Uplift моделирование в пакете R
Uplift моделирование в пакете R
1. Введение в “Uplift” моделирование
Uplift моделирование – прогнозный метод машинного обучения, служащий для определения величины эффекта воздействия на потребителя. Uplift моделирование применяется при:
Uplift моделирование позволяет сегментировать потребителей, что приводит к увеличению ROI маркетинговой кампании:
Пояснить необходимость учета специфики отклика разных групп потребителей при планировании маркетинговых акций поможет следующий график:
Вероятность отклика потребителя в зависимости от участия в промо-акции
(синий – участвовал, черный – нет)
Классическим примером неудачного планирования промо-акции, без учета уже сформировавшегося желания или нежелания сделать приобретение, является следующий реальный пример:
Мы разработали модель отклика клиентов на промо-акцию и сделали рассылку каталогов по топ-30% клиентов. В результате, с учетом затрат на печать и рассылку, ROI был даже хуже, чем в контрольной группе, где мы не делали ничего.
Почему?!
Скорее всего, большая часть из этой рассылки сделала бы покупку и без участия в промо-акции (“sure thing”).
2. Методология “Uplift” моделирования
Uplift моделирование сегментирует потребителей и анализирует разницу отклика в 2-ух выборках:
С математической точки зрения “uplift” (“аплифт”) определяется как изменение вероятности совершения желаемого события (покупка, клик, возобновление подписки) в ответ на акцию:
P(Y=1| i, a=1) — P(Y=1| i, a=0)
Уже на этапе определения uplift становится понятной нетривиальность поиска решения такой задачи, т.к. uplift не может быть непосредственно измерен: клиент не может одновременно находится и в промо- и в контрольной группе.
Для решения этой задачи существует несколько подходов, которые условно можно разделить на 2 группы:
Прямые
Аплифт, как и в первом случае, вычисляется как разница между вероятностью совершения покупки данным клиентом в контрольной и промо группах.
Непрямые
После определения оптимальных подмножеств, для членов этого подмножества вычисляется аплифт как разница между вероятностью наступления благоприятного события в промо и контрольной группах.
И в том и в другом случае после анализа тестовой (пробной) промо-акции впоследствии таргетируются только группы клиентов, с макимально прогнозируемым аплифтом.
Прямые методы просты в реализации и интуитивно понятны, но, как правило, отличаются невысокой точностью. Непрямые методы являются “черными ящиками”, но отличаются более высокой точностью.
3. Примеры успешных реализаций*
Кейс 1. Telenor.
Кейс 2. Charles Schwab.
4. Исследование данных
4.1 Что такое R
R – это объектно-ориентированный, скриптовый язык статистической обработки данных. R – это де-факто стандарт статистического моделирования в академическом мире. Большинство передовых статистических алгоритмов вначале реализуются в R (Random Forest, Lasso, Ridge Regression etc), а затем мигрируют в коммерческие пакеты. Причиной популярности R являются:
140 тыс. вопросов и ответов), где можно найти ответ практически на любой вопрос.
R имеет реализованные функции для моделирования аплифт в двух пакетах:
uplift (by Leo Guelman): пакет имеет функции для генерация данных, тренировки и валидации моделей (CCIF, RF, KNN), а также функции для презентации и визуализации результатов моделирования.
Information (by Kim Larsen): пакет реализует несколько алгоритмов (Net WOE, Net IV) для выбора оптимального набора параметров при аплифт моделировании. Кроме того, пакет содержит реальную базу данных маркетинговой кампании, которая будет использоваться в данном примере.
4.2 “Базовый” аплифт
Для начала, загрузим необходимые пакеты:
Пакет Information содержит интересующие нас данные в виде двух объектов:
которые мы для начала объединим в один большой датасет:
Датасет состоит из 20’000 строчек (кейсов), с 70 численными переменными, которые описывают профайл клиентов компании. Ларсен не раскрывает смысл, стоящий за той или иной переменной (data book отсутствует), однако для нас важны 3 переменные:
Определим количество сделавших покупки в контрольной и в промо группах и назовем разницу “базовым” аплифтом. Эта величина будет являться бенчмарком, который мы будем пытаться усовершенствовать в результате моделирования:
Графическое отображение вероятности совершения покупки в контрольной и промо группах:
4.3 Является ли аплифт в 0.2% статистически значимым?
Т.к. мы имеем дело со сравнительной небольшой выборкой в 20’000 кейсов, а 20.14% и 19.95% отличаются всего лишь на 0.2%, интересно было бы ответить на вопрос:
является ли такое отличие статистически значимым? Иначе говоря, при повторном проведении промо акции, всегда ли мы гарантированно получим более высокую частоту покупок в промо группе, пусть даже на 0.2%?
Для начала, попробуем визуализировать следующий мысленный эксперимент:
сделаем из нашей тестовой выборки в 20’000 кейсов 10 случайных выборок меньшего размера (например 15’000 кейсов), и посмотрим на распределение частоты совершения покупок в контрольной и промо группах.
