панды Python как подсчитать количество записей или строк в таблице данных
очевидно, новый для панд. Как я могу просто подсчитать количество записей в фрейме данных.
Я бы подумал, что такая простая вещь, как это, сделает это, и я даже не могу найти ответ в поисках. наверное, потому, что это слишком просто.
приведенный выше код фактически просто печатает весь df
4 ответов
С уважением к вашему вопросу. считая одно поле? Я решил задать вопрос, но надеюсь, это поможет.
скажем, у меня есть следующий DataFrame
вы можете сосчитать один столбец по
оба оценивают до 5.
классная вещь (или одна из многих w.r.т. pandas ) это если у вас есть NA значения, count принимает это во внимание.
так если бы я сделал
результат будет будь
получить количество строк в таблице данных:
(и df.shape[1] получить количество столбцов).
в качестве альтернативы вы можете использовать
(и len(df.columns) для столбцов)
избежать: count() потому что он возвращает количество наблюдений не-NA / null над запрошенной осью
len(df.index) быстрее
df.__len__ это просто вызов len(df.index)
почему вы не должны использовать count()
просто row_num = df.shape[0] # дает количество строк, вот пример:
пример Nan выше пропускает одну часть, что делает его менее общим. Для этого более «обобщенно» используйте df[‘column_name’].value_counts() Это даст вам количество каждого значения в этом столбце.
5 незаменимых функций Pandas для Data Science
Перевод статьи «5 Must-Know Pandas Functions for Data Science».
Каждый проект из области data science начинается с анализа данных. Когда мы говорим об анализе данных, невозможно не упомянуть pandas – библиотеку Python, также известную как Panel Data Analysis.
В этой статье я поделюсь с вами важными функциями pandas, которые помогают осуществлять различные операции над датасетами.
Я буду работать с датасетом от Kaggle для предсказания цен на недвижимость. Скачать его можно здесь.
Сперва изучим наши данные.
Вид датасета следующий.
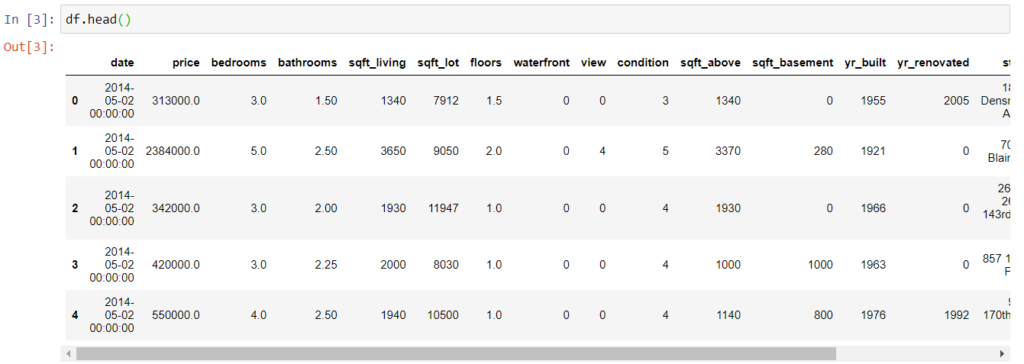
Так как это данные для предсказания цен на недвижимость, здесь учитывается количество комнат, ванные, этажность и другие факторы, способные повлиять на цену дома с различными особенностями.
Применим к этим данным некоторые функции pandas.
1. count()
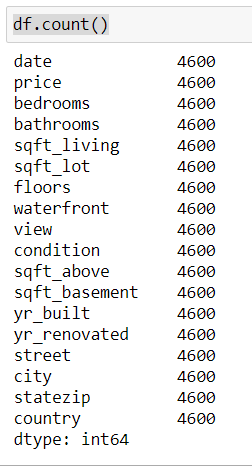
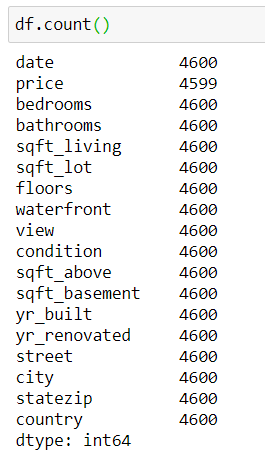
Отличные новости: в нашем датасете нет NaN. Поэтому поместим значение NaN в одну ячейку и посмотрим, что изменится.
