Описательная статистика в EXCEL
history 17 ноября 2016 г.
Рассмотрим инструмент Описательная статистика, входящий в надстройку Пакет Анализа. Рассчитаем показатели выборки: среднее, медиана, мода, дисперсия, стандартное отклонение и др.
Надстройка Пакет анализа
Выборку разместим на листе Пример в файле примера в диапазоне А6:А55 (50 значений).
Примечание : Для удобства написания формул для диапазона А6:А55 создан Именованный диапазон Выборка.
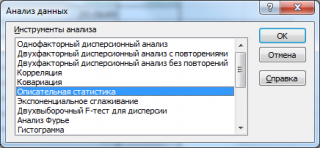
После нажатия кнопки ОК будет выведено другое диалоговое окно,
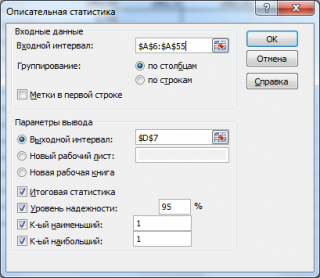
в котором нужно указать:
В результате будут выведены следующие статистические показатели: 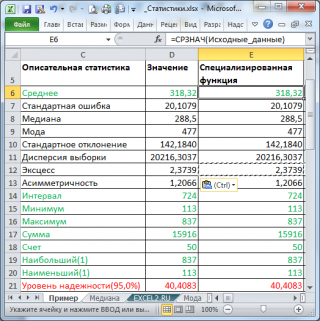
Все показатели выведены в виде значений, а не формул. Если массив данных изменился, то необходимо перезапустить расчет.
Зеленым цветом на картинке выше и в файле примера выделены показатели, которые не требуют особого пояснения. Для большинства из них имеется специализированная функция:
Ниже даны подробные описания остальных показателей.
Среднее выборки
Медиана выборки
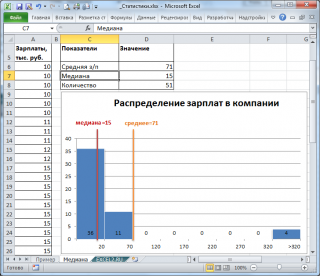 Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что как минимум у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что как минимум у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Медиану также можно вычислить с помощью формул
СОВЕТ : Подробнее про квартили см. статью, про перцентили (процентили) см. статью.
Мода выборки
Примечание : Если в массиве нет повторяющихся значений, то функция вернет значение ошибки #Н/Д. Это свойство использовано в статье Есть ли повторы в списке?
Понятно, что для нашего массива число 477, хотя и является наиболее часто повторяющимся значением, но все же является плохой оценкой для моды распределения, из которого взята выборка (наиболее вероятного значения или для которого плотность вероятности распределения максимальна).
Например, в рассмотренном примере о распределении заработных плат (см. раздел статьи выше, о Медиане), модой является число 15 (17 значений из 51, т.е. 33%). В этом случае функция МОДА() дает хорошую оценку «наиболее вероятного» значения зарплаты.
Мода и среднее значение
Примечание : Мода и среднее симметричных распределений совпадает (имеется ввиду симметричность плотности распределения ).
Представим, что мы бросаем некий «неправильный» кубик, у которого на гранях имеются значения (1; 2; 3; 4; 6; 6), т.е. значения 5 нет, а есть вторая 6. Модой является 6, а среднее значение – 3,6666.
Другой пример. Для Логнормального распределения LnN(0;1) мода равна =EXP(m-s2)= EXP(0-1*1)=0,368, а среднее значение 1,649.
Дисперсия выборки
Стандартное отклонение выборки
По определению, стандартное отклонение равно квадратному корню из дисперсии : 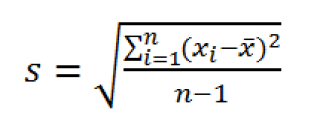
Вычислим стандартное отклонение для 2-х выборок : (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается.
Стандартное отклонение можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера ): =КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Стандартная ошибка
Примечание : Чтобы разобраться с понятием Стандартная ошибка среднего необходимо прочитать о выборочном распределении (см. статью Статистики, их выборочные распределения и точечные оценки параметров распределений в MS EXCEL ) и статью про Центральную предельную теорему .
В MS EXCEL стандартную ошибку среднего можно также вычислить по формуле =СТАНДОТКЛОН.В(Выборка)/ КОРЕНЬ(СЧЁТ(Выборка))
Асимметричность
Положительное значение коэффициента асимметрии указывает, что размер правого «хвоста» распределения больше, чем левого (относительно среднего). Отрицательная асимметрия, наоборот, указывает на то, что левый хвост распределения больше правого. Коэффициент асимметрии идеально симметричного распределения или выборки равно 0. 
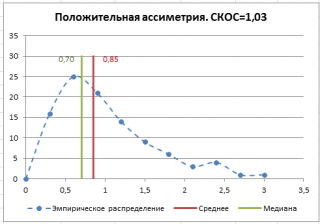
Эксцесс выборки
Эксцесс показывает относительный вес «хвостов» распределения относительно его центральной части.
Примечание : Не смотря на старания профессиональных статистиков, в литературе еще попадается определение Эксцесса как меры «остроконечности» (peakedness) или сглаженности распределения. Но, на самом деле, значение Эксцесса ничего не говорит о форме пика распределения.
Согласно определения, Эксцесс равен четвертому стандартизированному моменту: 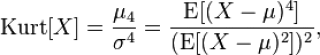
Как видно из формулы MS EXCEL использует именно Kurtosis excess, т.е. для выборки из нормального распределения формула вернет близкое к 0 значение.
Если задано менее четырех точек данных, то функция ЭКСЦЕСС() возвращает значение ошибки #ДЕЛ/0!
Уровень надежности
Вычисление асимметрии и эксцесса эмпирического распределения в Excel.
Асимметрия вычисляется функцией СКОС. Ее аргументом является интервал ячеек с данными, например, =СКОС(А1:А100), если данные содержатся в интервале ячеек от А1 до А100.
Эксцесс вычисляется функцией ЭКСЦЕСС, аргументом которой являются числовые данные, заданные, как правило, в виде интервала ячеек, например: =ЭКСЦЕСС(А1:А100).
§2.3. Инструмент анализа Описательная статистика
В Excel имеется возможность вычислить сразу все точечные характеристики выборки с помощью инструмента анализа Описательная статистика, который содержится в Пакете анализа.
Описательная статистика создает таблицу основных статистических характеристик для совокупности данных. В этой таблице будут содержаться следующие характеристики: среднее, стандартная ошибка, дисперсия, стандартное отклонение, мода, медиана, размах варьирования интервала, максимальное и минимальное значения, асимметрия, эксцесс, объем совокупности, сумма всех элементов совокупности, доверительный интервал (уровень надежности). Инструмент Описательная статистика существенно упрощает статистический анализ тем, что отпадает необходимость вызывать каждую функцию для расчета статистических характеристик отдельно.
Для того, чтобы вызвать Описательную статистику, следует:
в меню Сервис выбрать команду Анализ данных;
в списке Инструменты анализа диалогового окна Анализ данных выбрать инструмент Описательная статистика и нажать ОК.
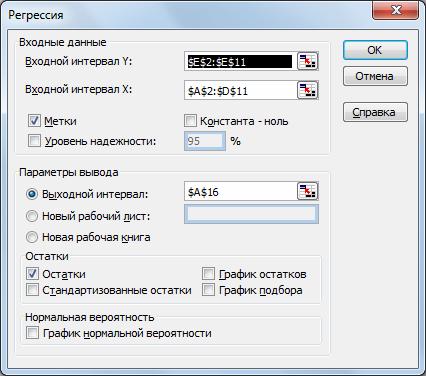
В окне Описательная статистика необходимо:
в группе Входные данные в поле Входной интервал указать интервал ячеек, содержащих данные;
если первая строка во входном диапазоне содержит заголовок столбца, то в поле Метки в первой строке следует поставить галочку;
в группе Параметры вывода активизировать переключатель (поставить галочку) Итоговая статистика, если нужен полный список характеристик;
активизировать переключатель Уровень надежности и указать надежность в %, если необходимо вычислить доверительный интервал (по умолчанию надежность равна 95%). Нажать ОК.
В результате появится таблица с вычисленными значениями указанных выше статистических характеристик. Сразу, не сбрасывая выделения этой таблицы, выполните команду Формат®Столбец®Автоподбор ширины.
Вид диалогового окна Описательная статистика:

Практические задания
2.1. Вычисление основных точечных статистических характеристик с помощью стандартных функции Excel
Одним и тем же вольтметром было измерено 25 раз напряжение на участке цепи. В результате опытов получены следующие значения напряжения в вольтах:
32, 32, 35, 37, 35, 38, 32, 33, 34, 37, 32, 32, 35,
34, 32, 34, 35, 39, 34, 38, 36, 30, 37, 28, 30.
Найти среднюю, выборочные и исправленные дисперсию, стандартное отклонение, размах варьирования, моду, медиану. Проверить отклонение от нормального распределения, вычислив асимметрию и эксцесс.
Для выполнения этого задания проделайте следующие пункты.
Наберите результаты эксперимента в столбец А.
В ячейку В1 наберите «Среднее», в В2 – «Выборочная дисперсия», в В3 – «Стандартное отклонение», в В4 – «Исправленная дисперсия», в В5 – «Исправленное стандартное отклонение», в В6 – «Максимум», в В7 – «Минимум», в В8 – «Размах варьирования», в В9 – «Мода», в В10 – «Медиана», в В11 – «Асимметрия», в В12 – «Эксцесс».
Выровняйте ширину этого столбца с помощью Автоподбора ширины.
Выделите ячейку С1 и нажмите на кнопку со знаком «=» в строке формул. С помощью Мастера функций в категории Статистические найдите функцию СРЗНАЧ, затем выделите интервал ячеек с данными и нажмите ОК.
Выделите ячейку С2 и нажмите на знак =в строке формул. С помощью Мастера функций в категории Статистические найдите функцию ДИСПР, затем выделите интервал ячеек с данными и нажмите ОК.
Проделайте самостоятельно аналогичные действия для вычисления остальных характеристик.
Для вычисления размаха варьирования в ячейку С8 следует ввести формулу: =C6-C7.
Добавьте перед вашей таблицей одну строку, в которую наберите заголовки соответствующих столбцов: «Наименование характеристик» и «Численные значения».
В результате выполнения всего задания вы должны получить следующую таблицу:
| Наименование характеристик | Численные значения |
| Среднее | 34,04 |
| Выборочная дисперсия | 7,3984 |
| Стандартное отклонение | 2,72 |
| Исправленная дисперсия | 7,706667 |
| Исправленное стандартное отклонение | 2,776088 |
| Максимум | |
| Минимум | |
| Размах варьирования | |
| Мода | |
| Медиана | |
| Асимметрия | -0,14648 |
| Эксцесс | -0,4282 |
Дата добавления: 2015-01-12 ; просмотров: 20 | Нарушение авторских прав
Функция СКОС и коэффициент асимметрии распределения в Excel
Функция СКОС в Excel предназначена для определения коэффициента асимметрии для последовательности числовых данных и возвращает соответствующее числовое значение.
Расчет коэффициента асимметрии распределения чисел в Excel
Коэффициент асимметрии показывает степень несимметричности распределения числовых данных относительно среднего значения. Может принимать следующие значения:
Для определения коэффициента асимметрии используется уравнение:
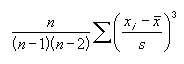
Пример 1. В таблице Excel содержатся два ряда числовых данных. Определить, какой из числовых рядов характеризуется наименьшим коэффициентом асимметрии.
Вид таблицы данных:
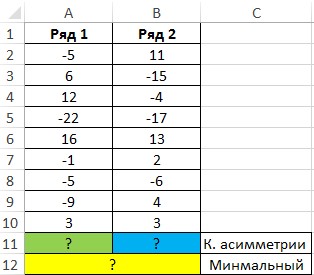
Для решения используем следующую формулу:
С помощью функции ЕСЛИ выполняем проверку коэффициента симметрии («имеет ли второй ряд большее значение скоса?») и возвращаем соответствующее значение с пояснением.
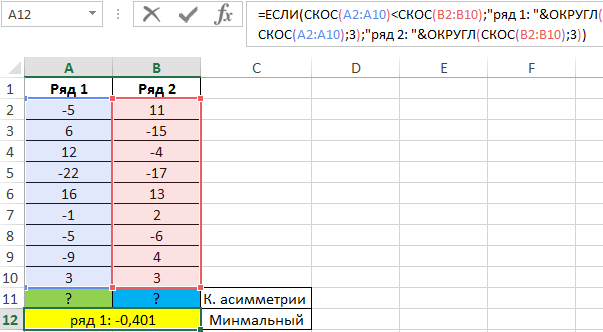
Проверим значения для каждого ряда по отдельности с помощью функций:
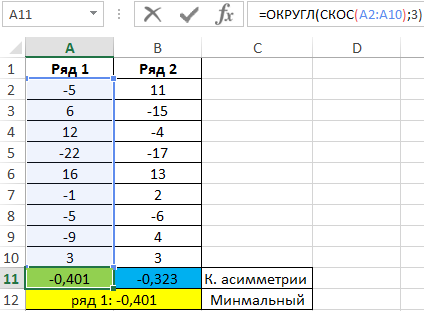
Обе последовательности имеют отклонения в отрицательную сторону, но у ряда 1 это выражено в большей степени.
Коэффициент асимметрии и аппроксимация нормальным распределением в Excel
Пример 2. Имеем последовательность чисел. Необходимо проанализировать данную последовательность и сделать вывод о возможности аппроксимации нормальным распределением.
Вид таблицы данных:
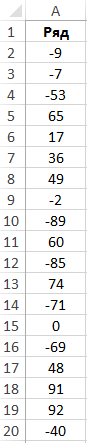
Для проверки нормального распределения величины применяют довольно сложные статистические критерии. Однако, в простейшем случае можно определить две величины (коэффициент асимметрии и эксцесс), чтобы сделать определенные выводы. Если они близки к нулю, аппроксимация нормальным распределением допустима.
Определим значения асимметрии и эксцесса следующими функциями:
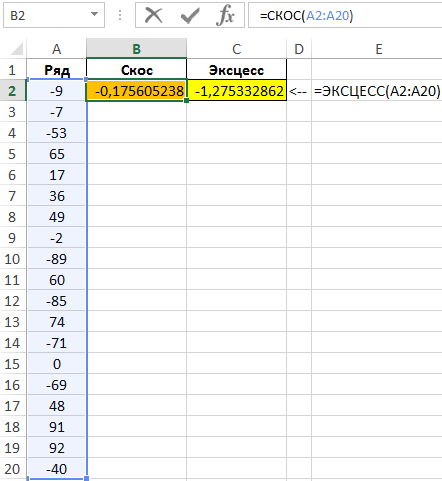
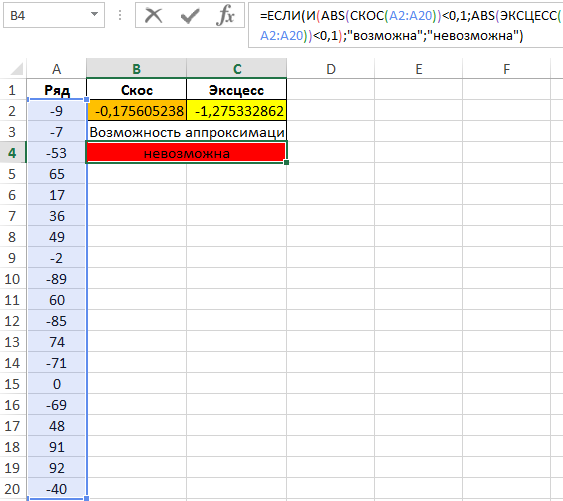
Отклонения от 0 значительны, поэтому аппроксимация невозможна. Чтобы автоматизировать подобные расчеты введем некоторые условия:
В данном случае принято допущение о том, что максимальное допустимое отклонение модулей асимметрии и эксцесса составляет 0,1
Правила использования функции СКОС в Excel
Функция имеет следующую синтаксическую запись:
=СКОС( число1; [число2];. )
Как посчитать эксцесс в excel
По численным значениям асимметрии и эксцесса можно приближенно оценить нормальность распределения результатов испытаний. А и Е рассчитывают так:

В Excel А и Е можно рассчитать при помощи статистических функций СКОС (для А) и ЭКСЦЕСС (для Е).
Дисперсии А и Е рассчитывают так:

Если  , то результаты испытаний считают распределёнными нормально.
, то результаты испытаний считают распределёнными нормально.
Пример 14.1. Проверить гипотезу нормальности распределения результатов испытаний: 32,30 31,60 31,70 32,36 32,92 32,61 32,48 32,47 32,46 32,74 32,63 32,68 31,74 32,17 32,25 32,28 32,26 32,29 32,28 31,73.
Возможный вариант расчёта по примеру 14.1 показан на рис 14.1.

