В статистическом смысле термин «неопределенность» связан с измерением, где он относится к ожидаемому изменению значения, которое получается из среднего значения нескольких показаний, из истинного среднего значения набора данных или показаний. Другими словами, неопределенность можно рассматривать как стандартное отклонение среднего значения набора данных. Формула для неопределенности может быть получена путем суммирования квадратов отклонения каждой переменной от среднего значения, затем деления результата на произведение числа чтений и количества чтений минус один, а затем вычисление квадратного корня из результата, Математически формула неопределенности представлена в виде
Примеры формулы неопределенности (с шаблоном Excel)
Давайте рассмотрим пример, чтобы лучше понять расчет неопределенности.
Давайте возьмем пример забега на 100 м в школьном соревновании.Гонка была рассчитана с использованием пяти разных секундомеров, и каждый секундомер записывал немного разные сроки.Показания составляют 15, 33 секунды, 15, 21 секунды, 15, 31 секунды, 15, 25 секунды и 15, 35 секунды.Рассчитайте неопределенность времени на основе предоставленной информации и представьте время с уровнем достоверности 68%.
Решение:
Среднее значение рассчитывается как:
Теперь нам нужно рассчитать отклонения каждого чтения
Аналогично рассчитайте все показания
Рассчитайте квадрат отклонений каждого показания
Неопределенность рассчитывается по формуле, приведенной ниже
Время при уровне достоверности 68% = μ ± 1 * u
Следовательно, неопределенность набора данных составляет 0, 03 секунды, а время может быть представлено как (15, 29 ± 0, 03) секунды при уровне достоверности 68%.
Решение:
Среднее значение рассчитывается как:
Теперь нам нужно рассчитать отклонения каждого чтения
Аналогично рассчитайте все показания
Рассчитайте квадрат отклонений каждого показания
Неопределенность рассчитывается по формуле, приведенной ниже
Измерение при уровне достоверности 95% = μ ± 2 * u
Измерение при уровне достоверности 99% = μ ± 3 * u
Следовательно, погрешность показаний составляет 0, 08 акра, и измерение можно представить как (50, 42 ± 0, 16) акра и (50, 42 ± 0, 24) акра при уровне достоверности 95% и 99%.
объяснение
Формула для неопределенности может быть получена с помощью следующих шагов:
Шаг 1: Во-первых, выберите эксперимент и переменную, которую нужно измерить.
Шаг 3: Затем определите количество чтений в наборе данных, которое обозначено как n.
Шаг 4: Затем рассчитайте среднее значение показаний, суммируя все показания в наборе данных, а затем разделите результат на число показаний, доступных в наборе данных. Среднее обозначается через µ.
μ = ∑ x i / n
Шаг 9: Наконец, формула для неопределенности может быть получена путем вычисления квадратного корня из вышеуказанного результата, как показано ниже.
Актуальность и использование формулы неопределенности
С точки зрения статистических экспериментов концепция неопределенности очень важна, поскольку помогает статистику определять изменчивость показаний и оценивать измерения с определенным уровнем достоверности. Тем не менее, точность неопределенности так же хороша, как и показания, полученные измерителем. Неопределенность помогает в оценке наилучшего приближения для измерения.
Рекомендуемые статьи
Как посчитать энтропию в excel
Добрый день, вопрос довольно специфичный, не уверен что могу даже верно сформулировать его для поиска на вашем необъятном форуме.
Есть база данных пациентов с исходной информацией, нужно емкой формулой (в одной ячейке) расчитать показатель для каждого.
Целевая формула в текстовом виде выглядит следующим образом
Проблема возникла при расчете H моя текущая формула выглядит следующим образом
источник проблемы LOG((A2:E2)/100;2)) если исходные данные содержат 0, расчет выдает ошибку ибо нелья посчитать логарифм нуля. как можно исключить из диапазона ячейки содержащие ноль? В конкретной подвыборке такой случай всего один, но в дальнейшем нули будут возникать повсеместно.
Добрый день, вопрос довольно специфичный, не уверен что могу даже верно сформулировать его для поиска на вашем необъятном форуме.
Есть база данных пациентов с исходной информацией, нужно емкой формулой (в одной ячейке) расчитать показатель для каждого.
Целевая формула в текстовом виде выглядит следующим образом
Проблема возникла при расчете H моя текущая формула выглядит следующим образом
источник проблемы LOG((A2:E2)/100;2)) если исходные данные содержат 0, расчет выдает ошибку ибо нелья посчитать логарифм нуля. как можно исключить из диапазона ячейки содержащие ноль? В конкретной подвыборке такой случай всего один, но в дальнейшем нули будут возникать повсеместно. Misanthrope
Сообщение Добрый день, вопрос довольно специфичный, не уверен что могу даже верно сформулировать его для поиска на вашем необъятном форуме.
Есть база данных пациентов с исходной информацией, нужно емкой формулой (в одной ячейке) расчитать показатель для каждого.
Целевая формула в текстовом виде выглядит следующим образом
Проблема возникла при расчете H моя текущая формула выглядит следующим образом
Pelena
Дата: Пятница, 21.11.2014, 12:54 | Сообщение № 3
buchlotnik, спасибо за ответ, впервые столкнулся с формулой ЕОШ. Можете в кратце пояснить её работу в вашем олгаритме?
Если я все верно понимаю: 1) Функция ЕОШ отсматирвает ряд где расчитана формула логарифма для каждой ячейки 2) находит те ячейки где расчет произошел с ошибкой 3) таким образом выполняется уловие «истина» и ячейке с ошибкой присваивается значение ноль?
и опять же это работает только в массиве
Pelena, С разных сторон писал точно такую же поправку к формуле как Ваша, но она не работала до тех пор пока не ввел её как массив. в чем секрет? почему она не работает если не массив?
Спасибо, буду перечитывать статьи про массивы, похоже именно там скрывалась истина)
buchlotnik, спасибо за ответ, впервые столкнулся с формулой ЕОШ. Можете в кратце пояснить её работу в вашем олгаритме?
Если я все верно понимаю: 1) Функция ЕОШ отсматирвает ряд где расчитана формула логарифма для каждой ячейки 2) находит те ячейки где расчет произошел с ошибкой 3) таким образом выполняется уловие «истина» и ячейке с ошибкой присваивается значение ноль?
и опять же это работает только в массиве
Pelena, С разных сторон писал точно такую же поправку к формуле как Ваша, но она не работала до тех пор пока не ввел её как массив. в чем секрет? почему она не работает если не массив?
Спасибо, буду перечитывать статьи про массивы, похоже именно там скрывалась истина) Misanthrope
Сообщение buchlotnik, спасибо за ответ, впервые столкнулся с формулой ЕОШ. Можете в кратце пояснить её работу в вашем олгаритме?
Если я все верно понимаю: 1) Функция ЕОШ отсматирвает ряд где расчитана формула логарифма для каждой ячейки 2) находит те ячейки где расчет произошел с ошибкой 3) таким образом выполняется уловие «истина» и ячейке с ошибкой присваивается значение ноль?
