменено меню, топ комментаторов стал таким, каким был на тот момент, т.е. еще до того, как я исключил себя из этого топа. Правда некоторые моменты отображаются неправильно, например некоторые комментаторы или виджет вконтакте.
Но в целом вещь очень крутая. Можно не просто посмотреть, но и походить по местам былой славы. Действительно, как будто попали в прошлое, а не смотрите фильм про прошлое.
Но у меня дизайн не менялся, поэтому давайте усложним задачу. Возьмем какой-нибудь блог, который существует давно и 100% менял свой дизайн. Я помню, что не так давно моя знакомая по школе блоггеров Настя Скореева поменяла внешний вид своего сайта nyaskory.ru. Сейчас он выглядит так.
Теперь я иду на наш сервис чтобы проверить старую версию ее блога. Для этого я снова вбиваю имя сайта, выбираю дату, когда еще шаблон был старый, например март 2015 года и вуаля! Смотрим результат. Да. Видно, что блог Насти претерпел большие изменения.

Вконтакте
Ради прикола я еще решил проверить социальную сеть вконтакте и посмотреть предыдущие версии этого сайта. Все мы помним, что сеть начала свою деятельность еще в 2006 году и тогда сайт располагался по адресу vkontakte.ru, а не vk.com. Вот его я и решил ввести и посмотреть его в 2006 году. Вы помните такой дизайн? Вот таким он был.

Я зарегистрировался в 2007 году (помню, как даже смотрел дату регистрации в вк) и вот так выглядел тогда этот сайт.

В 2011 году ВК ограничил свободные регистрации в связи с наплывом фейковых страниц. Зарегистрироваться![]() там просто так было нельзя. Нужно было получить приглашение от зарегистрированного пользователя. И вот тогда главная страница смотрелась так.
там просто так было нельзя. Нужно было получить приглашение от зарегистрированного пользователя. И вот тогда главная страница смотрелась так.

А с 2012 года сайт переходит на новый домен vk.com, и со старого происходит автоматическая переадресация. Поэтому с этого момента у вас не получится посмотреть, как выглядел vkontakte.ru например в 2013 году, так как надо вводить уже современный адрес и смотреть там.

В общем как-то так. Здорово, да? Я вот прошелся по старым дизайна вконтакте, и аж ностальгия взяла. Когда я регистрировался, там находилось всего чуть более миллиона человек. А теперь там сотни миллионов.
Ну в общем рекомендую вам тоже пройтись по задворкам прошлого и взглянуть, как всё выглядело раньше. А на сегодня я уже буду закругляться. Надеюсь, что статья была для вас интересной, поэтому не забудьте подписаться на обновления моего блога. С нетерпением буду вас снова ждать у себя в гостях. Удачи вам. Пока-пока!
Как посмотреть на сайт в прошлом: инструмент + способ восстановления