Для того чтобы окончательно убедиться в отсутствии статистической значимости увеличения частоты покупок в данной выборке, проведем формальный тест на разницу в частоте покупок в контрольной и промо группах:
Т.к. доверительный интервал включает в себя 0, то при текущем планировании промо-акции мы не можем исключить того, что на некоторых выборках частота покупок в контрольной группе будет выше чем в промо группе (в чем мы уже убедились на случайных выборках в начале этого раздела).
5. Моделирование
Небольшая проверка, чтобы убедиться, что структура данных сохранилась:
Для того, чтобы у нас была возможность сравнивать качество различных моделей, кросс-валидацию будем проводить на 5-ти фиксированных выборках:
Кросс валидация происходит следующим образом:
Таким образом, в конце мы имеем 10 пар средних и дисперсий для аплифта в 10 децилях (в данном случае 200 пар значений mean и sd для 10 глубин и 10 децилей)
Таким образом мы видим, что при использовании всех доступных аттрибутов:
Внимание: аплифты не аддитивны и не усредняются (см. пример расчета аплифта для нескольких децилей ниже)
Фактический аплифт на датасете, который был в “сейфе” (модель не “видела” этих данных), достаточно близок к усредненному аплифту на тренинговом датасете, и в большинстве случаев даже лучше, чем прогнозируемый аплифт.
Посмотрим цифры поближе:
Пример расчета кумулятивного аплифта для нескольких децилей
Если глядя на синие графики, полученные на тренинговых сетах, мы бы спланировали акцию в топ-3 децилях (с учетом дисперсии) при помощи модели с глубиной взаимодействия 9:
что означало бы аплифт в
50% (или, говоря простым языком, увеличение отклика клиентов на 50%)
Посмотрим, сможем ли мы улучшить результат путем сортировки аттрибутов по показателю NIV (кросс-валидация результатов показала,что оптимальным будет набор из топ 30 аттрибутов). Кросс-валидируем глубину взаимодействия на 30 топовых фичах:
Посмотрим, какой аплифт нам бы дало применение этих моделей на “боевой” выборке:
Посмотрим повнимательнее на модель, построенную на Top30 аттрибутах (отфильтрованных при помощи функции NIV из пакета Information ), глубина взаимодействия 10:
Для топ-3 децилей (которые мы бы определили исходя из поведения нашей модели на тренинговом сете, с учетом дисперсии прогнозов):
Заключение
Планирование промо-акций должно учитывать не вероятность отклика клиента (купит/не купит), а маржинальный эффект промо акции на решение индивидуума:
Наиболее оптимальным клиентом для промо акции является индиивидуум, у которого веротяность совершения покупки, вследствие участия в промо, возрастет (“persuadables”).
R, программная среда статистической обработки и анализа данных, предоставляет несколько инструментов для аплифт моделирования, которые позволяют спланировать промо акции оптимальным образом, увеличивая вероятность отклика клиента на 50 и более процентов.
Помимо увеличения процента отклика в промо акциях, аплифт моделирование используется для оптимизации и увеличения ROI маркетинговых кампаний в таких отраслях как:
Как рассчитать финансовую модель программы лояльности


Для начала нужно определиться с моделью программы лояльности, примеры которых мы будем разбирать в статье. Наша статья больше касается аналитических вопросов, поэтому мы не будем подробно останавливаться на том, как выбрать тип программы лояльности, но приведём список возможных вариантов.
Типы программ лояльности
В статье разбираем расчёты для варианта 4 из списка, в котором скидка растёт в зависимости от накопленной суммы покупок.
Собрать данные за предыдущие периоды
Программы лояльности существуют, чтобы стимулировать клиентов покупать больше. Если без программы лояльности они купили бы на 3 600 рублей, а с программой — на 4 000, компания на этом зарабатывает. Но бывает так, что программу лояльности посчитали и внедрили, но не понятно, почему люди покупают: то ли потому что они и так лояльны и готовы покупать, то ли программа лояльности действительно их стимулирует.
Поэтому в расчётах важно построить два прогноза:
Для этого нужны ретроспективные данные о продажах.
В первую очередь надо проанализировать, как идут продажи без программы лояльности — выгрузить данные и изучить их.