и опять же это работает только в массиве
Pelena, С разных сторон писал точно такую же поправку к формуле как Ваша, но она не работала до тех пор пока не ввел её как массив. в чем секрет? почему она не работает если не массив?
Порядок выполнения лабораторной работы. 1.Создать таблицу (50 рабочих строк) в Excel аналогичную рис.1. Таблица расчета энтропии источника № п/п
1.Создать таблицу (50 рабочих строк) в Excel аналогичную рис.1.
Таблица расчета энтропии источника
№ п/п
Символ
Код символа
Число вхождений символа в текст
Вероятность вхождения символа (рi)
Ii
…
…
Я
Всего символов в тексте (K)
Полная вероятность(Р)
(должна получиться «1»)
Энтропия источника (Iср)
2. Заполнить столбец Символ следующими значениями:
Ø 33 буквы русского алфавита;
3. Заполнить столбец Код символа используя функцию «КОДСИМВ(…)», находящуюся в категории «Текстовые».
4. Открыв каскадом текст по варианту и таблицу и используя в Word «Правка Þ Заменить» заполнить столбец Число вхождений символа в текст. (Предполагается, что других символов в тексте НЕТ.) Сосчитать общее число символов.
5. По формулам заполнить столбцы «рi» и «Ii ». Сосчитать полную вероятность и энтропию источника.
6. Создать таблицу, аналогичную рис.2 и заполнить ее по формулам.
Неопределенность
Разрядность кода
Абсолютная избыточность
Относительная избыточность
Стандартная кодовая таблица ASCII
Мера Хартли
7. Выписать применяемые формулы с расшифровкой использыемых символов.
Содержание отчёта
1. Название и цель работы.
2. Заполненная таблица №1 для 50-ти символов.
3. Заполненная таблица №2.
4. Использованные формулы с определением переменных.
5. Выводы по работе соответственно цели лабораторной работы. Сравнительный анализ таблицы на рис.2.
Приложение к лабораторной работе «Определение количества информации, содержащегося в сообщении»
Основные положения
1. Общие сведения об информации.
Понятие «информация» происходит от латинского слова informatio— разъяснение, осведомление, изложение и обозначает одно из основных свойств материи. В рамках науки — информация — первичное, неопределенное понятие. Оно предполагает наличие материального носителя информации, источника информации, передатчика и т.п. Конкретное толкование элементов, связанных с понятием информации, связано с методологией конкретной области науки.
Можно выделить некоторые свойства информации, определяющие смысл этого понятия:
Ø Информация переносит знания об окружающем мире, которых в рассматриваемой точке не было до получения информации;
Ø Информация не материальна — она проявляется в форме материальных носителей — дискретных знаков, сигналов или функций времени;
Ø Информация может быть заключена в знаках или в их взаимном расположении;
Ø Знаки и сигналы несут информацию только для получателя, который может их распознать.
Термин «информация» имеет много определений. В широком смысле —
Информация— отражение реального мира.
Существует определение термина в узком смысле, применимого к предметной области автоматизированной обработки информации.
Информация — любые сведения, являющиеся объектом хранения, передачи и преобразования.
В процессе передачи информации важно определить следующие понятия:
Сообщение — информация, представленная в определенной форме и предназначенная для передачи. Сообщение представляется последовательностью знаков и сигналов.
Сигнал — процесс, несущий информацию. Таким образом, сигнал служит для переноса информации.
Знак — реально различимые получателем материальные объекты: буквы, цифры, предметы. Знаки служат для хранения информации.
Данные — информация, представленная в формализованном виде и предназначенная для обработки техническими средствами.
Таким образом, любой информационный процесс, может быть представлен как процесс передачи информации от объекта, являющегося источником информации, к получателю. Для обеспечения передачи информации необходим канал связи, некоторая физическая среда, через которую информация, представленная в виде сигналов, передается получателю.
Множество всех знаков и сигналов, использующееся для формирования сообщения, называется алфавит.
Размер (глубина) алфавита A определяется количеством символов, составляющих алфавит. Если считать, что сообщение передается одним знаком алфавита размером A, всего может быть передано N=Асообщений.
Таким образом, с помощью слов можно представить информацию о любом из N сообщений.
Выражение (1) позволяет определить размер слова из алфавита А, с помощью которого можно представить N сообщений
Мы можем сопоставить тому или иному сообщению комбинацию знаков, тогда при приеме сообщения, зная правила сопоставления, можно распознать сообщение.
Информация всегда представляется в виде сообщения, которое передается некоторой физической средой. Носителем сообщения выступает сигнал, выражающийся в изменении энергии среды передачи информации — канала связи. Для того, чтобы передать информацию по каналу связи необходимо сопоставить исходному сообщению некоторое правило изменения сигнала. Такое правило сопоставления называют кодированием.
Кодирование — представление сообщений в форме, удобной для передачи информации по каналам связи.
Естественно, можно говорить о кодировании на различных этапах передачи информации. Так, например, можно говорить о кодере источника, кодере канала связи и т.д. Принятое сообщение подвергается декодированию.
Декодирование — операция восстановления принятого сообщения. В системе связи необходимо ввести устройства кодирования и декодирования. Очевидно, что правила кодирования и декодирования в системе должны быть согласованы.
Важный вопрос теории передачи и преобразования информации — установление меры, количества и качества информации.
2. Математические меры информации.
Информационные меры, как правило, рассматриваются в двух аспектах синтаксическом и семантическом.
В синтаксическом аспекте сообщения рассматриваются как символы, абстрагированные от содержания и какой-либо ценности. Предметом анализа и оценивания являются частота появления символов, связи между ними, порядок следования, правила построения сообщений. В таком рассмотрении наиболее широко используют структурные и вероятностные(статистические) меры.
Структурные меры оценивают строение массивов информации и их измерение простым подсчетом информационных элементов или комбинаторным методом. Структурный подход применяется для оценки возможностей информационных систем вне зависимости от условий их применения.
При статистическом подходе используется понятие энтропии как меры неопределенности, учитывающей вероятность появления и информативность того или иного сообщения. Статистический подход учитывает конкретные условия применения информационных систем.
Семантический подход позволяет выделить полезность или ценность информационного сообщения (в настоящем пособии не рассматривается).
При синтаксическом анализе информация определяется как мера уменьшения неопределенности знаний о каком-либо предмете в познавательном процессе. Если H1 — исходная (априорная) неопределенность до передачи сообщения, а H2 — остаточная (апостериорная) неопределенность, характеризующая состояние знания после получения сообщения, то содержащаяся в этом сообщении информация определяется их разностью
Известно достаточно большое количество различных мер, различающихся подходом к определению неопределенности в (3). Далее рассматриваются только две из них — структурная аддитивная мера Хартли и вероятностная мера, называемая энтропия, предложенная К.Шенноном.
Аддитивная мера (мера Хартли) использует понятия глубины А и длины n числа.
Глубина числа — количество символов (элементов), принятых для представления информации. В каждый момент времени реализуется только один какой-либо символ.