Сервис, который может показать, как выглядели сайты в прошлом, напоминает своеобразную машину времени в интернете. С его помощью можно перенестись на год, два или двадцать лет назад и увидеть, какими ресурсы были тогда. Зачем может понадобиться эта информация и как воспользоваться данным сервисом?
Для чего нужно искать старые версии сайтов
Причины, по которым может быть необходимо посмотреть сайт в прошлом времени, могут быть абсолютно разными. Часто это желание погрузиться в приятную ностальгию. Например, посмотреть, как раньше выглядели популярные площадки и соцсети. Или же посмотреть, как выглядел собственный сайт несколько лет назад. К счастью, существует инструмент, который позволяет это сделать, даже если сам ресурс уже давно не доступен.
Как это возможно? Если сайт существует в интернете хотя бы пару дней, он попадает в веб-архив. Инструмент сохраняет его код, благодаря чему, можно увидеть, как он выглядел даже много лет назад.
Причины, по которым возникает необходимость посмотреть порталы в прошлом времени:
Как узнать прошлое веб-ресурса с помощью archive.org
Чтобы узнать, как выглядел конкретный веб-ресурс ранее, можно воспользоваться сайтом для просмотра страниц в прошлом – a rchive.org. Для этого нужно выполнить следующее:
После этого откроется главная страница в том виде, какой она была в выбранный период.
Учитывайте, что кликабельными в календаре являются только дни, помеченные синим или зеленым цветом. Посмотреть, как выглядел сайт в даты без подсветки, не получится.
Если это страница Вконтакте
Аналогичным образом можно узнать содержимое страницы ВКонтакте. Достаточно указать на нее ссылку в соответствующем поле.
По сравнению с новостными или другими веб-ресурсами здесь будет меньше подсвеченных дат с сохранённым содержимым. Количество дат зависит от популярности страницы: у обычных пользователей их будет немного, в то время как у известных медиа-личностей – на порядок больше.
Дальнейшие действия такие же: надо выбрать любую из подсвеченных дат и перейти по кликабельной ссылке. В этой же вкладке откроется страница в ВКонтакте с актуальным на тот момент содержимым.
Как выглядели культовые сайты раньше
Для примера посмотрим, как выглядели популярные ресурсы раньше, а именно Яндекс, Google, YouTube, Википедия и VK. Все из них с течением времени претерпели кардинальные изменения в дизайне.
Поисковик Яндекс
Поисковую систему Яндекс официально анонсировали 23 сентября 1997 года. С тех прошло более 20 лет, и сегодня это одна из самых популярных поисковых систем в мире.
В веб-архиве первая сохраненная копия датируется 6 декабря 1998 года.
На тот момент выглядел Яндекс вот так:
Поисковик Google
Поисковая система Google была основа чуть позже – в 1998 году. Сейчас это самая популярная поисковая система в мире.
Первые сохраненные копии появились в веб-архиве в конце 1998 года. Например, 2 декабря Гугл выглядел вот так:
YouTube
Youtube начал свою работу в феврале 2005 года. Первые сохраненные в веб-архиве копии появились в конце апреля 2005 года. На то время сервис имел минималистичный дизайн, и видно, что он являлся не более, чем видеохостингом:
Википедия
Википедия появилась 15 января 2001 года. Сегодня она является наиболее крупным и популярным справочником в интернете и содержит более 40 миллионов статей, которые доступны на 301 языке.
В веб-архиве первая сохраненная копия Википедии датируется 27 июля 2001 года:
ВКонтакте
Популярная в России и других странах социальная сеть ВКонтакте была создана 10 октября 2006 года.
В веб-архиве первая сохраненная копия сайта датируется 8 ноября 2006 года. На нём видно, что сайт изначально был ориентирован на студентов и выпускников.
Можно ли восстановить сайт из вебархива?
При потере данных, восстановить свой сайт можно с помощью сайта https://webarchiveorg.ru/. Для этого нужно:
Услуга является платной, поэтому перед восстановлением рекомендуется ознакомиться с тарифами. Точная стоимость зависит от количества сайтов и его страниц.
Выводы
С помощью веб-архива можно посмотреть, какой дизайн и контент были у сайтов раньше, что может быть необходимо для восстановления данных, анализа конкурентов, поиска интересного контента с исчезнувших ресурсов или просто ради интереса.
Как просматривать старые версии сайтов