Марк Лутц «Изучаем Python»
Скачивайте книгу у нас в телеграм
2. idxmin() и idxmax()
Эти функции возвращают индекс строки, удовлетворяющей определённому условию.
Скажем, нам нужно посмотреть подробную информацию о доме с наименьшей ценой. Существует множество способов сделать это с помощью других методов. Но функции idxmin() и idxmax() наиболее эффективны.
Запустив этот код, я получу данные о жилье с минимальной ценой:
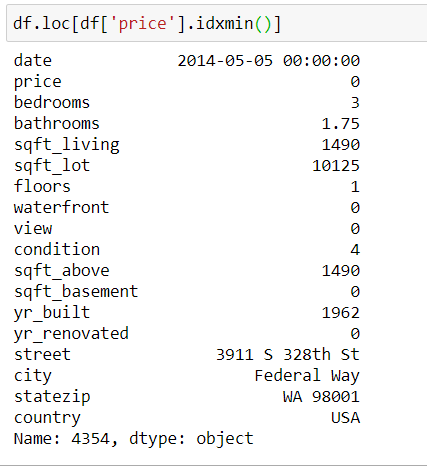
Это будет трёхкомнатная квартира в Федерал-Уэй с ценой 0.
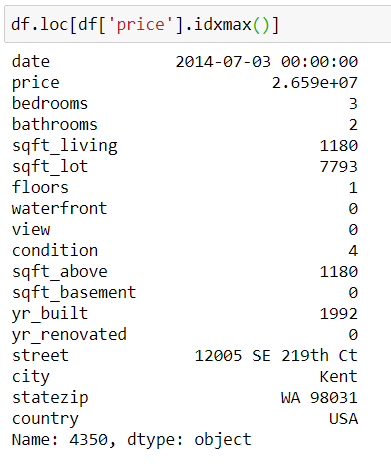
Но что, если домов с минимальной/максимальной ценой окажется несколько? В этом случае функции возвращают первое вхождение. Далее в статье мы разберём и такой случай.
3. cut()
Допустим, у нас есть непрерывная переменная. Но, например, в рамках вашей задачи эту переменную необходимо рассматривать как категориальную.
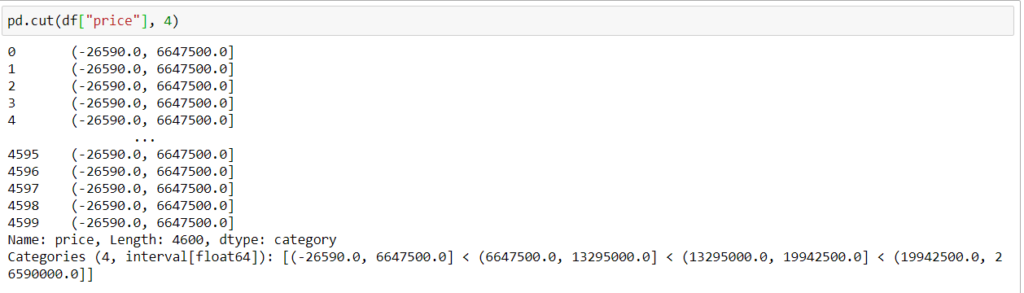
Функция cut() поможет вам привести непрерывную переменную к виду дискретной, разбив весь диапазон значений на интервалы.
В нашем случае я хочу создать набор ценовых данных, поскольку значение цены колеблется от 0 до 26590000. Если я сгруппирую данные, с ними будет проще работать.
Каждому интервалу можно также дать название.