Длина n числа — количество позиций, необходимых и достаточных для представления чисел заданной величины.
Эти понятия могут быть распространены и на вариант нечислового сообщения. В этом случае глубина числа тождественна размеру алфавита, а длина числа — разрядности слова при передаче символьного сообщения.
Если сообщение — число, понятие глубины числа будет трансформировано в понятие основания системы счисления. При заданных глубине и длине числа количество чисел, которое можно представить, N = А n. Очевидно, что N однозначно характеризует степень исходной неопределенности. Исходная неопределенность по Хартли определяется
Неопределенность после получения сообщения, остаточная неопределенность,
где N* — число возможных значений принятого слова после получения сообщения.
Основание логарифма в (5) определяет только единицы измерения неопределенности. При a=2 это двоичная единица информации, называемая бит. При a = 10 десятичная (дит), при a =e натуральная (нат). Далее мы будем всегда пользоваться двоичной единицей.
N* равно единице, если после получения информации нет неопределенности, т.е. получатель гарантировано получил то сообщение, которое было передано. Если получателю приходится после приема информации выбирать сообщения из некоторого множества, а это происходит тогда, когда в канале связи за счет влияния помех возникают искажения переданного сигнала, то характеризует число возможных сообщений при выборе. Таким образом, если передается символ некоторого алфавита, N* определяет возможную неоднозначность приема символа за счет искажений в канале связи. В случае измерительного опыта, число N*— характеризует число возможных значений величины после измерения и определяет погрешность измерения.
Очевидно, что должно быть N*
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Таблица формул Excel для теории вероятностей и статистики
Комбинаторика и вероятность
Ниже вы найдете основные формулы Excel, которые могут применяться при решении вероятностных задач и задач по комбинаторике.
Выдает случайное число в интервале от 0 до 1 (равномерно распределенное).
Выдает случайное число в заданном интервале.
Вычисляет отдельное значение биномиального распределения.
Определяет гипергеометрическое распределение.
Вычисляет значение нормальной функции распределения.
Выдает обратное значение стандартного нормального распределения.
Определяет вероятность того, что значение из диапазона находится внутри заданных пределов.
Математическая статистика
При решении задач по математической статистике можно использовать те формулы, что перечислены выше, а также следующие (сгруппированы для удобства: обработка выборки, разные распределения, остальные формулы):
Обработка выборки: формулы Excel
Вычисляет среднее абсолютных значений отклонений точек данных от среднего.
Вычисляет среднее арифметическое аргументов.
Вычисляет среднее геометрическое.
Вычисляет среднее гармоническое.
Определяет эксцесс множества данных.
Находит медиану заданных чисел.
Определяет значение моды множества данных.
Определяет квартиль множества данных.
Определяет асимметрию распределения.
Оценивает стандартное отклонение по выборке.
Оценивает дисперсию по выборке.
Законы распределений: формулы Excel
Определяет интегральную функцию плотности бета-вероятности.
Определяет обратную функцию к интегральной функции плотности бета-вероятности.
Вычисляет обратное значение односторонней вероятности распределения хи-квадрат.
Находит экспоненциальное распределение.
Находит F-распределение вероятности.
Определяет обратное значение для F-распределения вероятности.
Находит преобразование Фишера.
Находит обратное преобразование Фишера.
Находит обратное гамма-распределение.
Выдает распределение Пуассона.
Выдает t-распределение Стьюдента.
Выдает обратное t-распределение Стьюдента.
Выдает распределение Вейбулла.
Другое (корреляция, регрессия и т.п.)
Определяет доверительный интервал для среднего значения по генеральной совокупности.
Находит коэффициент корреляции между двумя множествами данных.
Подсчитывает количество чисел в списке аргументов.
Подсчитывает количество непустых ячеек, удовлетворяющих заданному условию внутри диапазона.
Определяет ковариацию, то есть среднее произведений отклонений для каждой пары точек.
Вычисляет значение линейного тренда.
Находит параметры линейного тренда.
Определяет коэффициент корреляции Пирсона.
Справочный файл по формулам Excel
Нужна шпаргалка по функциям Excel под рукой? Скачивайте файл: Математические и статистические формулы Excel
Полезные ссылки
А если у вас есть задачи, которые надо срочно сделать, а времени нет? Можете поискать готовые решения в решебнике:
Расчет коэффициента детерминации в Microsoft Excel
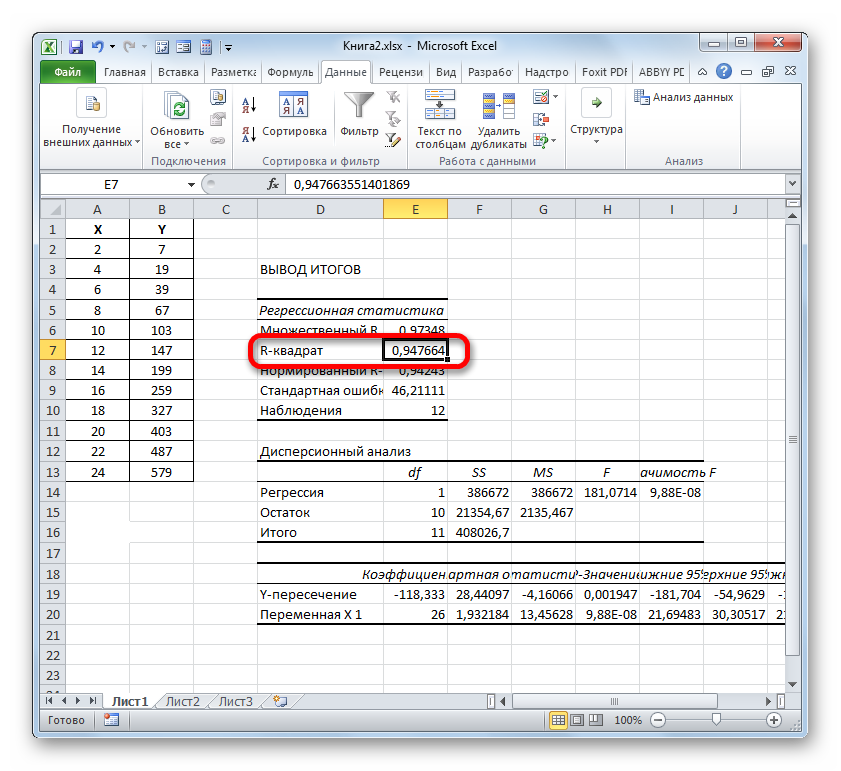
Одним из показателей, описывающих качество построенной модели в статистике, является коэффициент детерминации (R^2), который ещё называют величиной достоверности аппроксимации. С его помощью можно определить уровень точности прогноза. Давайте узнаем, как можно произвести расчет данного показателя с помощью различных инструментов программы Excel.
Вычисление коэффициента детерминации
В зависимости от уровня коэффициента детерминации, принято разделять модели на три группы:
В последнем случае качество модели говорит о невозможности её использования для прогноза.