Особенности продаж при подготовке программы лояльности
Изучить поведение покупателей
Данные собрали и почистили. Дальше можно получить из них ценную информацию:
Для наглядности мы собрали вот такую диаграмму в Power BI. На ней видно соотношение лояльных клиентов и «одноразовых»:
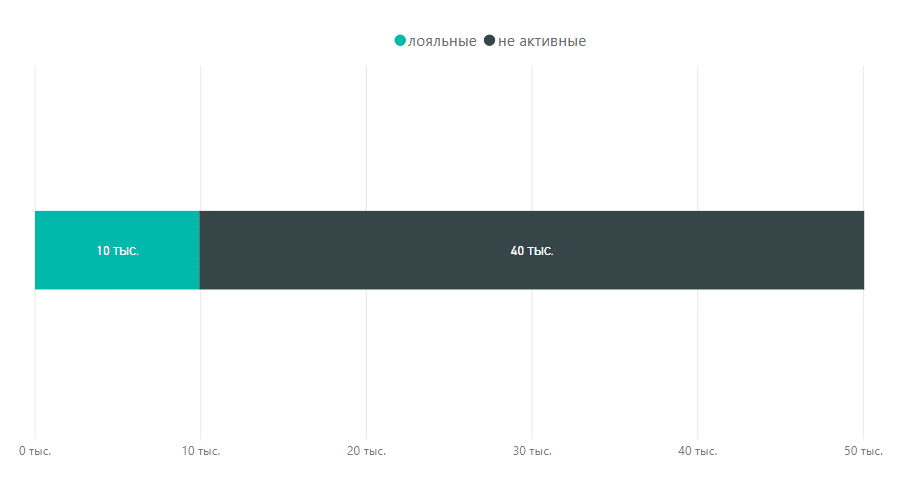
А потом более пристально рассматриваем лояльных: на какие суммы покупают, сколько раз, в какие сроки:
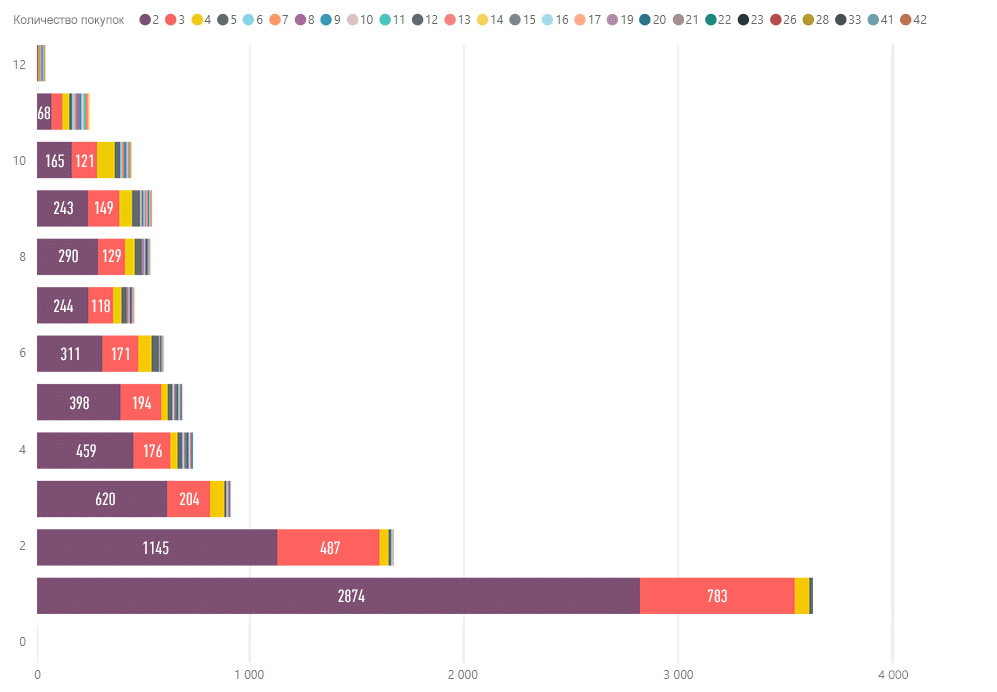
По вертикали здесь — период, за который клиенты совершали покупки. Цифры на столбце и его длина означают количество клиентов, цвет — количество покупок.
Как понимать эту диаграмму:
Суммы покупок можно было задавать отдельным фильтром:
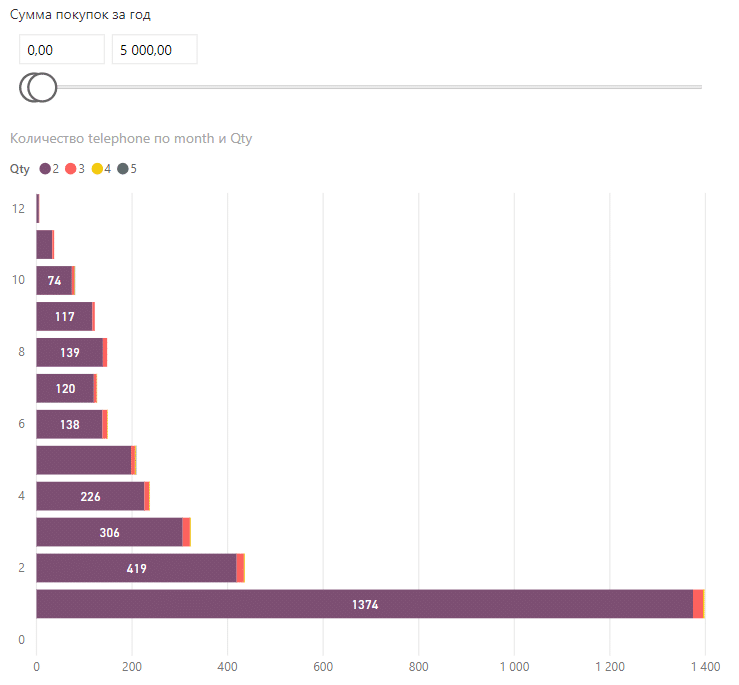
Затем эти данные перекладываем в таблицу, но об этом — позже.