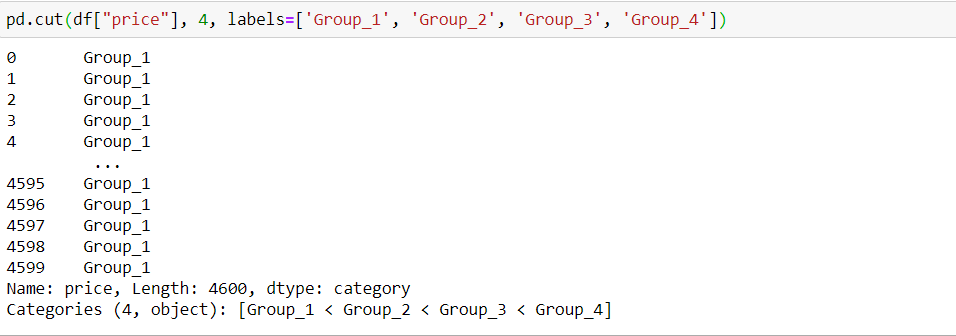
Неплохо! Можно заменить соответствующую колонку ценой в новом формате или же добавить новый столбец.
4. pivot_table()
Если вы работали в excel, вы точно использовали эту функцию.
Допустим, нам нужно найти среднюю цену дома в каждом городе, основываясь на количестве комнат.
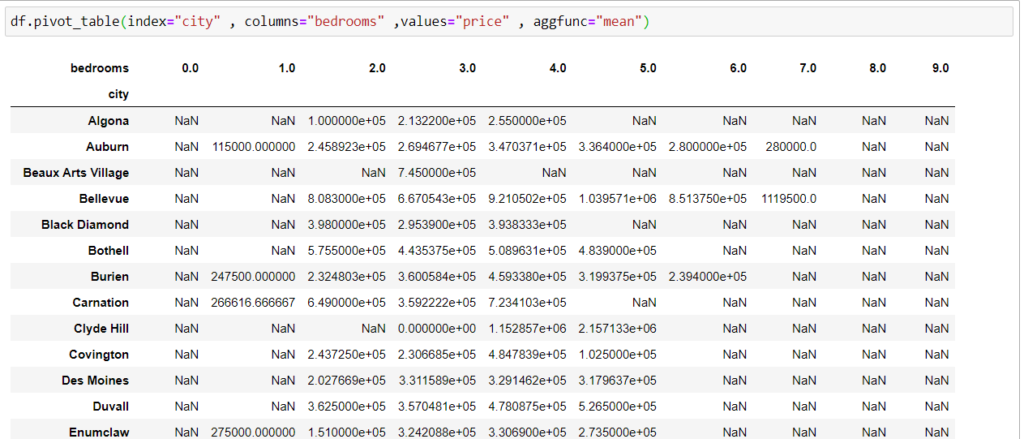
Здесь вы можете заметить NaN, так как не в каждом городе есть двухкомнатные квартиры – также особенность нашего датасета.
5. nsmallest() и nlargest()
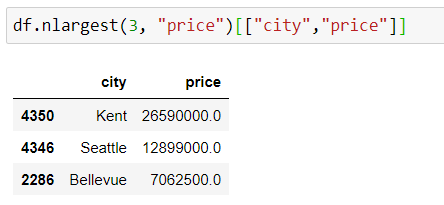

Замечательно! Теперь мы нашли три города, в которых есть дома с нулевой ценой:)
Заключение
Итак, мы познакомились с функциями pandas, которые станут отличными помощниками в решении ваших повседневных задач в области Data Science.
Надеюсь, статья вам понравилась. Спасибо за внимание!
Аналитикам: большая шпаргалка по Pandas
Привет. Я задумывал эту заметку для студентов курса Digital Rockstar, на котором мы учим маркетологов автоматизировать свою работу с помощью программирования, но решил поделиться шпаргалкой по Pandas со всеми. Я ожидаю, что читатель умеет писать код на Python хотя бы на минимальном уровне, знает, что такое списки, словари, циклы и функции.
Что такое Pandas и зачем он нужен
Pandas — это библиотека для работы с данными на Python. Она упрощает жизнь аналитикам: где раньше использовалось 10 строк кода теперь хватит одной.
Например, чтобы прочитать данные из csv, в стандартном Python надо сначала решить, как хранить данные, затем открыть файл, прочитать его построчно, отделить значения друг от друга и очистить данные от специальных символов.