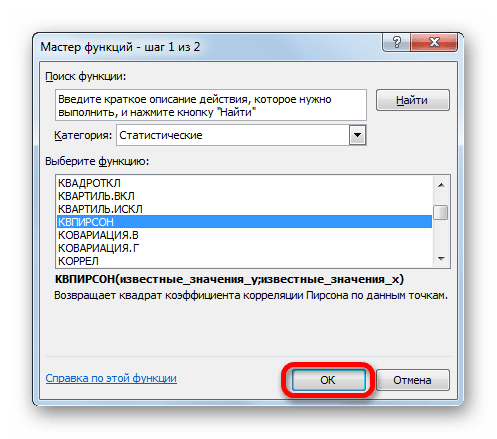
Выбор способа вычисления указанного значения в Excel зависит от того, является ли регрессия линейной или нет. В первом случае можно использовать функцию КВПИРСОН, а во втором придется воспользоваться специальным инструментом из пакета анализа.
Способ 1: вычисление коэффициента детерминации при линейной функции
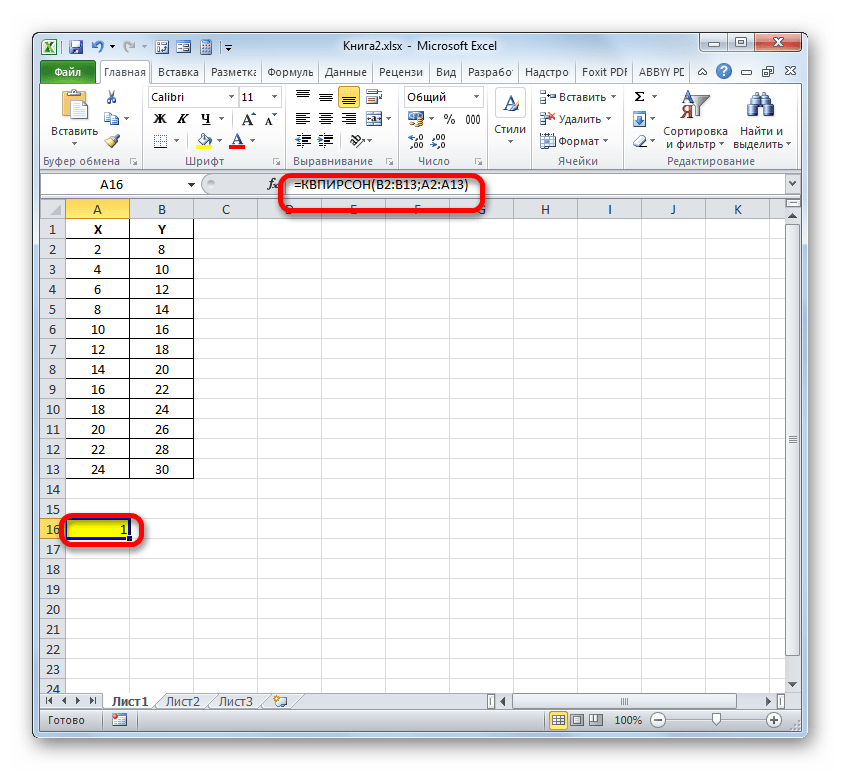
Прежде всего, выясним, как найти коэффициент детерминации при линейной функции. В этом случае данный показатель будет равняться квадрату коэффициента корреляции. Произведем его расчет с помощью встроенной функции Excel на примере конкретной таблицы, которая приведена ниже.
Синтаксис этого оператора такой:
Таким образом, функция имеет два оператора, один из которых представляет собой перечень значений функции, а второй – аргументов. Операторы могут быть представлены, как непосредственно в виде значений, перечисленных через точку с запятой (;), так и в виде ссылок на диапазоны, где они расположены. Именно последний вариант и будет использован нами в данном примере.
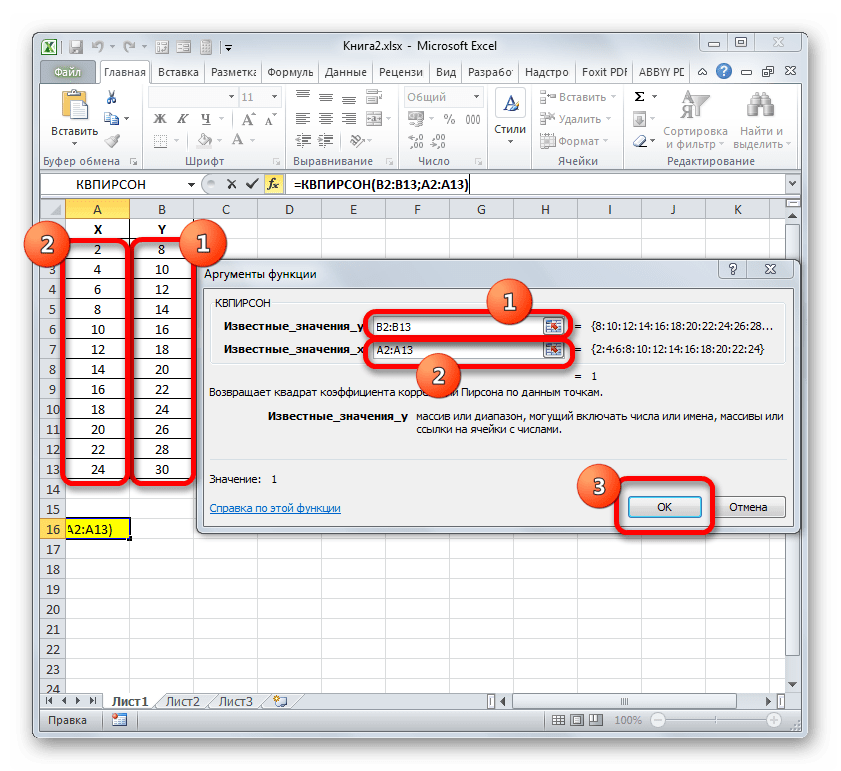
Устанавливаем курсор в поле «Известные значения y». Выполняем зажим левой кнопки мышки и производим выделение содержимого столбца «Y» таблицы. Как видим, адрес указанного массива данных тут же отображается в окне.
Аналогичным образом заполняем поле «Известные значения x». Ставим курсор в данное поле, но на этот раз выделяем значения столбца «X».
После того, как все данные были отображены в окне аргументов КВПИРСОН, клацаем по кнопке «OK», расположенной в самом его низу.