Следите за эффективностью вашего маркетинга. Закажите
На основе данных построить прогноз без программы лояльности
Прогноз отвечает на вопрос «Как будут выглядеть продажи, если оставить всё как есть?» В нашем случае продажи в офлайне росли, а в онлайне падали. На тенденцию прошлого года накладываем данные о лояльных /«одноразовых» клиентах и суммах покупок и получаем прогноз на следующий год:

В этом пункте нюанс такой: нужно учитывать тенденцию прошлого периода и сезонность. Нельзя рассчитывать программу лояльности, предполагая, что продажи будут расти. Надо смотреть на реальные цифры и строить прогноз, исходя из них.
Предположить модель программы лояльности
В начале работы, когда мы ещё не знаем, какую программу выберем: какой тип, как будут начисляться скидки и при каких условиях, — надо что-то предположить, иначе считать будет нечего. В нашем примере — тип, когда скидка растёт в зависимости от суммы покупок. Для него мы предположили четыре модели начисления скидок.
Но, как мы уже говорили, нельзя исходить только из предположения, что продажи будут расти, а новые клиенты — приходить толпами. Поэтому мы предположили три варианта прироста клиентов: пессимистичный, умеренный и оптимистичный. Но, возможно, что количество новых клиентов будет зависеть от скидки. Поэтому эти прогнозы менялись в зависимости от модели начисления скидки.
Мы считали 4 модели программы лояльности в трёх вариантах (пессимистичный, умеренный, оптимистичный) отдельно для офлайна и онлайна:

Скидки: 0, 10, 15, 20%;
суммы перехода в новый статус: 0–4 999, 5 000–11 999, 12 000–24 999;
пессимистичный, умеренный и оптимистичный прогнозы: 7, 12, 15%.
Скидки: 0, 5, 10, 15%;
суммы перехода в новый статус: 0–4 999, 5 000–11 999, 12 000–24 999;
пессимистичный, умеренный и оптимистичный прогнозы: 5, 10, 13%.
Скидки: 5, 10, 15, 20%,
суммы перехода в новый статус: 0–4 999, 5 000–11 999, 12 000–24 999,
пессимистичный, умеренный и оптимистичный прогнозы: 8, 13, 16%.
Скидки: 0, 5, 10, 15%;
суммы перехода в новый статус: 0–4 999, 5 000–11 999, 12 000–19 999;
пессимистичный, умеренный и оптимистичный прогнозы: 5%, 10%, 13%.
Но примеры мы, конечно, будем приводить только для одной модели — в онлайне.
Посчитать, сколько клиентов уже находятся на предполагаемых статусах программы лояльности
У нас есть данные о клиентах и покупках и модель программы лояльности. Теперь нужно переложить данные на программу лояльности. Собираем таблицу и рассчитываем, какой процент клиентов уже находится на определённых статусах программы лояльности и как этот процент будет меняться по месяцам:
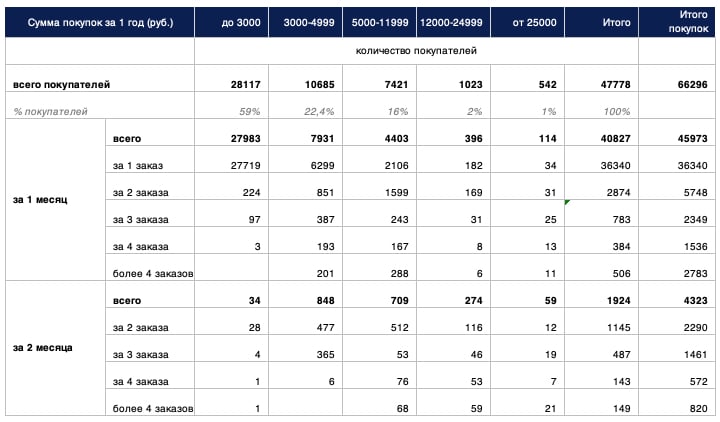
На самом деле значения в ней рассчитаны на 12 месяцев, но здесь показаны только два, чтобы не грузить вас лишней информацией. Главное, на что надо обратить внимание, — проценты клиентов в разных статусах. Статусы начинаются с 5 000 рублей, но до 3 000 мы считали тоже, потому что при покупке на 3 000 покупатель получает подарок.
Посчитать, сколько клиентов легко мотивировать на переход в новый статус
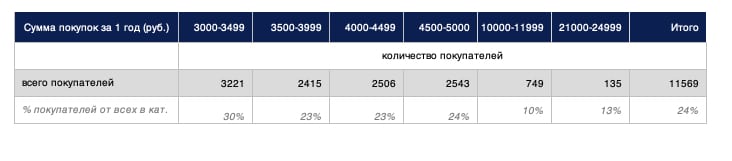
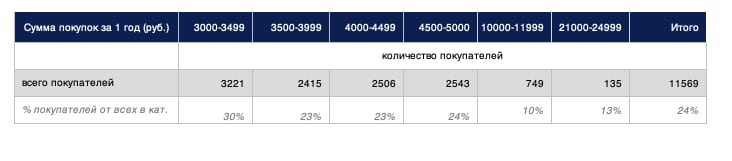
Следующий шаг — проверить, сколько клиентов находится на пограничных значениях статусов. Это те покупатели, кому нужно докупить совсем немного до подарка или перехода в новый статус. То есть, если клиент уже купил на 2 800 рублей, то допродать ему ещё что-нибудь до 3 000 будет легко — доплати всего 200 рублей и получишь подарок. Это мы и называем пограничными значениями.