В Pandas всё проще. Во-первых, не нужно думать, как будут храниться данные — они лежат в датафрейме. Во-вторых, достаточно написать одну команду:
Pandas добавляет в Python новые структуры данных — серии и датафреймы. Расскажу, что это такое.
Структуры данных: серии и датафреймы
Серии — одномерные массивы данных. Они очень похожи на списки, но отличаются по поведению — например, операции применяются к списку целиком, а в сериях — поэлементно.
То есть, если список умножить на 2, получите тот же список, повторенный 2 раза.
А если умножить серию, ее длина не изменится, а вот элементы удвоятся.
Обратите внимание на первый столбик вывода. Это индекс, в котором хранятся адреса каждого элемента серии. Каждый элемент потом можно получать, обратившись по нужному адресу.
Еще одно отличие серий от списков — в качестве индексов можно использовать произвольные значения, это делает данные нагляднее. Представим, что мы анализируем помесячные продажи. Используем в качестве индексов названия месяцев, значениями будет выручка:
Теперь можем получать значения каждого месяца:
Так как серии — одномерный массив данных, в них удобно хранить измерения по одному. На практике удобнее группировать данные вместе. Например, если мы анализируем помесячные продажи, полезно видеть не только выручку, но и количество проданных товаров, количество новых клиентов и средний чек. Для этого отлично подходят датафреймы.
Датафреймы — это таблицы. У их есть строки, колонки и ячейки.
Технически, колонки датафреймов — это серии. Поскольку в колонках обычно описывают одни и те же объекты, то все колонки делят один и тот же индекс:
Объясню, как создавать датафреймы и загружать в них данные.
Создаем датафреймы и загружаем данные
Бывает, что мы не знаем, что собой представляют данные, и не можем задать структуру заранее. Тогда удобно создать пустой датафрейм и позже наполнить его данными.
А иногда данные уже есть, но хранятся в переменной из стандартного Python, например, в словаре. Чтобы получить датафрейм, эту переменную передаем в ту же команду:
Случается, что в некоторых записях не хватает данных. Например, посмотрите на список goods_sold — в нём продажи, разбитые по товарным категориям. За первый месяц мы продали машины, компьютеры и программное обеспечение. Во втором машин нет, зато появились велосипеды, а в третьем снова появились машины, но велосипеды исчезли:
Если загрузить данные в датафрейм, Pandas создаст колонки для всех товарных категорий и, где это возможно, заполнит их данными:
Обратите внимание, продажи велосипедов в первом и третьем месяце равны NaN — расшифровывается как Not a Number. Так Pandas помечает отсутствующие значения.
Теперь разберем, как загружать данные из файлов. Чаще всего данные хранятся в экселевских таблицах или csv-, tsv- файлах.
Файлы формата csv и tsv — это текстовые файлы, в которых данные отделены друг от друга запятыми или табуляцией:
После загрузки данных в датафрейм, хорошо бы их исследовать — особенно, если они вам незнакомы.
Исследуем загруженные данные
В датафрейме 5009 строк и 5 колонок.
Теперь видим, что в таблице есть дата заказа, метод доставки, номер клиента и выручка.
Тип object — это текст, float64 — это дробное число типа 3,14.
Ожидаемо, в индексе датафрейма номера заказов: 100762, 100860 и так далее.
Получив первое представление о датафреймах, теперь обсудим, как доставать из него данные.
Получаем данные из датафреймов
Данные из датафреймов можно получать по-разному: указав номера колонок и строк, использовав условные операторы или язык запросов. Расскажу подробнее о каждом способе.
Указываем нужные строки и колонки
Обратите внимание, результат команды — новый датафрейм с таким же индексом.
Можно фильтровать датафреймы по колонкам и столбцам одновременно:
Часто вы не знаете заранее номеров заказов, которые вам нужны. Например, если задача — получить заказы, стоимостью более 1000 рублей. Эту задачу удобно решать с помощью условных операторов.