Способ 2: вычисление коэффициента детерминации в нелинейных функциях
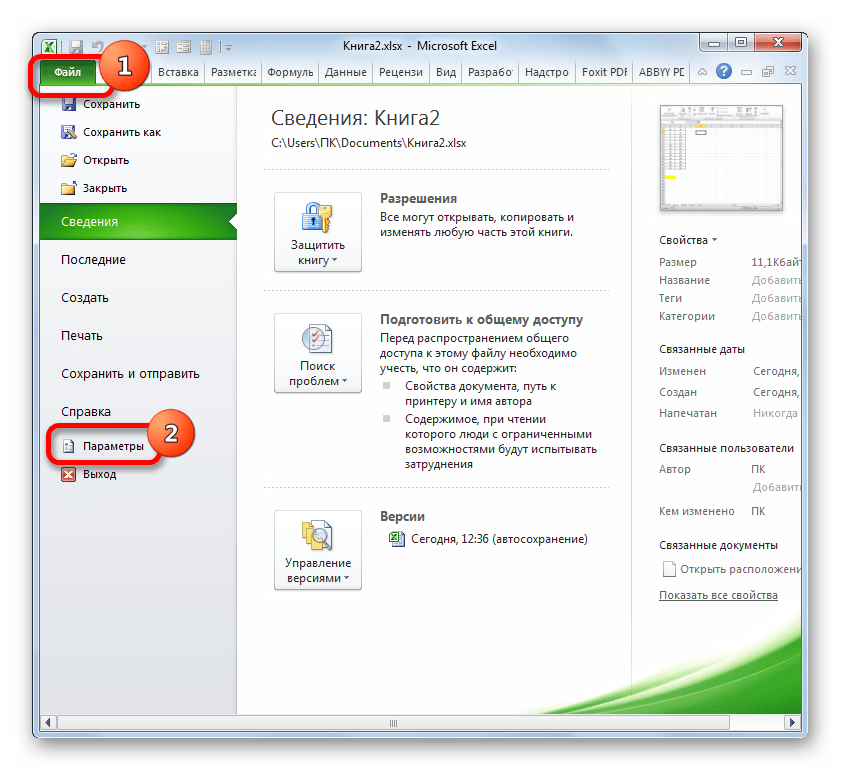
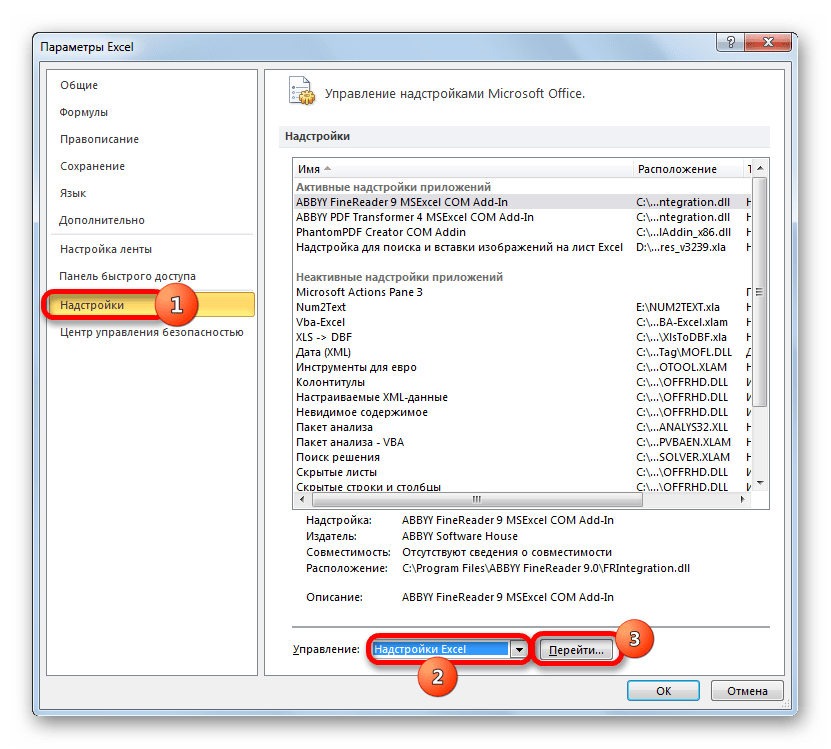
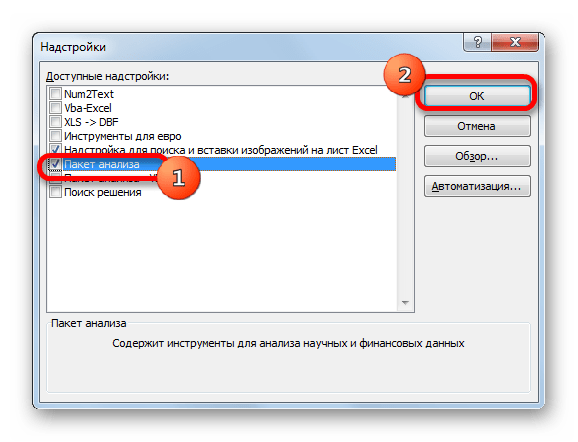
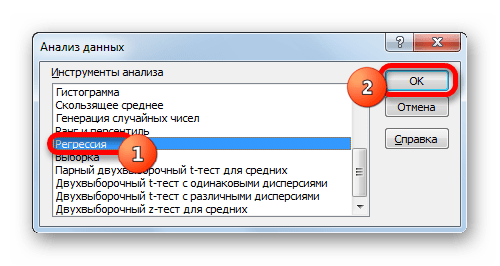
Но указанный выше вариант расчета искомого значения можно применять только к линейным функциям. Что же делать, чтобы произвести его расчет в нелинейной функции? В Экселе имеется и такая возможность. Её можно осуществить с помощью инструмента «Регрессия», который является составной частью пакета «Анализ данных».
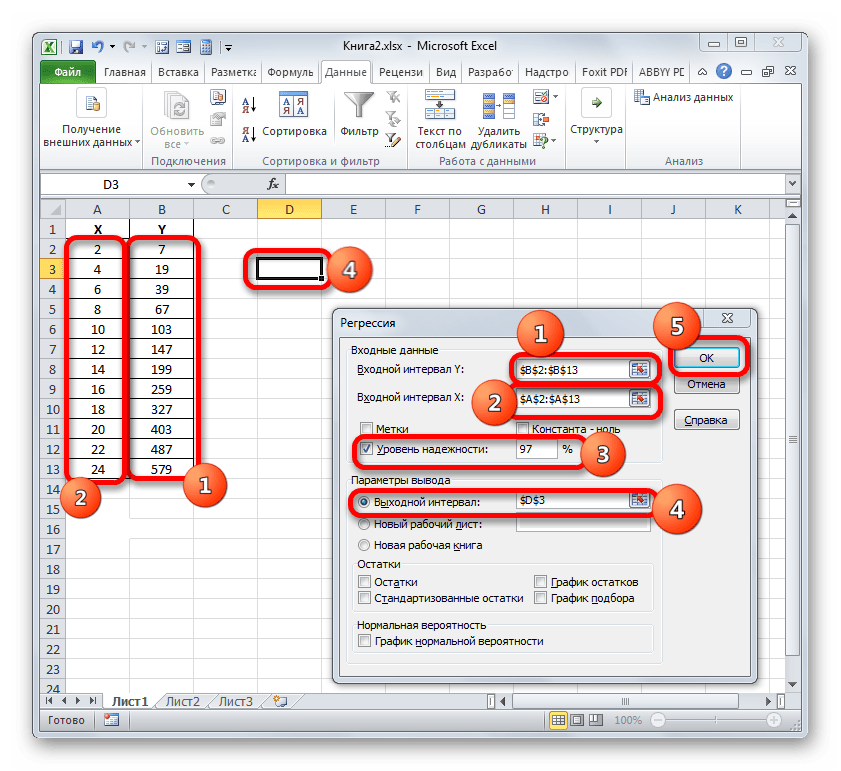
Около параметров «Метка» и «Константа-ноль» флажки не ставим. Флажок можно установить около параметра «Уровень надежности» и в поле напротив указать желаемую величину соответствующего показателя (по умолчанию 95%).