Рис.14.1. Вариант расчёта по примеру 14.1.
Вводим в лист MS Excel номера результатов (хотя бы до 1000 – для возможности пересчёта при других данных). Вводим результаты испытаний и сортируем их в вариационный ряд (хотя в данном случае это не обязательно). Рассчитываем объём испытаний n (в Excel функция СЧЁТ), асимметрию (функция СКОС), эксцесс (ЭКСЦЕСС), модуль асимметрии и эксцесса (с использованием функции ABS), дисперсию асимметрии и эксцесса, а также  . Далее выводим сообщение о соответствии или несоответствии распределения нормальному. Для этого используем функцию ЕСЛИ. В строку Логическое_выражение диалогового этой функции вводим неравенство
. Далее выводим сообщение о соответствии или несоответствии распределения нормальному. Для этого используем функцию ЕСЛИ. В строку Логическое_выражение диалогового этой функции вводим неравенство  . После этого в эту же строку вводим функцию И. В открывшемся окне в строку Логическое значение 1 вводим неравенство
. После этого в эту же строку вводим функцию И. В открывшемся окне в строку Логическое значение 1 вводим неравенство  . Затем устанавливаем курсор в строке формул на слово ЕСЛИ. В результате этого возвращаемся в окно функции ЕСЛИ. В этом окне в строке Значение_если_истина вводим «Распределение нормальное», а в строку Значение_если_ложь – «Распределение не нормальное». В результате формула будет выглядеть, как показано на рис. 14.1
. Затем устанавливаем курсор в строке формул на слово ЕСЛИ. В результате этого возвращаемся в окно функции ЕСЛИ. В этом окне в строке Значение_если_истина вводим «Распределение нормальное», а в строку Значение_если_ложь – «Распределение не нормальное». В результате формула будет выглядеть, как показано на рис. 14.1
Задание.
Выполнить расчёты по примеру 14.1.
        Далее     Содержание
Как в офисе
Среднее отклонение в Excel
Добрый день, уважаемые любители статистического анализа данных, а сегодня еще и программы Excel.
Проведение любого статанализа немыслимо без расчетов. И сегодня в рамках рубрики «Работаем в Excel» мы научимся рассчитывать показатели вариации. Теоретическая основа была рассмотрена ранее в ряде статей о вариации данных. Кстати, на этом указанная тема не закончилась, к выпуску планируются новые статьи — следите за рекламой! Однако сухая теория без инструментов реализации — вещь не сильно полезная. Поэтому по мере появления теоретических выкладок, я стараюсь не отставать с заметками о соответствующих расчетах в программе Excel.
Сегодняшняя публикация будет посвящена расчету в Excel следующих показателей вариации:
— максимальное и минимальное значение
— среднее линейное отклонение
— дисперсия (по генеральной совокупности и по выборке)
— среднее квадратическое отклонение (по генеральной совокупности и по выборке)
Факт возможности расчета упомянутых показателей в Excel свидетельствует о практическом их использовании. И, несмотря на очевидность некоторых моментов, я постараюсь расписать все подробно.
Этот показатель представляет собой отношение стандартного отклонения к среднему арифметическому. Полученный результат выражается в процентах.
В Экселе не существует отдельно функции для вычисления этого показателя, но имеются формулы для расчета стандартного отклонения и среднего арифметического ряда чисел, а именно они используются для нахождения коэффициента вариации.
Шаг 1: расчет стандартного отклонения
Стандартное отклонение, или, как его называют по-другому, среднеквадратичное отклонение, представляет собой квадратный корень из дисперсии. Для расчета стандартного отклонения используется функция СТАНДОТКЛОН. Начиная с версии Excel 2010 она разделена, в зависимости от того, по генеральной совокупности происходит вычисление или по выборке, на два отдельных варианта: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В.
Синтаксис данных функций выглядит соответствующим образом:
= СТАНДОТКЛОН(Число1;Число2;…) = СТАНДОТКЛОН.Г(Число1;Число2;…) = СТАНДОТКЛОН.В(Число1;Число2;…)
- Для того, чтобы рассчитать стандартное отклонение, выделяем любую свободную ячейку на листе, которая удобна вам для того, чтобы выводить в неё результаты расчетов. Щелкаем по кнопке «Вставить функцию». Она имеет внешний вид пиктограммы и расположена слева от строки формул.



Урок: Формула среднего квадратичного отклонения в Excel
Шаг 2: расчет среднего арифметического
Среднее арифметическое является отношением общей суммы всех значений числового ряда к их количеству. Для расчета этого показателя тоже существует отдельная функция — СРЗНАЧ. Вычислим её значение на конкретном примере.
- Выделяем на листе ячейку для вывода результата. Жмем на уже знакомую нам кнопку «Вставить функцию».




Урок: Как посчитать среднее значение в Excel
Шаг 3: нахождение коэффициента вариации
Теперь у нас имеются все необходимые данные для того, чтобы непосредственно рассчитать сам коэффициент вариации.
- Выделяем ячейку, в которую будет выводиться результат. Прежде всего, нужно учесть, что коэффициент вариации является процентным значением. В связи с этим следует поменять формат ячейки на соответствующий. Это можно сделать после её выделения, находясь во вкладке «Главная». Кликаем по полю формата на ленте в блоке инструментов «Число». Из раскрывшегося списка вариантов выбираем «Процентный». После этих действий формат у элемента будет соответствующий.



Таким образом мы произвели вычисление коэффициента вариации, ссылаясь на ячейки, в которых уже были рассчитаны стандартное отклонение и среднее арифметическое. Но можно поступить и несколько по-иному, не рассчитывая отдельно данные значения.
- Выделяем предварительно отформатированную под процентный формат ячейку, в которой будет выведен результат. Прописываем в ней формулу по типу:
Вместо наименования «Диапазон значений» вставляем реальные координаты области, в которой размещен исследуемый числовой ряд. Это можно сделать простым выделением данного диапазона. Вместо оператора СТАНДОТКЛОН.В, если пользователь считает нужным, можно применять функцию СТАНДОТКЛОН.Г.


Существует условное разграничение. Считается, что если показатель коэффициента вариации менее 33%, то совокупность чисел однородная. В обратном случае её принято характеризовать, как неоднородную.
Как видим, программа Эксель позволяет значительно упростить расчет такого сложного статистического вычисления, как поиск коэффициента вариации. К сожалению, в приложении пока не существует функции, которая высчитывала бы этот показатель в одно действие, но при помощи операторов СТАНДОТКЛОН и СРЗНАЧ эта задача очень упрощается. Таким образом, в Excel её может выполнить даже человек, который не имеет высокого уровня знаний связанных со статистическими закономерностями.
Расчет среднего арифметического
Вычисляется, когда пользователю необходимо создать отчет, например, по заработной плате в его компании. Делается это следующим образом:
Рассчитываем коэффициент в Экселе
К сожалению, в Excel не заложена стандартная формула, которая бы позволила рассчитать показатель вариации автоматически. Но это не значит, что вам придётся производить расчёты в уме. Отсутствие шаблона в «Строке формул» никоим образом не умаляет способностей Excel, потому вы вполне сможете заставить программу выполнить необходимый вам расчёт, прописав соответствующую команду вручную.
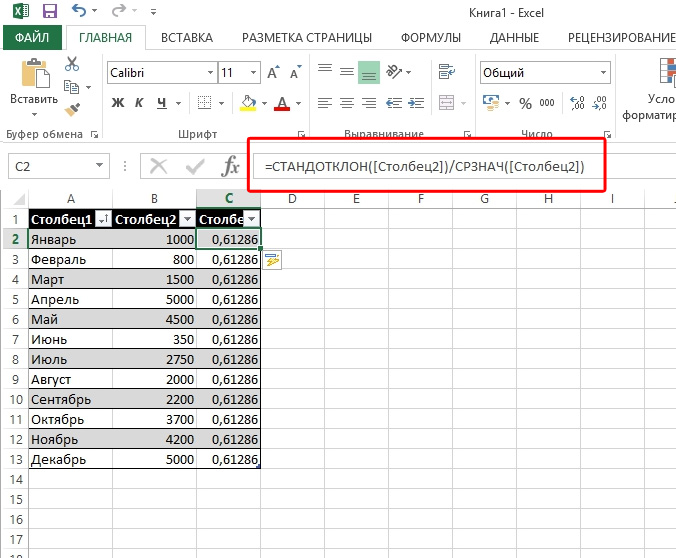
Вставьте формулу и укажите диапазон данных
Для того чтобы рассчитать показатель вариации в Excel, необходимо вспомнить школьный курс математики и разделить стандартное отклонение на среднее значение выборки. То есть на деле формула выглядит следующим образом — СТАНДОТКЛОН(заданный диапазон данных)/СРЗНАЧ(заданный диапазон данных). Ввести эту формулу необходимо в ту ячейку Excel, в которой вы хотите получить нужный вам расчёт.
Не забывайте и о том, что поскольку коэффициент выражается в процентах, то ячейке с формулой нужно будет задать соответствующий формат. Сделать это можно следующим образом:
Как вариант, можно задать процентный формат ячейке при помощи клика по правой кнопке мыши на активированной клеточке таблицы. В появившемся контекстном меню, аналогично вышеуказанному алгоритму нужно выбрать категорию «Формат ячейки» и задать необходимое значение.
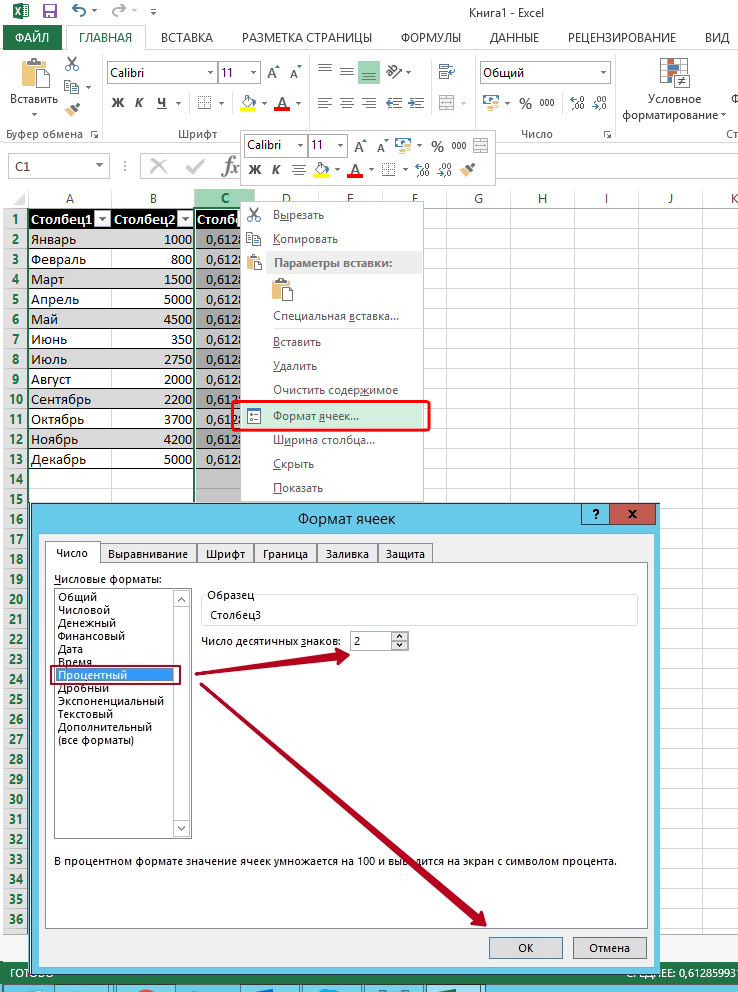
Выберите «Процентный», а при необходимости укажите число десятичных знаков
Возможно, кому-то вышеописанный алгоритм покажется сложным. На самом же деле расчёт коэффициента так же прост, как сложение двух натуральных чисел. Единожды выполнив эту задачу в Экселе, вы больше никогда не вернётесь к утомительным многосложным решениям в тетрадке.
Всё ещё не можете сделать качественное сравнение степени разброса данных? Теряетесь в масштабах выборки? Тогда прямо сейчас принимайтесь за дело и осваивайте на практике весь теоретический материал, который был изложен выше! Пусть статистический анализ и разработка прогноза больше не вызывают у вас страха и негатива. Экономьте свои силы и время вместе с табличным редактором Excel.
Примеры расчета
Пример 1
Портфельный менеджер должен оценить риски инвестирования в акции двух компаний А и Б. При этом он рассматривает 5 сценариев развития событий, информация по которым представлена в таблице.