Если — то. Условные операторы
Задача: нужно узнать, откуда приходят самые большие заказы. Начнем с того, что достанем все покупки стоимостью более 1000 долларов:
Интересно, сколько дорогих заказов было доставлено первым классом? Добавим в фильтр ещё одно условие:
Язык запросов
Разобравшись, как получать куски данных из датафрейма, перейдем к тому, как считать агрегированные метрики: количество заказов, суммарную выручку, средний чек, конверсию.
Считаем производные метрики
Другое дело. Теперь видим сумму выручки по каждому классу доставки. По суммарной выручке неясно, становится лучше или хуже. Добавим разбивку по датам заказа:
Ого, получается, что это так прыгает средний чек. Интересно, а какой был самый удачный день? Чтобы узнать, отсортируем получившийся датафрейм: выведем 10 самых денежных дней по выручке:
Команда разрослась, и её теперь неудобно читать. Чтобы упростить, можно разбить её на несколько строк. В конце каждой строки ставим обратный слеш \ :
В самый удачный день — 18 марта 2014 года — магазин заработал 27 тысяч долларов с помощью стандартного класса доставки. Интересно, откуда были клиенты, сделавшие эти заказы? Чтобы узнать, надо объединить данные о заказах с данными о клиентах.
Объединяем несколько датафреймов
До сих пор мы смотрели только на таблицу с заказами. Но ведь у нас есть еще данные о клиентах интернет-магазина. Загрузим их в переменную customers и посмотрим, что они собой представляют:
Решаем задачу
Закрепим полученный материал, решив задачу. Найдем 5 городов, принесших самую большую выручку в 2016 году.
Для начала отфильтруем заказы из 2016 года:
Город — это атрибут пользователей, а не заказов. Добавим информацию о пользователях:
Cруппируем получившийся датафрейм по городам и посчитаем выручку:
Отсортируем по убыванию продаж и оставим топ-5:
Возьмите данные о заказах и покупателях и посчитайте:
Через некоторое время выложу ответы в Телеграме. Подписывайтесь, чтобы не пропустить ответы и новые статьи.
Кстати, большое спасибо Александру Марфицину за то, что помог отредактировать статью.
10 трюков библиотеки Python Pandas, которые вам нужны
Любите панд? Мы тоже. А еще мы любим эффективный код, поэтому собрали классные трюки, которые облегчат работу с библиотекой Python Pandas.
Некоторые команды уже знакомы? А вы не пробовали использовать их таким образом? 😉

read_csv
Все знают эту команду. Но когда данные, которые вы пытаетесь обработать, большие, попробуйте добавить аргумент nrows = 5, чтобы прочитать только крошечную часть таблицы перед фактической загрузкой всей таблицы. Зачем? Так удастся избежать ошибки с выбором неправильного разделителя, ведь это не всегда запятая.
Или используйте head в Linux, чтобы вывести первые, скажем, 5 строк из любого текстового файла: head –n 5 data.txt.
select_dtypes
Если нужна предварительная обработка данных на языке Python, то эта команда сэкономит вам время. После чтения из таблицы типами данных по умолчанию для каждого столбца будут bool, int64, float64, object, category, timedelta64 или datetime64. Можете сначала проверить распределение с помощью
чтобы узнать все типы данных объекта DataFrame. Далее выполните
df.select_dtypes(include = [‘float64’, ‘int64’])
чтобы выбрать подмножество объекта DataFrame только с числовыми характеристиками.
copy
Это важная команда, если ещё не слышали о ней. Когда выполните следующие операции
обнаружите, что df1 изменён. Это потому, что df2 = df1 не делает копию df1 и не присваивает это значение df2, а устанавливает указатель, который ссылается на df1. Таким образом, любые изменения в df2 приведут к изменениям в df1. Чтобы это исправить, сделайте
map
Это классная команда для простого преобразования данных. Определяете словарь, в котором «ключами» являются старые значения, а «значениями» – новые значения:
применять или не применять функцию apply?

Нужен новый столбец с несколькими другими столбцами в качестве входных данных? Функция apply спешит на помощь!