В группе «Параметры вывода» нужно указать, в какой области будет отображаться результат вычисления. Существует три варианта:
Остановим свой выбор на первом варианте, чтобы исходные данные и результат размещались на одном рабочем листе. Ставим переключатель около параметра «Выходной интервал». В поле напротив данного пункта ставим курсор. Щелкаем левой кнопкой мыши по пустому элементу на листе, который призван стать левой верхней ячейкой таблицы вывода итогов расчета. Адрес данного элемента должен высветиться в поле окна «Регрессия».
Группы параметров «Остатки» и «Нормальная вероятность» игнорируем, так как для решения поставленной задачи они не важны. После этого клацаем по кнопке «OK», которая размещена в правом верхнем углу окна «Регрессия».
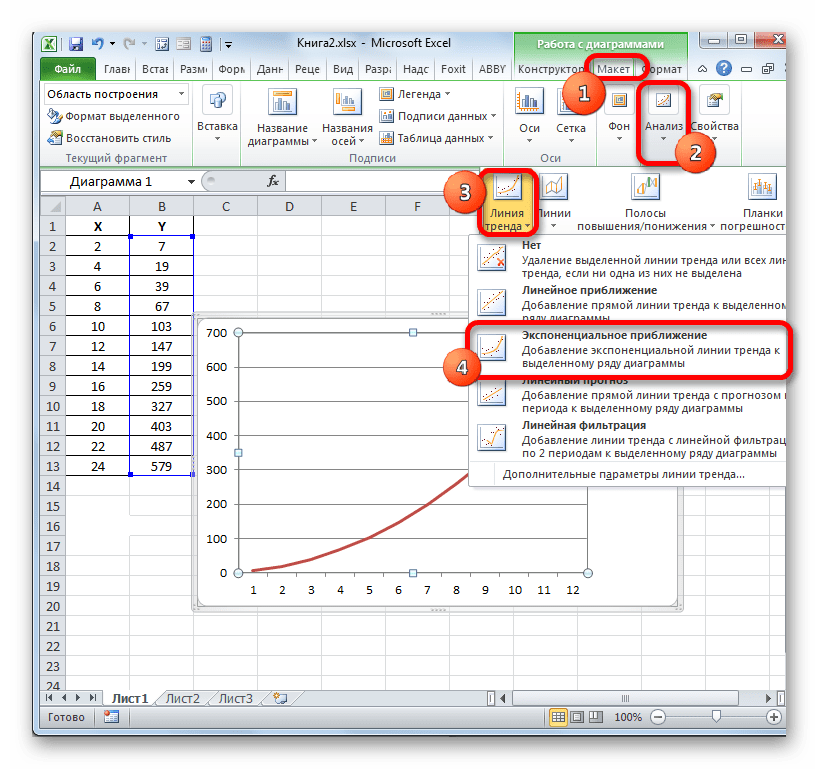