Поскольку нам известно точное распределение доходности каждой из акций, мы можем рассчитать истинное значение среднеквадратического отклонения доходности для каждой из них.
Шаг 1. Рассчитаем математическое ожидание доходности для каждой из акций.
Шаг 2. Подставим полученные данные в первую формулу.

Как мы можем видеть, акции Компании А характеризуются меньшим уровнем риска, поскольку у них ниже среднеквадратическое отклонение доходности. Следует также отметить, что и ожидаемая доходность у них ниже, чем у акций Компании Б.
Пример 2
Аналитик располагает данными о доходности двух ценных бумаг за последние 5 лет, которые представлены в таблице.

Поскольку точное распределение доходности неизвестно, а в распоряжении аналитика есть только выборка из генеральной совокупности данных, мы можем рассчитать стандартное отклонение выборки на основании несмещенной дисперсии.
Шаг 1. Рассчитаем ожидаемую доходность для каждой ценной бумаги как среднеарифметическое выборки.
X А = (7 + 15 + 2 – 5 + 6) ÷ 5 = 5%
X Б = (3 – 2 + 12 + 4 +8) ÷ 5 = 5%
Шаг 2. Рассчитаем стандартное отклонение доходности для каждой из ценных бумаг по формуле для выборки из генеральной совокупности данных.

Следует отметить, что обе ценные бумаги имеют равную ожидаемую доходность 5%. При этом стандартное отклонение доходности у ценной бумаги Б ниже, что при прочих равных делает ее более привлекательным объектом инвестирования в следствие лучшего профиля риск-доходность.
Алгоритм работы
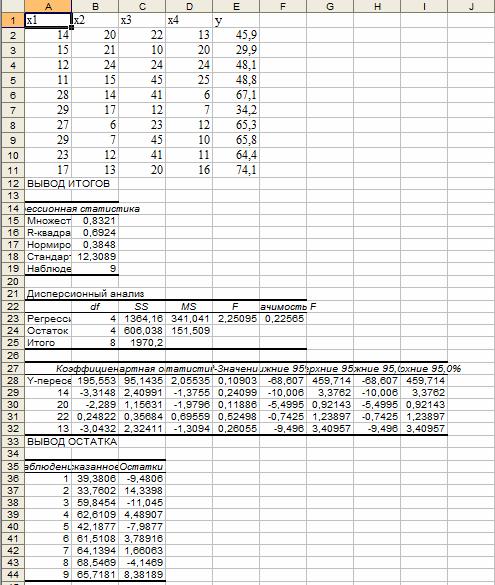
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка mb коэффициента b | Стандартная ошибка ma коэффициента a |
| Коэффициент детерминации R 2 | Стандартное отклонение остатков Sост |
| Значение F–статистики | Число степеней свободы, равное n-2 |
| Регрессионная сумма квадратов | Остаточная сумма квадратов |
Как выполнить расчет Z-теста в Excel (пошаговый пример)
Excel Z TEST – это своего рода проверка гипотез, которая используется для проверки альтернативной гипотезы против нулевой гипотезы. Нулевая гипотеза – это гипотеза, которая относится к общему утверждению в целом. Путем проверки гипотезы мы пытаемся доказать, что нулевая гипотеза ложна против альтернативной гипотезы.
Z-ТЕСТ – одна из таких функций проверки гипотез. Это проверяет среднее значение двух наборов данных выборки, когда дисперсия известна и размер выборки большой. Размер выборки должен быть> = 30, иначе нам нужно использовать T-TEST. Для ZTEST нам нужно иметь две независимые точки данных, которые не связаны друг с другом или не влияют друг на друга, и данные должны быть нормально распределены.
Синтаксис
Z.TEST – это встроенная функция в Excel. Ниже приведена формула функции Z.TEST в excel.

Как выполнить тест Z в Excel? (с примерами)
Пример # 1 – Использование формулы Z-теста
Например, посмотрите на данные ниже.
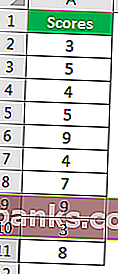
Используя эти данные, мы рассчитаем одностороннее значение вероятности Z TEST. Для этого предположим, что среднее значение гипотезы равно 6.
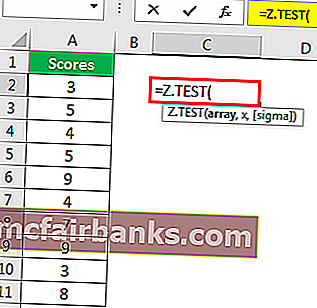
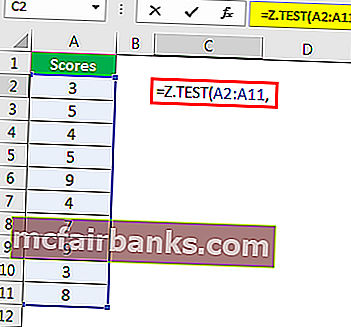
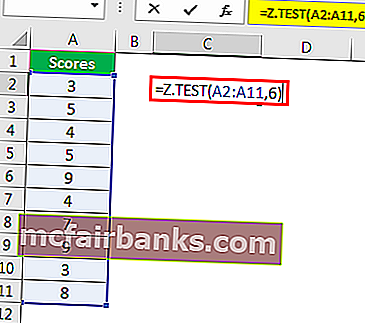
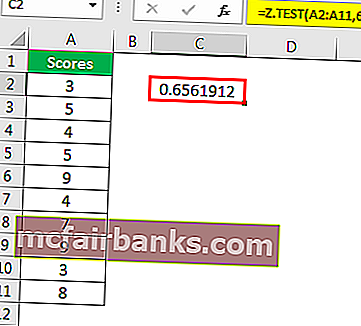
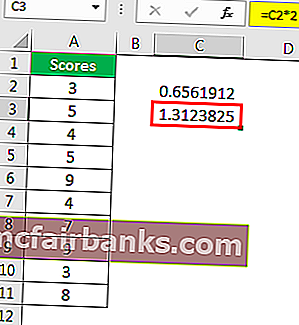
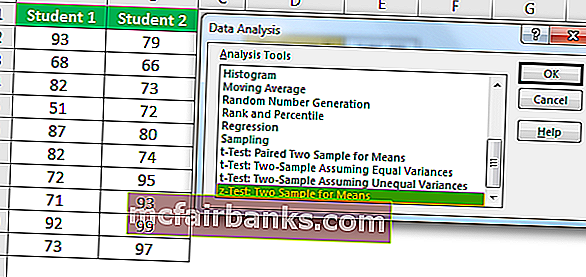
Пример # 2 – Z-ТЕСТ с использованием опции анализа данных
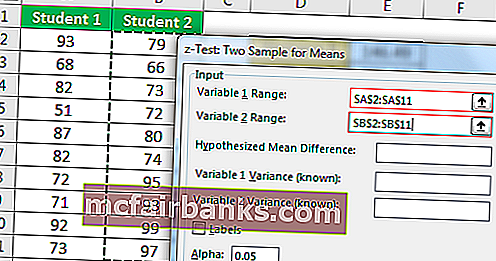
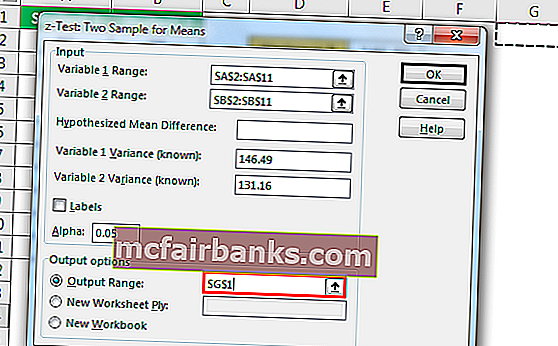
Мы можем провести Z TEST, используя опцию анализа данных в Excel. Чтобы сравнить два средних значения, когда дисперсия известна, мы используем Z TEST. Здесь мы можем сформулировать две гипотезы, одна – «Нулевая гипотеза», а другая – «Альтернативная гипотеза», ниже приводится уравнение обеих этих гипотез.
H0: μ1 – μ2 = 0 (нулевая гипотеза)
H1: μ1 – μ2 ≠ 0 (альтернативная гипотеза)
Альтернативная гипотеза (H1) утверждает, что два средних значения совокупности не равны.
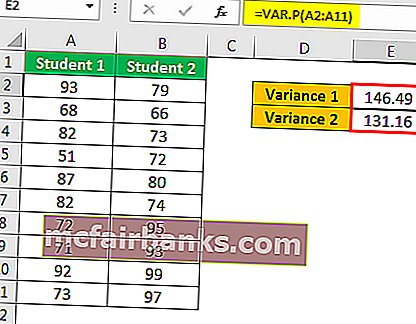
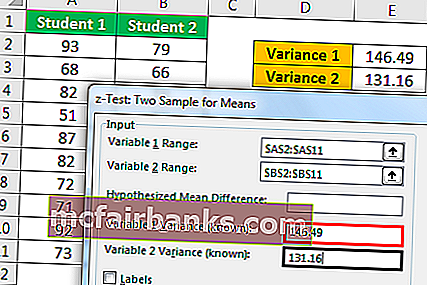
В этом примере мы будем использовать результаты двух учеников по нескольким предметам.
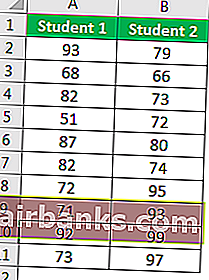

Прокрутите вниз и выберите z-Test Two Sample для средних и нажмите Ok.
мы получили результат.
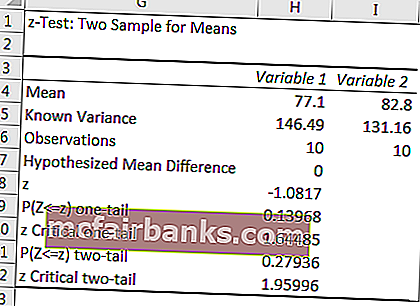
Если Z Z Critical Two Tail, то мы можем отклонить нулевую гипотезу.
Итак, из результата ZTEST ниже приведены результаты.
Создаем графу Группа по методу ABC. Подтягиваем код группы из таблицы ABC анализа с помощью формулы: =ВПР(A3;ABC!$A$1:$G$12;7;0)
Как настроить формулу ВПР:
Задача функции: по коду товара в исходной таблице найти значение А, В или С и перенести его отчётную таблицу XYZ.
А3 — параметр, по которому ищем значение, например «Товар 6».
ABC!$A$1:$G$12 — ссылка на диапазон исходной таблицы. В ней строго в первом столбце должен быть параметр, по которому ищем значение «Товар 6».
7 — порядковый номер столбца, в котором в исходной находятся значения (коды А, В, С)
— значение ЛОЖЬ. Для Ecxel признак того, что искомый результат должен соответствовать всем 3-м предыдущим условиям.
По каждому товару получаем двойную кодировку ABC и XYZ аналитики.
Для наглядности можно скрепить лва кода по каждому товару.
Товары AX — высокоприбыльные позиции, которые формируют 70% выручки. На них стабильный спрос.
Товары CZ — позиции с самым низким спросом. Сюда могут попасть как неликвиды, так и элитные товары с редким спросом. Требуется дополнительная аналитика.
Подробнее о сути, эффективности и недостатках ABC XYZ анализа читайте здесь.
Определение числовых характеристик по экспериментальным данным в табличном процессоре Excel
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | лабораторная работа |
| Язык | русский |
| Дата добавления | 18.04.2013 |
| Размер файла | 31,4 K |
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
ОПРЕДЕЛЕНИЕ ЧИСЛОВЫХ ХАРАКТЕРИСТИК ПО ЭКСПЕРИМЕНТАЛЬНЫМ ДАННЫМ В ТАБЛИЧНОМ ПРОЦЕССОРЕ EXCEL
1. Теоретические основы
На практике очень часто приходится иметь дело с различными опытами. Качественная характеристика результата опыта есть событие. А количественной характеристикой случайного результата опыта является случайная величина. Сл у чайной величиной называется величина, которая в результате опыта может принять то или иное (но только одно) значение, причем до опыта неизвестно, какое именно.
Среди случайных величин можно выделить два основных типа: дискретные величины и непрерывные величины. Дискретной случайной величиной называется величина, число возможных значений которой либо конечное, либо бесконечное счетное множество. Случайной непрерывной величиной называется такая величина, возможные значения которой непрерывно заполняют некоторый интервал (конечный или бесконечный) числовой оси. Очевидно, что возможных значений случайной непрерывной величины бесконечно.
На практике в психологии чаще всего используют именно дискретную случайную величину. Приведем пример: предположим, исследуется уровень интеллекта в какой-либо группе испытуемых. В результате эксперимента каждый из обследованных выдаст некое значение. Мы не можем заранее предсказать, какова будет величина этого значения: 70, 100, 130 баллов и т.п., – и потому наша величина СЛУЧАЙНА. Даже если людей в группе столько, что обязательно отыщутся те, у кого будет 71 балл, 72, 73, 74… и так далее – до 127, 128, 129, 130, то все равно не может быть человека, набравшего 129,5 балла или 71,5 балла – и потому наша случайная величина ДИСКРЕТНА.
Значения наблюдаемых в практике случайных величин более или менее колеблются около среднего значения. Это явление называется рассеянием величины около ее среднего значения. Числовые характеристики, характеризующие рассеяние случайной величины, называются характеристиками рассеивания, основными из которых являются дисперсия и средне квадратичное отклонение.
Дисперсией случайной величины называется математическое ожидание квадрата отклонения величины от ее математического ожидания
Соответственно, для дискретной случайной величины дисперсия выражается суммой
где pi – вероятность случайной величины.
Средним квадратическим отклонением случайной величины называется корень квадратный из ее дисперсии:
Для чего вообще необходимы понятия дисперсии и среднеквадратического отклонения?
Во многих экспериментах необходимо знать, как в среднем характеризуется данная исследуемая величина, какое, в среднем, она может принять значение. (Допустим, надо определить, каков, в среднем, показатель интеллекта в той или иной группе лиц.)Пусть известно, что средний показатель интеллекта в некой группе равен такому-то числу. Что можно сказать об интеллекте группы, на основании лишь знания этого среднего показателя? Решительно ничего. Ведь неизвестно, все ли значения тесно сгруппированы вокруг среднего (все демонстрируют средний интеллект) или половина показателей очень низких, а половина – очень высоких. Может статься, что большинство демонстрируют интеллект выше среднего, но показатели одного-двух человек так низки, что «тянут» назад всю группу. В каждом из трех вариантов может быть одно и то же среднее значение.
В таком случае требуется иметь такую характеристику, которая бы говорила о том, сколь велик разброс значений вокруг среднего, или сколь далеко, как правило, от среднего отстоит любое, случайно взятое, значение. Для ответа на этот вопрос и служит такая математическая величина, как ДИСПЕРСИЯ, то есть – мера рассеяния. Что касается среднеквадратического отклонения, то оно более удобно на практике, так как сохраняет размерность исследуемой величины.
Обобщением основных числовых характеристик случайных величин является понятие моментов случайных величин. В теории вероятности различают моменты двух видов: начальные и центральные.
Начальным моментом k-го порядка случайной величины X называют математическое ожидание величины x k :
Из начальных моментов особое значение имеет момент первого порядка, который представляет собой математическое ожидание случайной величины.
Начальные моменты высших порядков используются главным образом для вычисления центральных моментов.
Центральным моментом к-го порядка случайной величины X называют математическое ожидание величины (X-M(X)) k :
Среди центральных моментов случайной величины особое значение имеет центральный момент второго порядка, который представляет собой дисперсию случайной величины.
На практике, кроме математического ожидания, применяются и другие характеристики положения случайной величины, в частности мода и медиана. Модой М случайной дискретной величины называется ее наиболее вероятное значение.
Медианой МD случайной величины Х называется такое ее значение, относительно которого равновероятно получение большего или меньшего значения случайной величины, т.е.
Третий центральный момент служит характеристикой асимметрии («скошенности») распределения. Так как третий центральный момент имеет размерность куба случайной величины, то обычно рассматривают безразмерную величину – отношение 3 к среднему квадратическому отклонению в третьей степени
величина носит название коэффициента асимметрии.
Четвертый центральный момент служит для характеристик островершинности или плосковершинности распределения. Эти свойства распределения описываются с помощью так называемого эксцесса. Эксцессом случайной величины Х называется величина
2. Задания на лабораторную работу
Экспериментально определены скорости, с которыми люди записывают цифры арабского алфавита:
Как рассчитать значения полинома в Excel?
Есть 3 способа расчета значений полинома в Excel:
1-й способ расчета полинома — с помощью графика
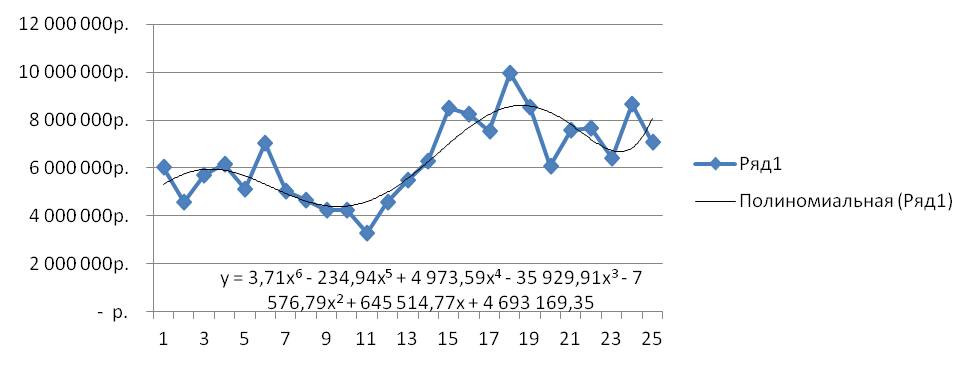
Выделяем ряд со значениями и строим график временного ряда.
На график добавляем полином 6-й степени.
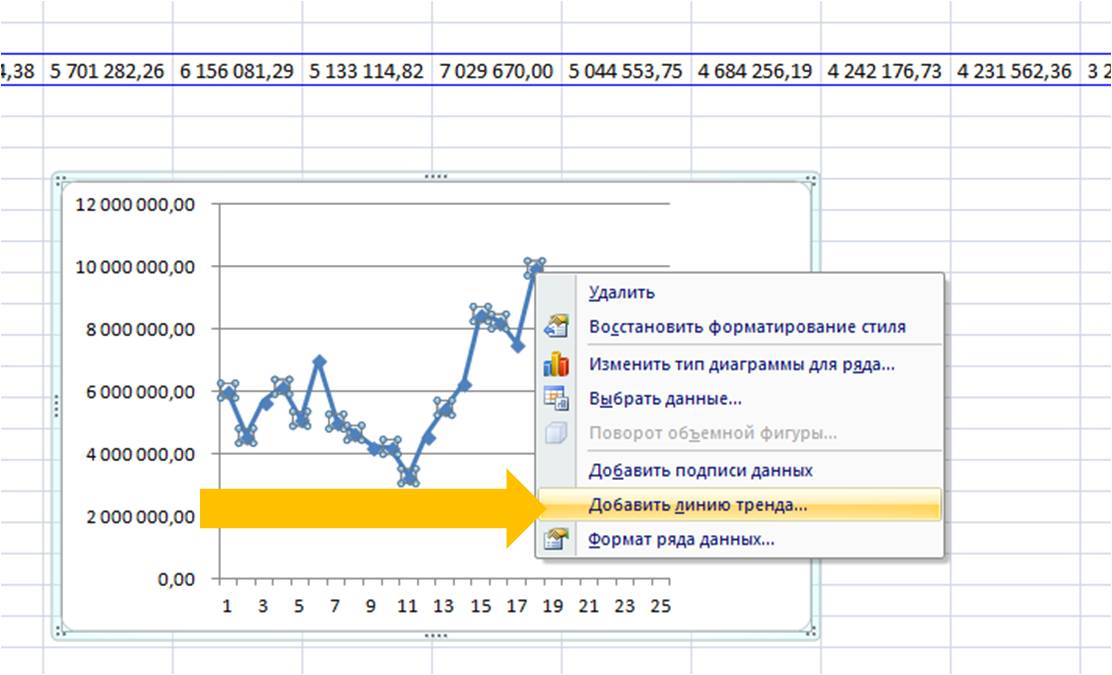
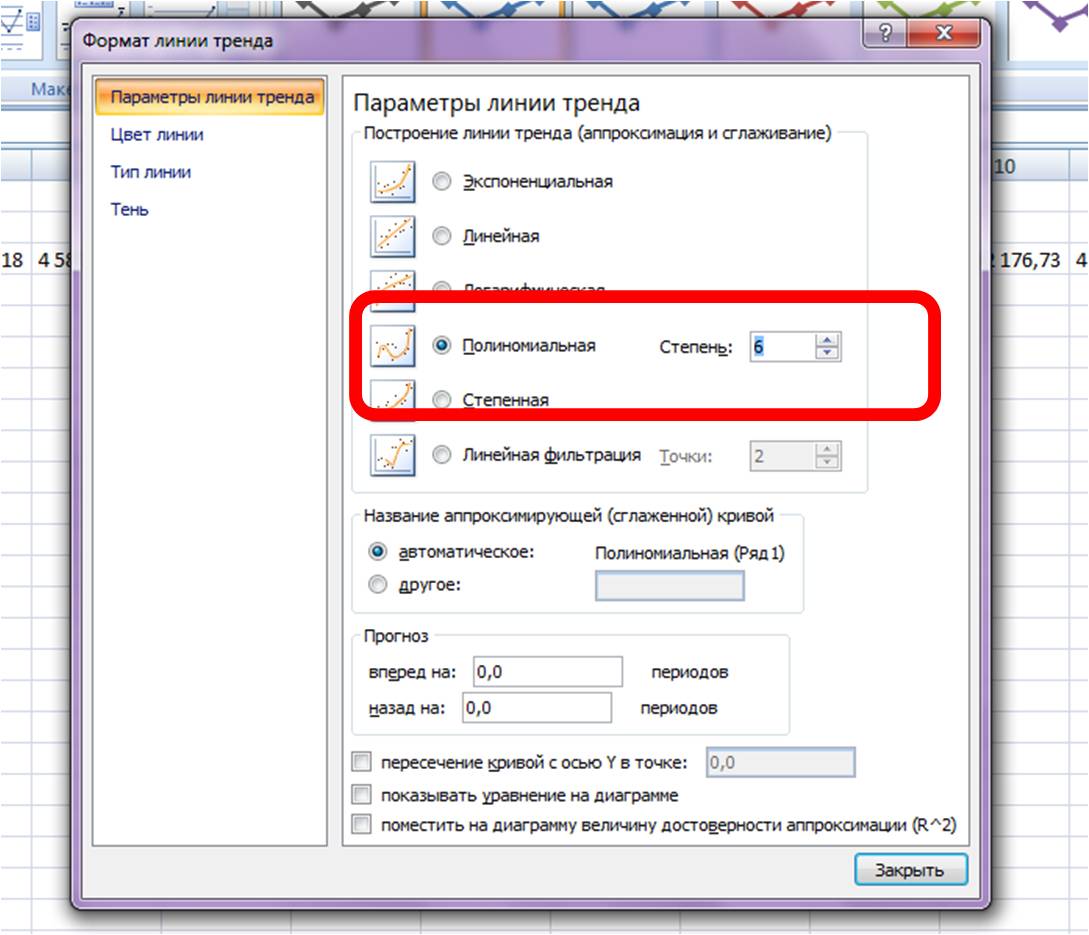
Затем в формате линии тренда ставим галочку “показать уравнение на диаграмме”
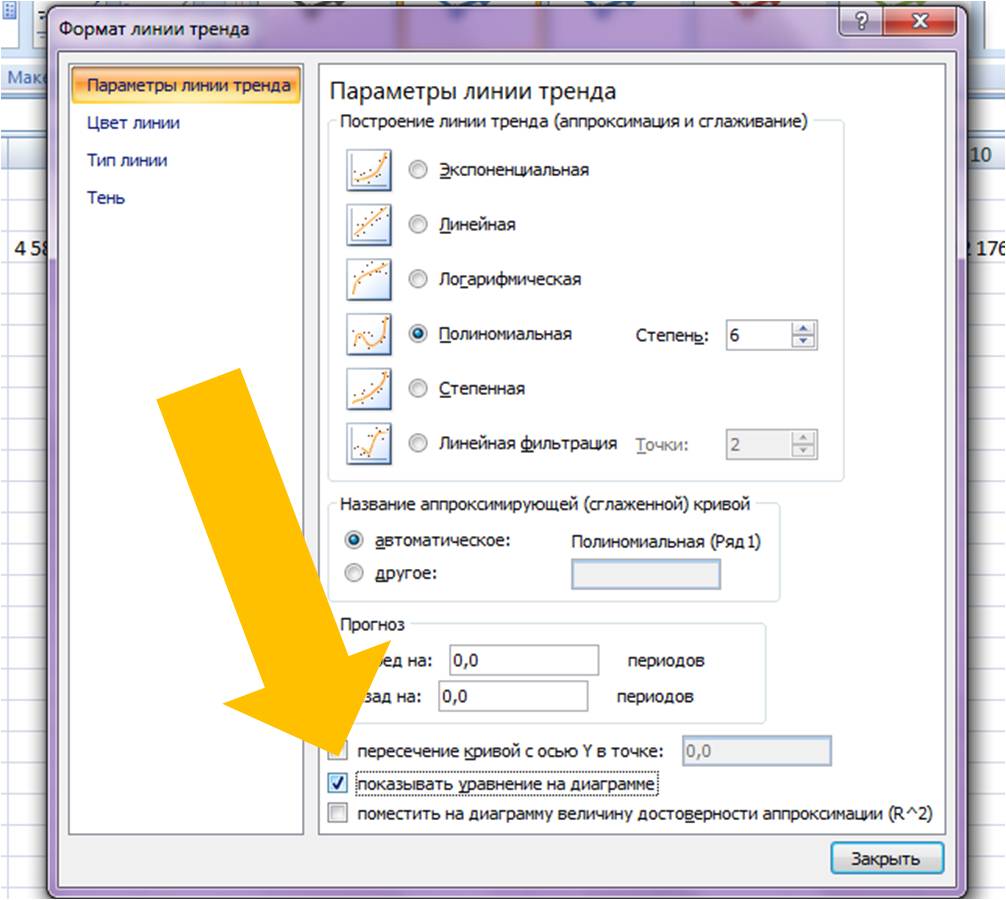
Нажимаем правой кнопкой и выбираем “формат подписи линии тренда”
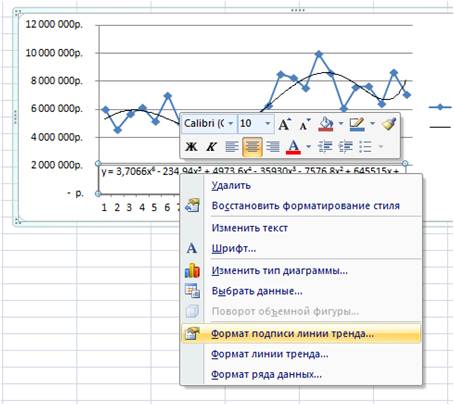
В настройках подписи линии тренда выбираем число и в числовых форматах выбираем “Числовой”.
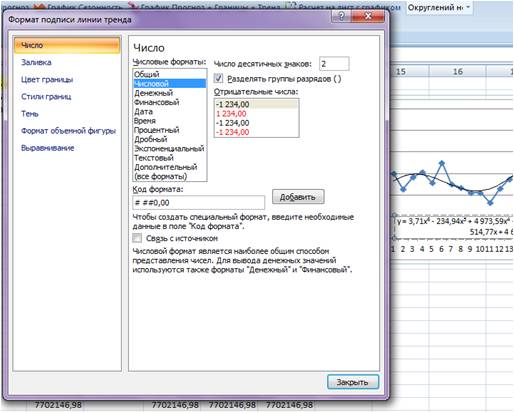
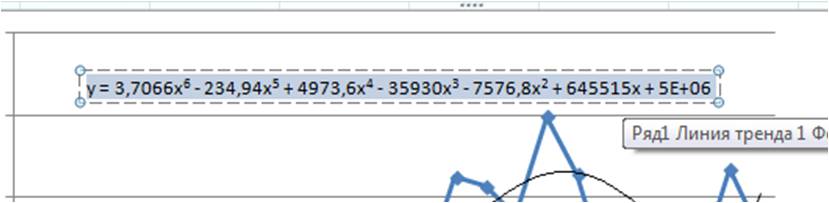
Получаем уравнение полинома в читаемом формате:
y = 3,71x 6 – 234,94x 5 + 4 973,59x 4 – 35 929,91x 3 – 7 576,79x 2 + 645 514,77x + 4 693 169,35
Из этого уравнения берем коэффициенты a, b, c, d, g, m, v, и вводим в соответствующие ячейки Excel

Каждому периоду во временном ряду присваиваем порядковый номер, который будем подставлять в уравнение вместо X.

Рассчитаем значения полинома для каждого периода. Для этого вводим формулу полинома y = 3,71x 6 – 234,94x 5 + 4 973,59x 4 – 35 929,91x 3 – 7 576,79x 2 + 645 514,77x + 4 693 169,35 в первую ячейку и фиксируем ссылки на коэффициенты тренда (см. статью как зафиксировать ссылки)
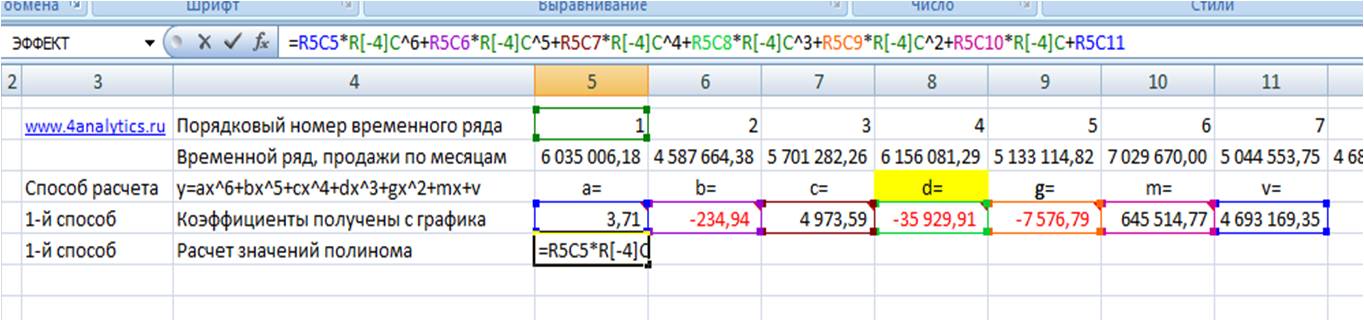
Получаем формулу следующего вида:
= R2C8 *RC[-3]^6+ R3C8 *RC[-3]^5+ R4C8 *RC[-3]^4+ R5C8 *RC[-3]^3+ R6C8 *RC[-3]^2+ R7C8 *RC[-3]+ R8C8
в которой коэффициенты тренда зафиксированы и вместо “x” мы подставляем ссылку на номер текущего временного ряда (для первого значение 1, для второго 2 и т.д.)
Также “X” возводим в соответствующую степень (значок в Excel “^” означает возведение в степень)
=R2C8*RC[-3] ^6 +R3C8*RC[-3] ^5 +R4C8*RC[-3] ^4 +R5C8*RC[-3] ^3 +R6C8*RC[-3] ^2 +R7C8*RC[-3]+R8C8
Теперь протягиваем формулу до конца временного ряда и получаем рассчитанные значения полиномиального тренда для каждого периода.
2-й способ расчета полинома в Excel — функция ЛИНЕЙН()
Рассчитаем коэффициенты линейного тренда с помощью стандартной функции Excel =ЛИНЕЙН()
Для расчета коэффициентов в формулу =ЛИНЕЙН(известные значения y, известные значения x, константа, статистика) вводим:
Получаем следующего вида формулу:
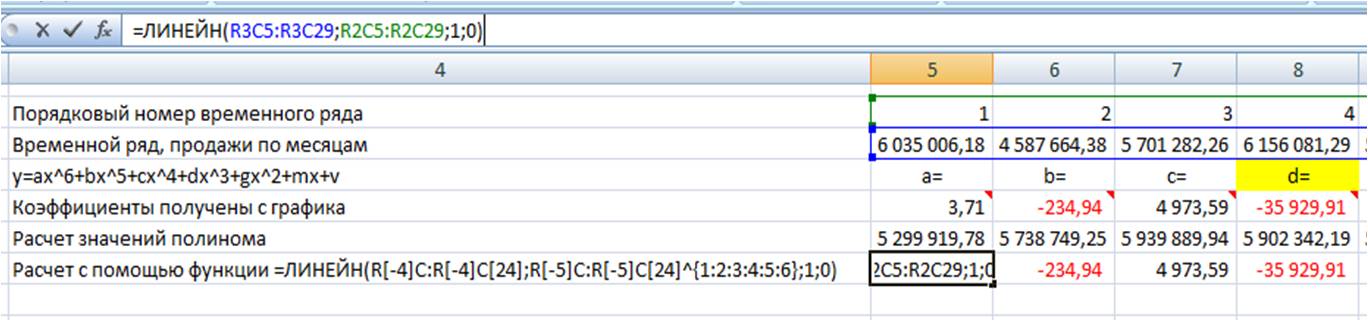
Теперь, чтобы формула Линейн() рассчитала коэффициенты полинома, нам в неё надо дописать степень полинома, коэффициенты которого мы хотим рассчитать.
Для этого в часть формулы с “известными значениями x” вписываем степень полинома:
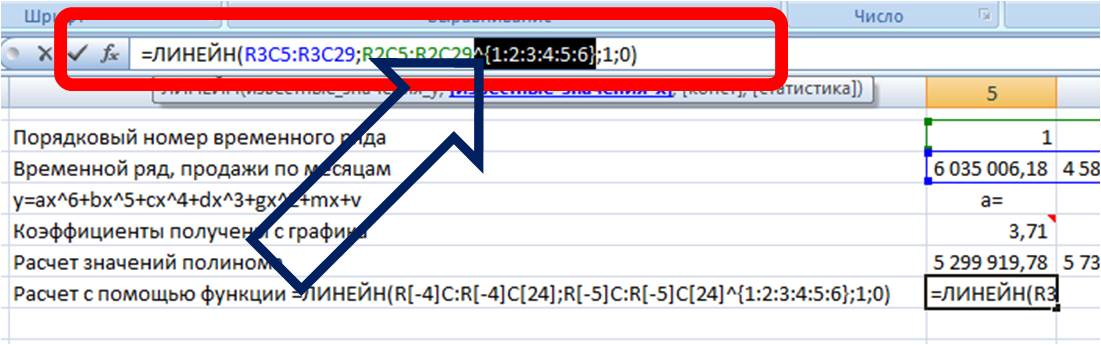
Получаем формулу следующего вида:
Вводим формулу в ячейку, получаем 3,71 —- значение (a) для полинома 6-й степени y=ax^6+bx^5+cx^4+dx^3+gx^2+mx+v
Для того, чтобы Excel рассчитал все 7 коэффициентов полинома 6-й степени y=ax^6+bx^5+cx^4+dx^3+gx^2+mx+v, необходимо:
1. Установить курсор в ячейку с формулой и выделить 7 соседних ячеек справа, как на рисунке:

2. Нажать на клавишу F2
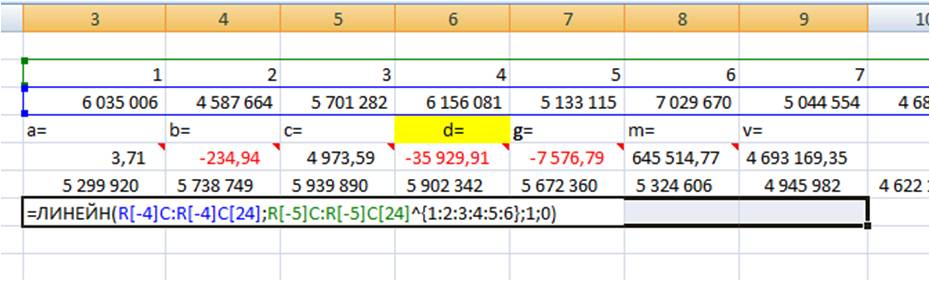
3. Затем одновременно — клавиши CTRL + SHIFT + ВВОД (т.е. ввести формулу массива, как это сделать читайте подробно в статье “Как ввести формулу массива”)

Получаем 7 коэффициентов полиномиального тренда 6-й степени.
Каждому периоду во временном ряду присваиваем порядковый номер, который будем подставлять в уравнение полинома вместо X.
Рассчитаем значения полиномиального тренда для каждого периода. Для этого вводим формулу полинома в первую ячейку и фиксируем ссылки на коэффициенты тренда (см. статью как зафиксировать ссылки)
Получаем формулу следующего вида:
= R2C8 *RC[-3]^6+ R3C8 *RC[-3]^5+ R4C8 *RC[-3]^4+ R5C8 *RC[-3]^3+ R6C8 *RC[-3]^2+ R7C8 *RC[-3]+ R8C8
в которой коэффициенты тренда зафиксированы и вместо “x” мы подставляем ссылку на номер текущего временного ряда (для первого значение 1, для второго 2 и т.д.)
Также “X” возводим в соответствующую степень (значок в Excel “^” означает возведение в степень)
=R2C8*RC[-3] ^6 +R3C8*RC[-3] ^5 +R4C8*RC[-3] ^4 +R5C8*RC[-3] ^3 +R6C8*RC[-3] ^2 +R7C8*RC[-3]+R8C8
Теперь протягиваем формулу до конца временного ряда и получаем рассчитанные значения полиномиального тренда для каждого периода.
2-й способ точнее, чем первый, т.к. коэффициенты тренда мы получаем без округления, а также этот расчет быстрее.
3-й способ расчета значений полиномиальных трендов — Forecast4AC PRO
Устанавливаем курсор в начало временного ряда
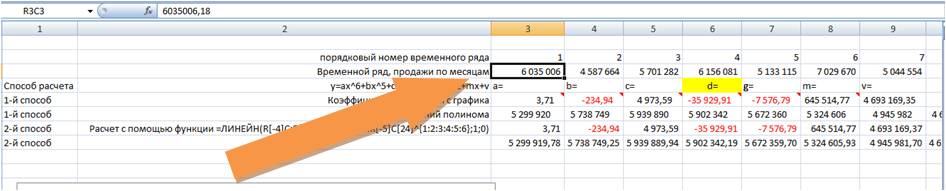
Заходим в настройки Forecast4AC PRO, выбираем “Прогноз с ростом и сезонностью”, “Полином 6-й степени”, нажимаем кнопку “Рассчитать”.
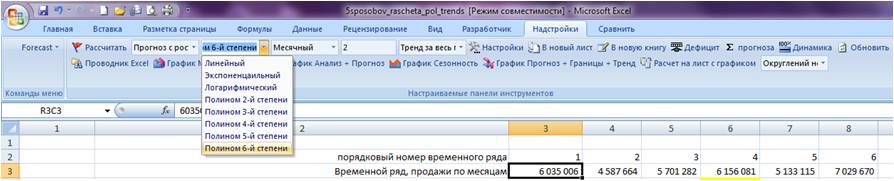
Заходим в лист с пошаговым расчетом “ForPol6”, находим строку “Сложившийся тренд”:
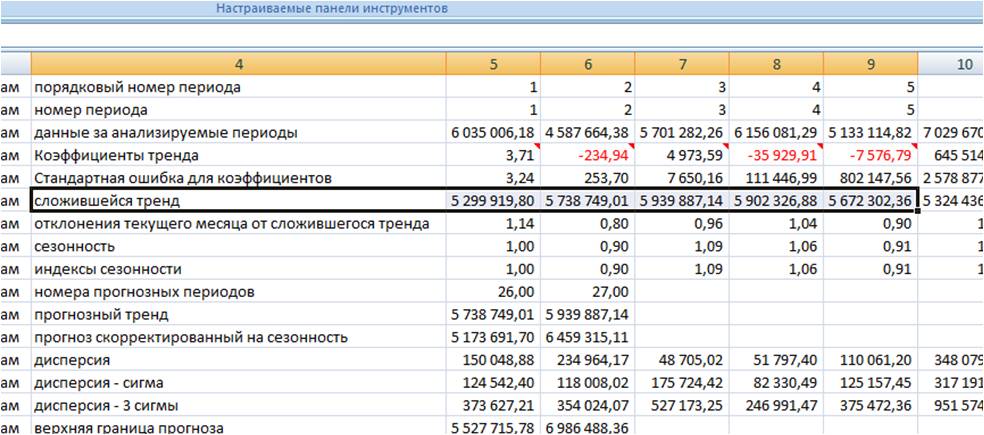
Копируем значения в наш лист.
Получаем значения полинома 6-й степени, рассчитанные 3 способами с помощью:
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

Тестируйте возможности платных решений:
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.