W ayback Machine — это онлайн-сервис, который сканирует веб-сайты, делая снимки сайтов в определенный момент времени. Используя Wayback Machine, Вы можете увидеть, как выглядел почти любой сайт на протяжении всей его жизни.
Веб-сайты часто меняются, как и законы, регулирующие эти веб-сайты. Будь то потеря данных, новая цензура контента или просто любопытство, Wayback Machine позволяет Вам видеть контент, которого больше нет в сети. Wayback Machine также может использоваться для устранения неполадок.
Примечание: Некоторые сайты могут не отображаться из-за того, что они защищены паролем, заблокированы файлом robots.txt или были недоступны по какой-либо другой причине.
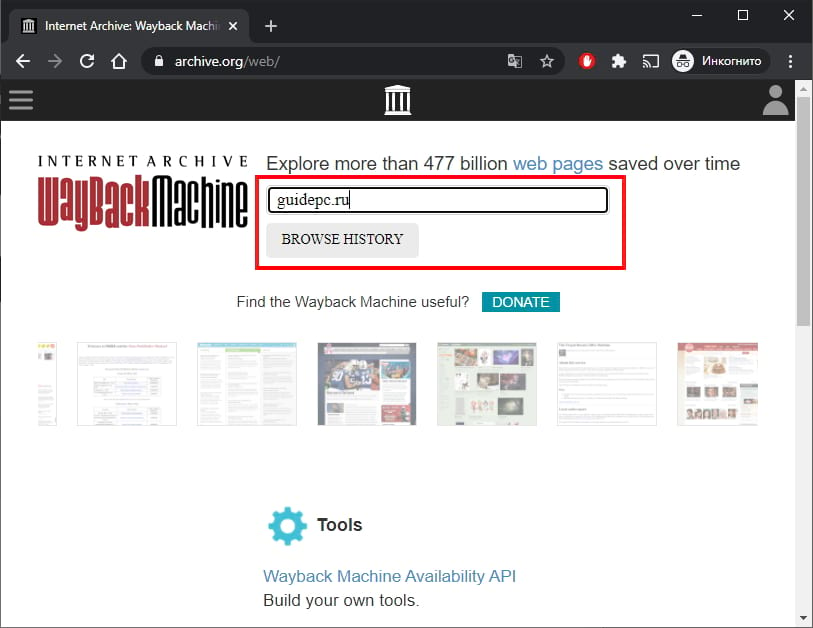
Перейдите на официальный сайт Internet Archive и введите URL-адрес сайта, который Вы хотите просмотреть, в адресной строке Wayback Machine. После ввода нажмите «Browse History».
На следующей странице Вы увидите временную шкалу, содержащую снимки указанного веб-сайта. Также есть примечание о количестве снимков веб-сайта между двумя датами.
Выберите год, который хотите просмотреть.
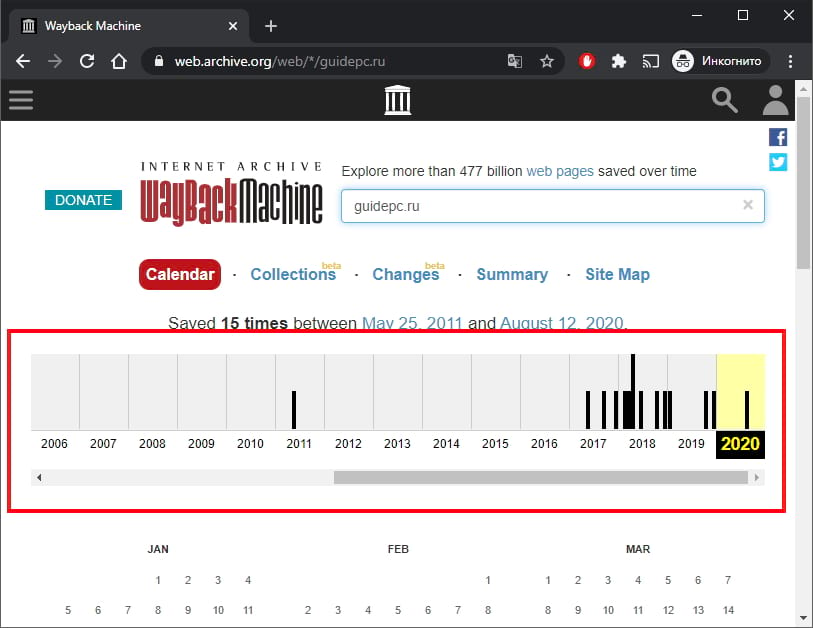
Вы увидите календарь на выбранный год. В определенные даты в течение года Вы заметите, что они выделены определенным цветом. Вот что они означают:
Вы также заметите, что одни круги больше других. Это означает, что на веб-сайте есть несколько снимков для этой конкретной даты. Обратите внимание, что это не отражает количество обновлений сайта.
Выберите дату и время, которые Вы хотите просмотреть, наведя курсор на дату и выбрав снимок во всплывающем меню.
Теперь Вы можете просматривать заархивированную версию веб-сайта.