Здесь определена функцию с двумя входными переменными, и с помощью функции apply применяем к столбцам ‘c1’ и ‘c2’.
Но проблема применения «apply» в том, что иногда это слишком медленно. Например, вам надо рассчитать максимум для ‘c1’ и ‘c2’. Конечно, можно сделать
но это будет намного медленнее, чем
value counts
Команда для проверки распределения значений. Чтобы проверить возможные значения и частоту каждого отдельного значения в столбце ‘c’, выполните:
Некоторые полезные трюки и аргументы этой функции:
Количество пропущенных значений
При построении моделей часто надо исключить строку с большим количеством пропущенных значений или строки со всеми пропущенными значениями. Используйте .isnull() и .sum() для подсчёта количества пропущенных значений в указанных столбцах:
Выбрать строки с конкретными идентификаторами
В SQL используем SELECT * FROM… WHERE ID в («A001», «C022»,…) и получаем записи с конкретными идентификаторами. Если хотите сделать то же с помощью Python библиотеки Pandas, используйте
Процентильные группы в Python Pandas
У нас есть числовой столбец. Хотим классифицировать значения в этом столбце по группам:
Конечно, можно сделать это с помощью pandas.cut, но рассмотрим другой вариант
который быстро запускается, потому что не применяется функция apply.
to_csv
Опять же, это команда, которую все будут использовать. Здесь расскажем о двух трюках. Первый:
Используйте эту команду для вывода первых пяти строк того, что будет в точности записано в файл.
Ещё один трюк касается смешения целых чисел и пропущенных значений. Если столбец содержит как пропущенные значения, так и целые числа, типом данных по-прежнему будет float, а не int. Когда экспортируете таблицу, добавьте float_format = ‘%. 0f’, чтобы округлить числа с плавающей точкой до целых чисел. Используйте этот трюк, когда нужны только целочисленные выходные данные столбцов – так избавитесь от надоедливых ‘.0’.
Это перевод статьи о трюках библиотеки Python Pandas на Towards Data Science.
Подсчет и фильтрация строк в DataFrame Pandas
Чтобы подсчитать количество строк в DataFrame, вы можете использовать свойство shape или метод count().
DataFrame.shape возвращает кортеж, содержащий количество строк в качестве первого элемента и количество столбцов в качестве второго элемента. Индексируя первый элемент, мы можем получить количество строк в DataFrame.
DataFrame.count() со значениями параметров по умолчанию возвращает количество значений по каждому столбцу. Каждый столбец содержит одинаковое количество значений, равное количеству строк. Индексируя первый элемент, мы можем получить количество строк в DataFrame.
Пример 1: подсчет с помощью shape
В этом примере мы будем использовать свойство DataFrame.shape, чтобы получить количество строк.
Пример 2: с помощью count()
В этом примере мы будем использовать метод count() для подсчета количества строк в DataFrame.
В этом руководстве на примерах Python мы узнали, как подсчитать количество строк в заданном DataFrame разными способами с помощью примеров программ.
Фильтрации строк
Чтобы отфильтровать строки в DataFrame, вы можете использовать функцию isin(). Она возвращает логический DataFrame, который при использовании с исходным фильтрует строки, которые подчиняются критериям фильтра.
Вы также можете использовать query() для фильтрации строк, удовлетворяющих заданному логическому выражению.
Пример 1: с помощью isin()
В этом примере мы возьмем DataFrame с двумя столбцами с именами a, b и четырьмя строками. Мы будем фильтровать при условии, что значения столбца a лежат в заданном диапазоне.
Функция isin() возвращает True для строк, значения столбца в которых находятся в диапазоне (3,6). В противном случае функция возвращает false.
df [out] возвращает только те строки, значение которых равно True, что приводит к отфильтрованному выводу.
Пример 2: с помощью query()
В этом примере мы инициализируем DataFrame двумя столбцами a и b, содержащими четыре строки. Мы будем фильтровать те строки, у которых значение столбца b больше 4.
Мы будем использовать query() для фильтрации строк.
В этом руководстве на примерах Python мы узнали, как фильтровать DataFrame на основе условий, применяемых к значениям его столбцов.