Но одно дело, когда клиент купил на 700 рублей. Тогда вряд ли вы сможете убедить его купить ещё на 2 300 рублей ради подарка. Зато, если он купил на 23 000 рублей, то купить ещё на 2000 и получить скидку побольше для него не так сложно.
Поэтому для разных статусов считаем разные пограничные значения. Для первого статуса, который начинается с 5 000 рублей, пограничных значений несколько: мы определяем долю клиентов, которые находятся в диапазонах сумм 3 500–3 999 рублей, 4 000–4 499 рублей, 4 500–4 999 рублей. Для последнего статуса, начинающегося с 25 000 рублей, диапазон один — 21 000–24 999 рублей.
Спрогнозировать аплифт от программы лояльности
А здесь статья начинает напоминать фильм «Волк с Уолл-Стрит». Смотришь-смотришь, сюжет наполнен множеством событий, тебе уже кажется, что кино подходит к концу, а потом — раз — и сцена крушения вертолёта, с которой фильм начинался. И ты понимаешь, что всё это время смотрел предысторию.
Так вот — всё, что было описано до настоящего момента, было предысторией к главной цели — расчёту аплифта. То есть, того, какую прибавку к обороту даст программа лояльности.
Нюансы при расчёте аплифта
Расчёты по месяцам выглядели так:
(по клику можно посмотреть крупнее в новой вкладке) 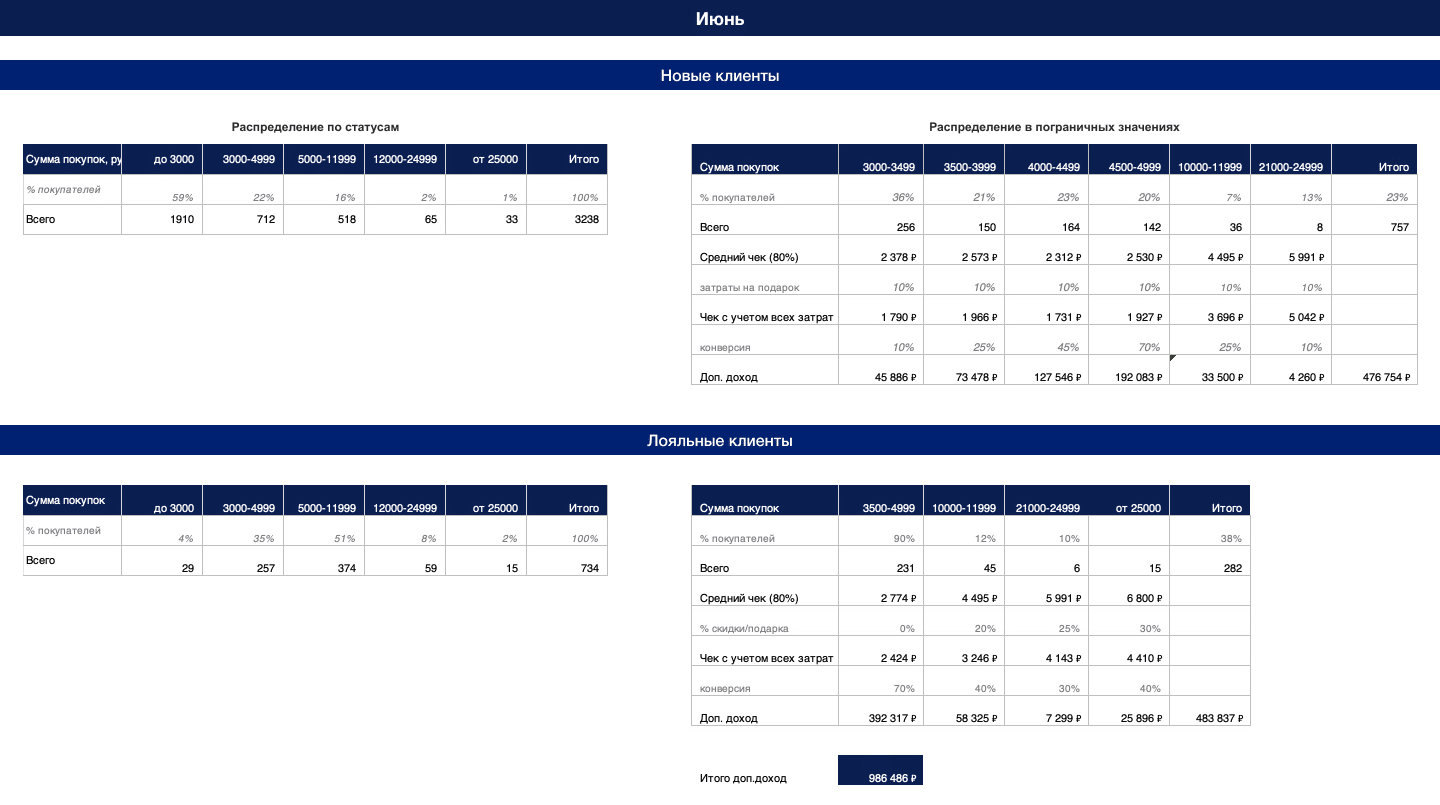
(по клику можно посмотреть крупнее в новой вкладке) 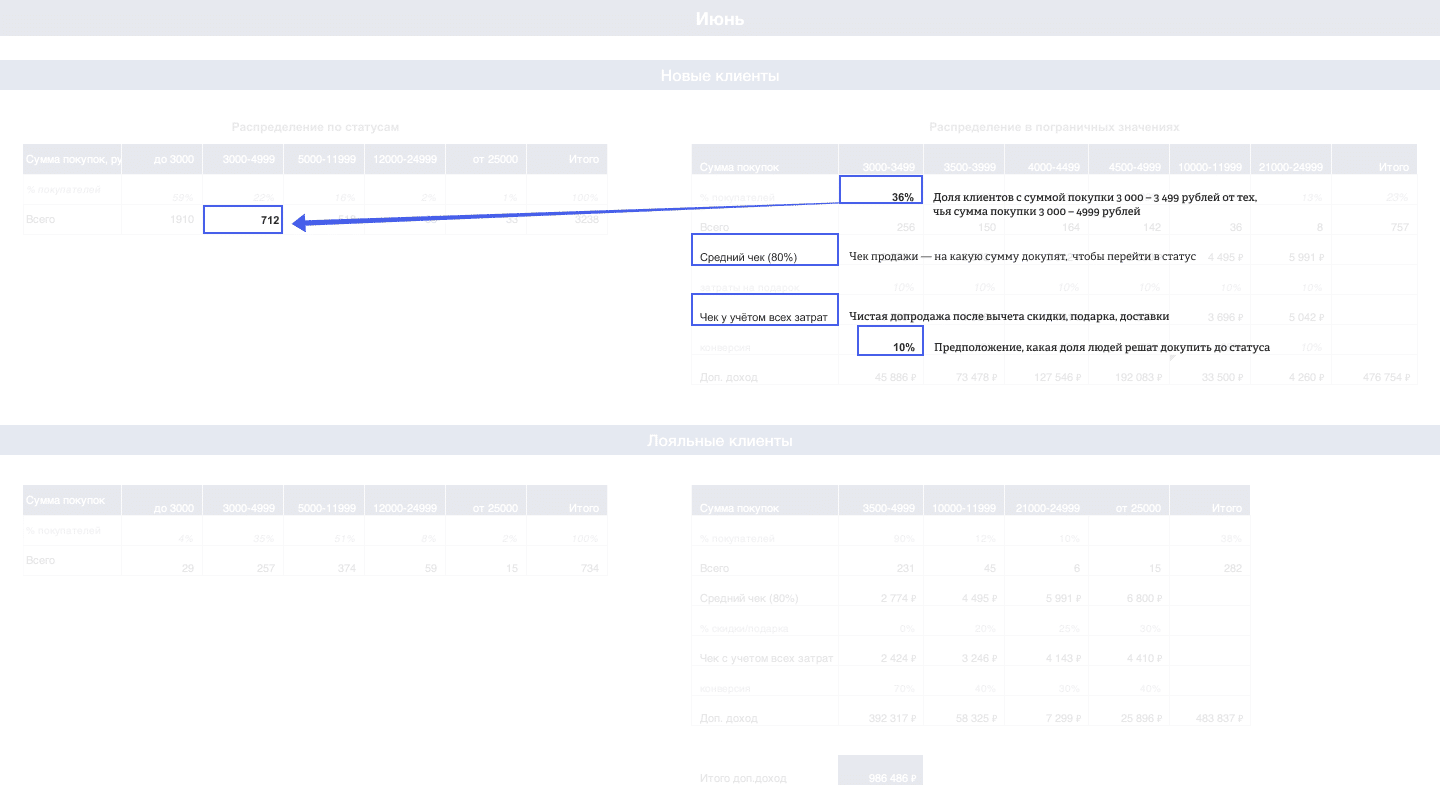
Левые таблицы вспомогательные, в них — распределение клиентов по статусам. В правых — распределение клиентов в близких к статусам значениях. В зависимости от того, к какому статусу и насколько близко они находятся, мы предполагаем разную конверсию в переход в новый статус.
Средний чек допродажи, как уже говорили, считаем за 80% от обычного среднего чека. Из него вычитаем стоимость подарка, процент скидки, а в онлайне ещё и доставку.
Количество клиентов на разных шагах близости к новому статусу умножаем на средний чек и на предполагаемую конверсию. Получаем сумму, на которую сможем допродать — аплифт.
Как мы это считали
Всё это мы рассчитывали:
Получилось 312 таблиц в экселе.