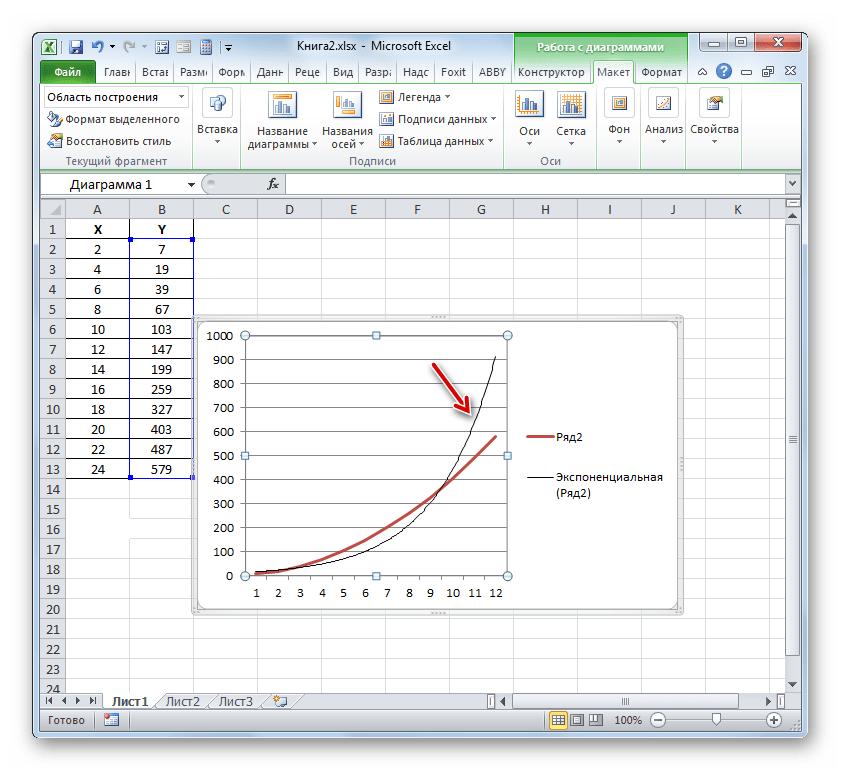
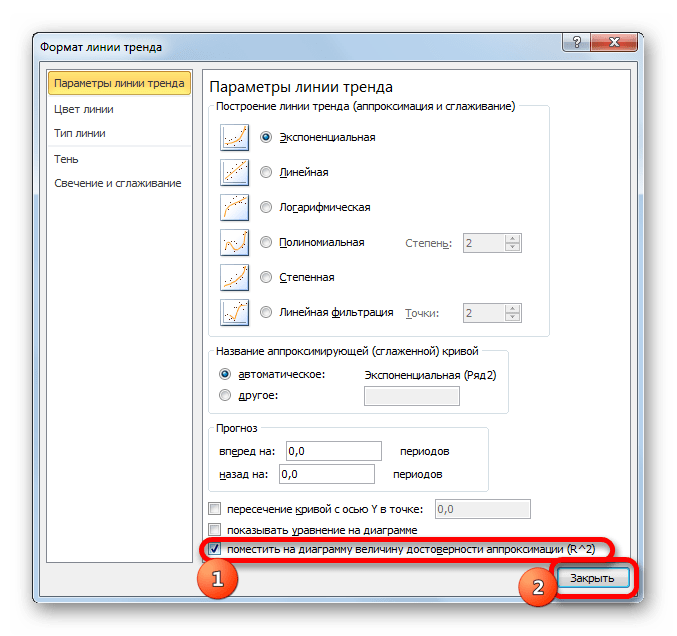
Способ 3: коэффициент детерминации для линии тренда
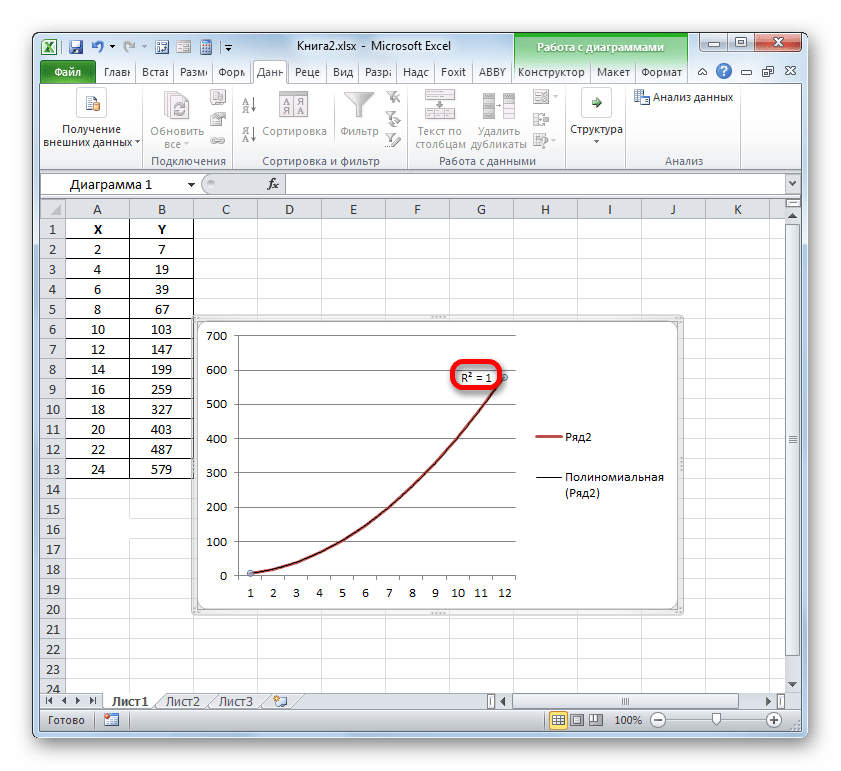
Кроме указанных выше вариантов, коэффициент детерминации можно отобразить непосредственно для линии тренда в графике, построенном на листе Excel. Выясним, как это можно сделать на конкретном примере.
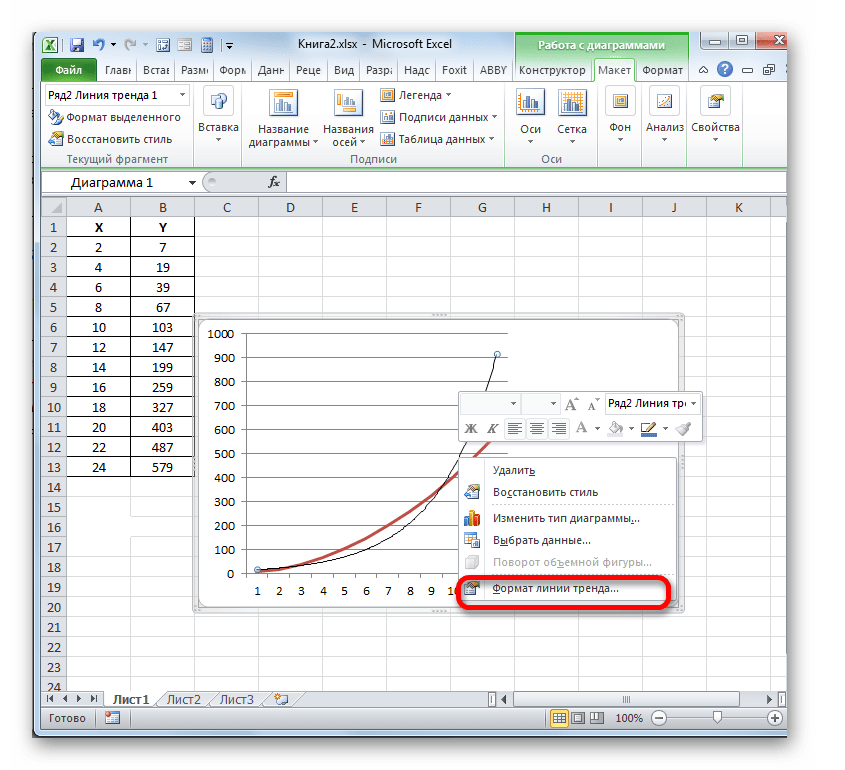
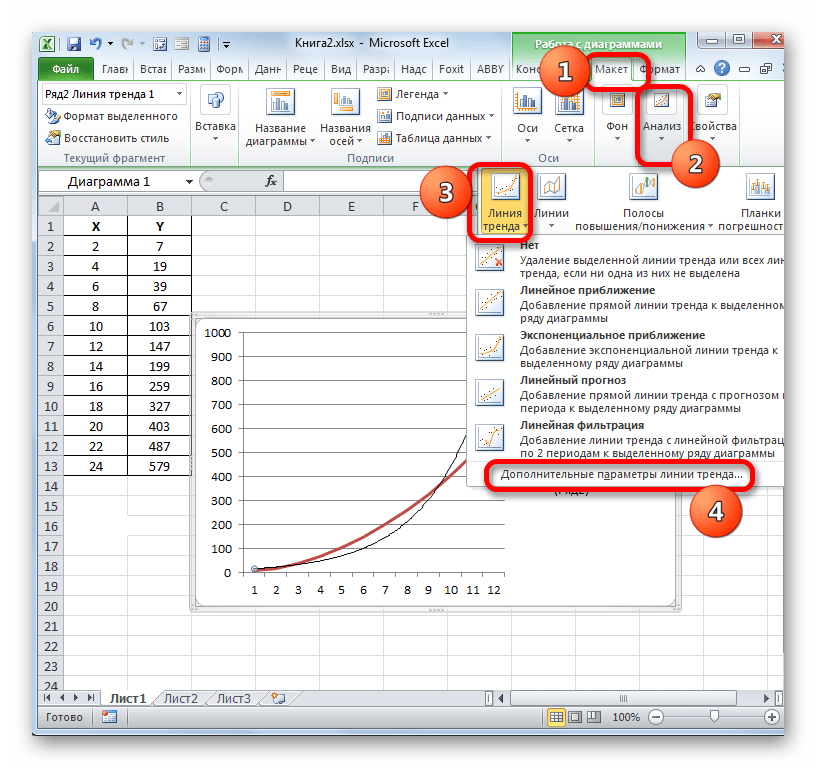
Для выполнения перехода в окно формата линии тренда можно выполнить альтернативное действие. Выделяем линию тренда кликом по ней левой кнопки мыши. Перемещаемся во вкладку «Макет». Клацаем по кнопке «Линия тренда» в блоке «Анализ». В открывшемся списке клацаем по самому последнему пункту перечня действий – «Дополнительные параметры линии тренда…».
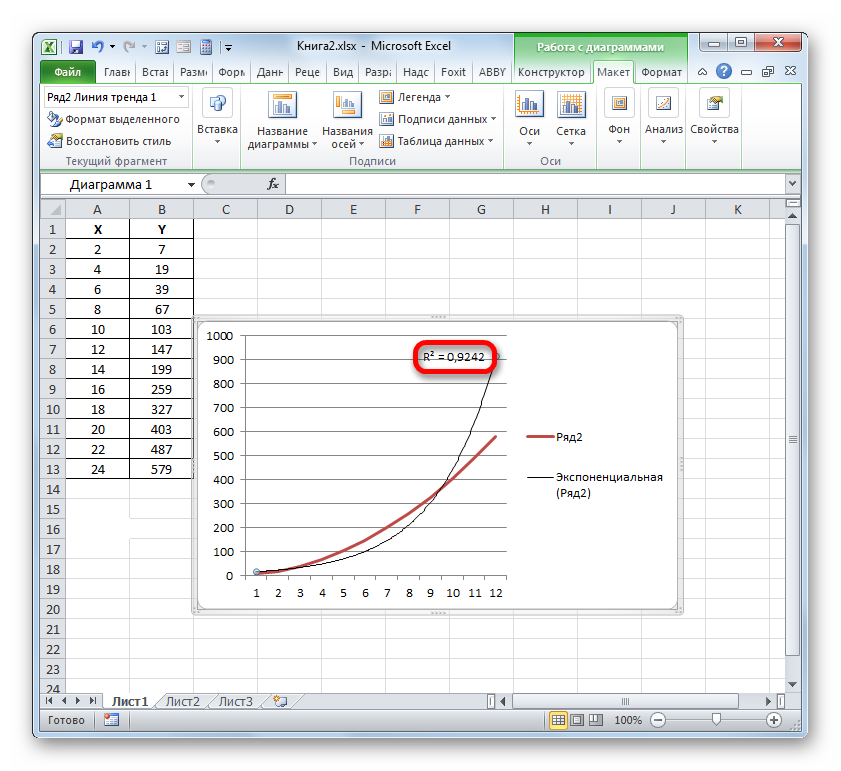
Например, для нашего случая опытным путем удалось установить, что самый высокий уровень достоверности имеет полиномиальный тип линии тренда второй степени. Коэффициент детерминации в данном случае равен 1. Это говорит о том, что указанная модель абсолютно достоверная, что означает полное исключение погрешностей.
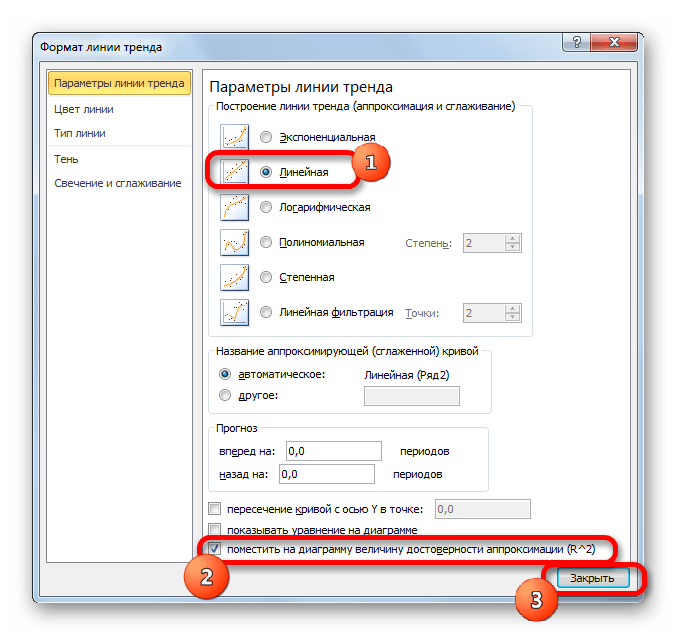
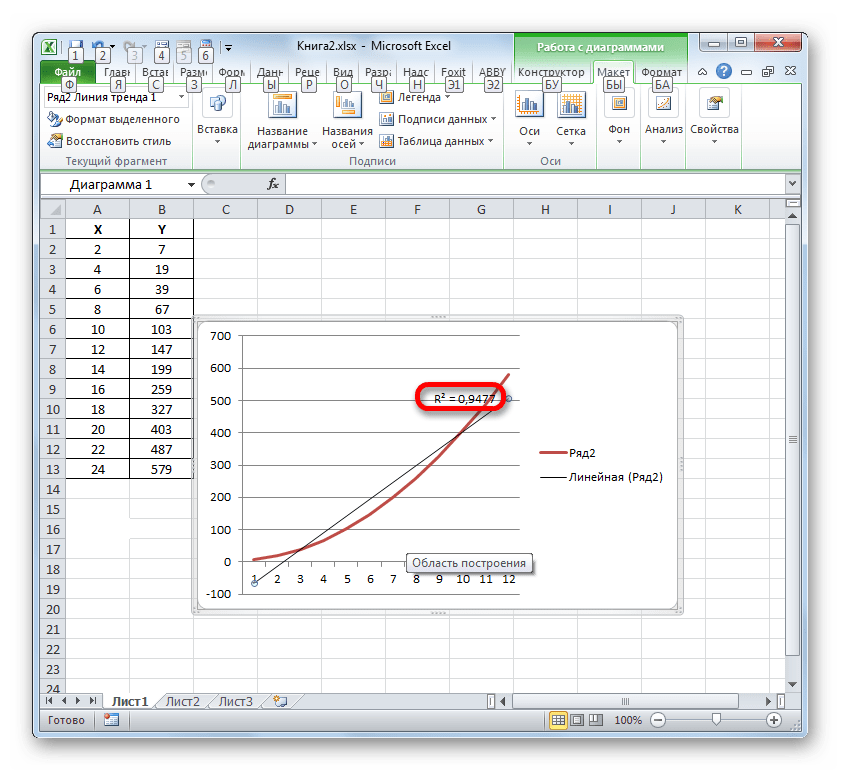
Но, в то же время, это совсем не значит, что для другого графика тоже наиболее достоверным окажется именно этот тип линии тренда. Оптимальный выбор типа линии тренда зависит от типа функции, на основании которой был построен график. Если пользователь не обладает достаточным объемом знаний, чтобы «на глаз» прикинуть наиболее качественный вариант, то единственным выходом определения лучшего прогноза является как раз сравнение коэффициентов детерминации, как было показано на примере выше.
В Экселе существуют два основных варианта вычисления коэффициента детерминации: использование оператора КВПИРСОН и применение инструмента «Регрессия» из пакета инструментов «Анализ данных». При этом первый из этих вариантов предназначен для использования только в процессе обработки линейной функции, а другой вариант можно использовать практически во всех ситуациях. Кроме того, существует возможность отображения коэффициента детерминации для линии трендов графиков в качестве величины достоверности аппроксимации. С помощью данного показателя имеется возможность определить тип линии тренда, который располагает самым высоким уровнем достоверности для конкретной функции.
Помимо этой статьи, на сайте еще 12542 инструкций. Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.