Это были расчёты по месяцам. Но чтобы выбрать оптимальную модель программы лояльности, надо собрать все данные в годовой прогноз. Так что для каждой модели ПЛ мы суммировали эти значения и составили прогноз на год в пессимистичном, умеренном и оптимистичном варианте. И сравнили с прогнозом без программы лояльности.
(по клику можно посмотреть крупнее в новой вкладке) 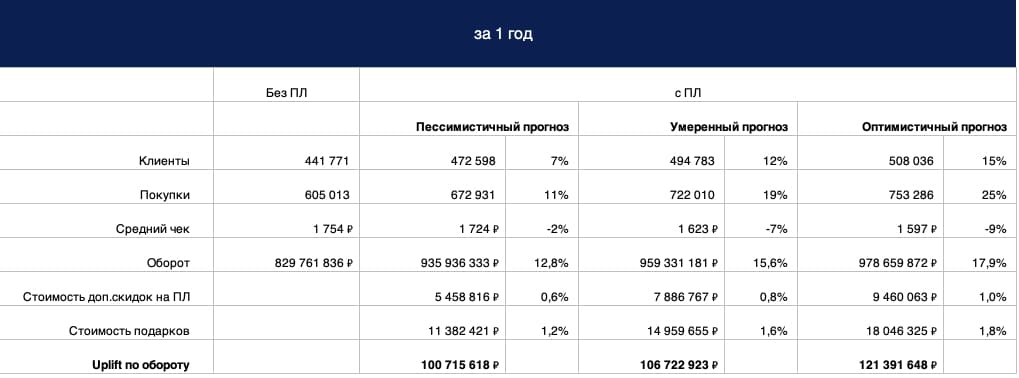
В этой таблице данные по офлайн и онлайн суммированы
Выбрать оптимальную модель
А дальше, если вы считали несколько моделей, остаётся только выбрать оптимальную: наибольший аплифт при наименьших затратах на поощрения клиентов.
В наших расчётах выигрывает вот такая:
Скидки 0%, 10%, 15%, 20%, при суммах 5 000 рублей, 12 000 рублей и 25 000 рублей.
Напутствие
Мы описали только один вариант расчёта только для одного типа программы лояльности. С другими типами будут другие сложности, но принципы везде одни и те же:
Узнавайте об обновлениях блога Email Soldiers первым
Спасибо!
Осталось подтвердить подписку — кликнуть по кнопке в письме, которое мы вам отправили.
Следите за обновлениями в соцсетях или получайте их от нашего телеграм-бота
Похожие статьи

Изучили сайты топ-100 застройщиков страны. Узнали, какие онлайн-коммуникации используются в недвижимости и что упускают застройщики, не развивая эти каналы.
Когда вся информация под рукой, гораздо проще выстраивать маркетинговые коммуникации с клиентом. Поможет CRM-система.
Создали подробные и понятные карты коммуникаций с клиентами в сфере недвижимости.
Как рассчитать финансовую модель программы лояльности
Типы программ лояльности
Собрать данные за предыдущие периоды
Программы лояльности существуют, чтобы стимулировать клиентов покупать больше. Если без программы лояльности они купили бы на 3600 рублей, а с программой — на 4000, компания на этом зарабатывает. Но бывает так, что программу лояльности посчитали и внедрили, но фиг поймёшь, почему люди покупают: то ли потому что они и так лояльные и готовы покупать, то ли программа лояльности действительно их стимулирует.
Поэтому в расчётах важно построить два прогноза:
В первую очередь надо проанализировать, как идут продажи без программы лояльности — выгрузить данные и изучить их. Здесь есть особенности.
Изучить поведение покупателей
Данные собрали и почистили. Дальше можно получить из них ценную информацию:
А потом более пристально рассматриваем лояльных: на какие суммы покупают, сколько раз, в какие сроки. 
По вертикали здесь — период, за который клиенты совершали покупки; цифры на столбцах и длина столбца означают количество клиентов, цвет — количество покупок.
Как понимать эту диаграмму:
В будущем эти данные переложили в таблицу, но об этом позже.
На основе данных построить прогноз без программы лояльности
Прогноз отвечает на вопрос, как будут выглядеть продажи, если оставить, всё как есть. В нашем случае, продажи в офлайне росли, а в онлайне падали. На тенденцию прошлого года накладываем данные о лояльных / «одноразовых» клиентах и суммах покупок и получаем прогноз на следующий год:

В этом пункте нюанс такой: нужно учитывать тенденцию прошлого периода и сезонность. Нельзя рассчитывать программу лояльности, предполагая, что продажи будут расти. Надо смотреть на реальные цифры и строить прогноз, исходя из них.
Предположить модель программы лояльности
В начале работы, когда мы ещё не знаем, какую программу выберем: какой тип, как будут начисляться скидки и при каких условиях, — надо что-то предположить, иначе считать будет нечего. В нашем примере — тип, когда скидка растёт в зависимости от суммы покупок. Для него мы предположили четыре модели начисления скидок.
Но, как мы уже говорили, нельзя исходить только из предположения, что продажи будут расти, а новые клиенты — приходить толпами. Поэтому мы предположили три варианта прироста количества клиентов: пессимистичный, умеренный и оптимистичный. Но, возможно, что количество новых клиентов будет зависеть от скидки. Поэтому эти прогнозы менялись в зависимости от модели начисления скидки.
Мы считали 4 модели программы лояльности в трёх вариантах (пессимистичный, умеренный, оптимистичный) отдельно для офлайна и онлайна:
Но примеры мы, конечно, будем приводить только для одной модели, в онлайне.
Посчитать, сколько клиентов уже находятся на предполагаемых статусах программы лояльности
У нас есть данные о клиентах и покупках, у нас есть модель программы лояльности. Теперь нужно переложить данные на программу лояльности. Собираем таблицу и рассчитываем, какой процент клиентов на каких статусах программы лояльности уже находится и как этот процент будет меняться по месяцам:

На самом деле значения в ней рассчитаны на 12 месяцев, но здесь показаны только два, чтобы не грузить вас лишней информацией. Главное, на что надо обратить внимание, — проценты клиентов в разных статусах. Статусы начинаются с 5000 рублей, но до 3000 мы считали тоже, потому что при покупке на 3000 покупатель получает подарок.
Посчитать, сколько клиентов легко мотивировать на переход в новый статус
Следующий шаг — проверить, сколько клиентов находится в пограничных значениях статусов. Это те покупатели, кому нужно докупить совсем немного до подарка или перехода в новый статус. То есть, если клиент уже купил на 2800 рублей, то допродать ему ещё что-нибудь до 3000 будет легко — доплати всего 200 рублей и получишь подарок. Это мы и называем пограничными значениями.
Но одно дело, когда клиент купил на 700 рублей. Тогда вряд ли вы сможете убедить его купить ещё на 2300 рублей ради подарка. Зато если он купил на 23 000 рублей, то купить ещё на 2000 и получить скидку побольше для него не так сложно.
Поэтому для разных статусов считаем разные пограничные значения. Для первого статуса, который начинается с 5000 рублей, пограничных значений несколько: мы находим долю клиентов, которые находятся в диапазонах сумм 3500–3999 рублей, 4000–4499 рублей, 4500–4999 рублей. Для последнего статуса, начинающегося с 25 000 рублей, диапазон один — 21000–24999 рублей.
Спрогнозировать аплифт от программы лояльности
А здесь статья начинает напоминать фильм «Волк с Уолл-Стрит». Смотришь-смотришь, сюжет наполнен множеством событий, тебе уже кажется, что кино подходит к концу, а потом — раз — и сцена крушения вертолёта, с которой фильм начинался. И ты понимаешь, что всё это время смотрел предысторию.
Так вот, всё, что было описано до настоящего момента, было предысторией к главной цели — расчёту аплифта. То есть, какую прибавку к обороту даст программа лояльности.
Нюансы при расчёте аплифта
Левые таблицы вспомогательные, в них — распределение клиентов по статусам. В правых — распределение клиентов в близких к статусам значениях. В зависимости от того, к какому статусу и насколько близко они находятся, мы предполагаем разную конверсию в переход в новый статус.
Средний чек допродажи, как уже говорили, считаем за 80% от обычного среднего чека. Из него вычитаем стоимость подарка, процент скидки, а в онлайне ещё и доставку.
Количество клиентов на разных шагах близости к новому статусу умножаем на средний чек и на предполагаемую конверсию. Получаем, на какую сумму сможем допродать — аплифт.
Всё это мы рассчитывали:
Это были расчёты по месяцам, но, чтобы выбрать оптимальную модель программы лояльности, надо собрать все данные в годовой прогноз. Так что для каждой модели ПЛ мы суммировали эти значения и составили прогноз на год в пессимистическом, умеренном и оптимистическом варианте. И сравнили с прогнозом без программы лояльности.
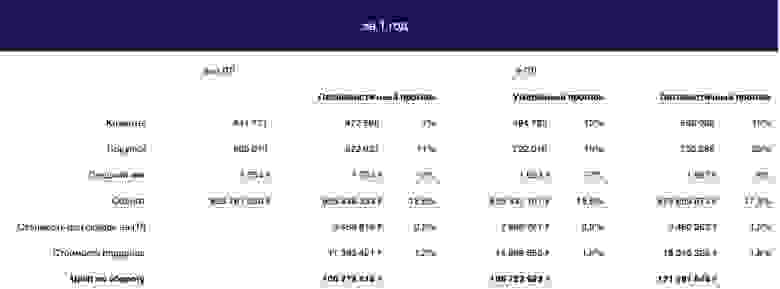
В этой таблице данные по офлайн и онлайн суммированы.
Выбрать оптимальную модель
А дальше, если вы считали несколько моделей, остаётся только выбрать оптимальную: наибольший аплифт при наименьших затратах на поощрения клиентов.
В наших расчётах выигрывает вот такая:
Скидки 0%, 10%, 15%, 20%, при суммах 5000 рублей, 12000 рублей и 25000 рублей.
Напутствие
Мы описали только один вариант расчёта только для одного типа программы лояльности. С другими типами будут другие сложности, но принципы везде одни и те же: